Apache Kafka is an open-source event streaming platform that enables organizations to build real-time data streams and store data. It was developed at LinkedIn in 2011 and subsequently made available as open source. Since then, the use of Kafka as an event streaming solution has become widespread.
How is Kafka structured?
Apache Kafka is built as a computer cluster consisting of servers and clients.
The servers, or so-called brokers, write data with timestamps into the topics, which creates the data streams. In a cluster, there can be different topics, which can be separated by the topic reference. In a company, for example, there could be a topic with data from production and again a topic for data from sales. The so-called broker stores these messages and can also distribute them in the cluster to share the load more evenly.
The writing system in the Kafka environment is called the producer. As a counterpart, there are the so-called consumers, which read the data streams and process the data, for example by storing them. When reading, there is a special feature that distinguishes Kafka: The consumer does not have to read the messages all the time, but can also be called only at certain times. The intervals depend on the data timeliness required by the application.
To ensure that the consumer reads all messages, the messages are “numbered” with the so-called offset, i.e. an integer that starts with the first message and ends with the most recent. When we set up a consumer, it “subscribes” to the topic and remembers the earliest available offset. After it has processed a message, it remembers which message offsets it has already read and can pick up exactly where it left off the next time it is started.
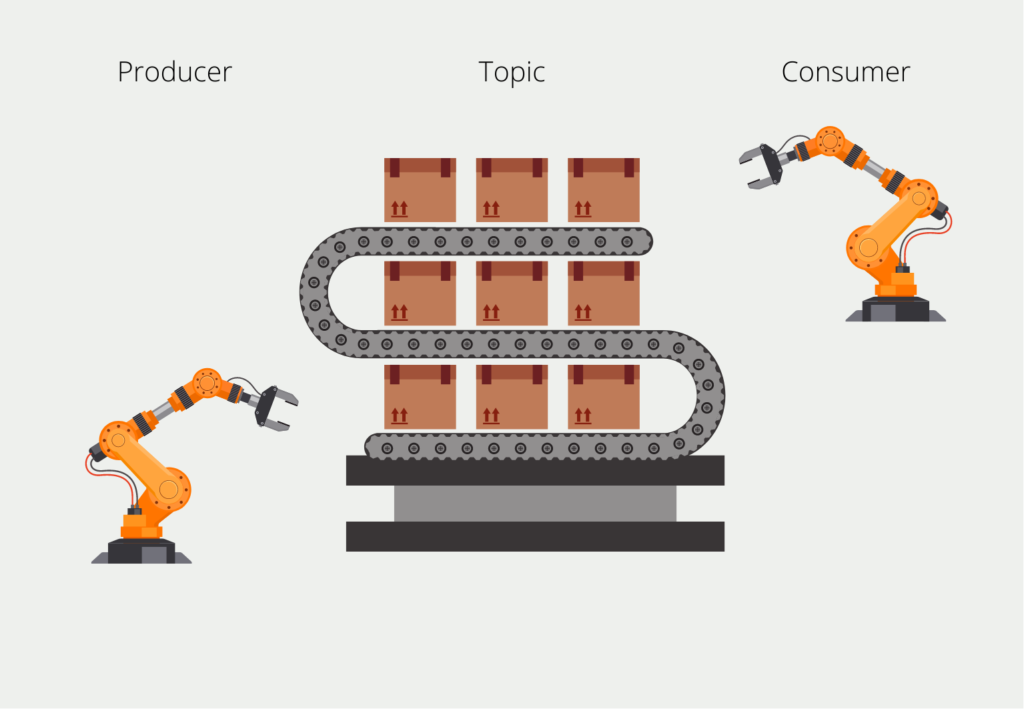
This allows, for example, a functionality in which we let the consumer run every full hour for ten minutes. Then it registers that ten messages have not yet been processed and it reads these ten messages and sets its offset equal to that of the last message. In the following hour, the consumer can then determine again how many new messages have been added and process them one after the other.
A topic can also be divided into so-called partitions, which can be used to parallelize processing because the partitions are stored on different computers. This also allows several people to access a topic at the same time and the total storage space for a topic can be scaled more easily.
What APIs are used?
Apache Kafka provides several APIs that allow developers to interact with the Kafka messaging system. These APIs allow users to generate and consume messages from Kafka topics, manage consumer groups, and monitor Kafka clusters.
Here are the main Kafka APIs:
- Producer API: This API allows developers to publish messages to Kafka themes. With this API, users can send messages to Kafka brokers and specify the topic and partition to which the message should be sent.
- Consumer API: This interface allows developers to read messages from Kafka topics. With this API, users can subscribe to Kafka topics and receive messages from Kafka brokers.
- Streams API: This API allows users to process and analyze data in real time by converting Kafka topics into streams. This API is useful for building real-time data pipelines and stream processing applications.
- Connect API: This API is used to integrate Kafka with external systems such as databases, message queues, and file systems. It provides connectors that can be used to import or export data from Kafka themes.
- Admin API: This API is used to manage Kafka clusters and themes. With this API, users can create, delete, and modify Kafka themes and also manage Kafka brokers, consumer groups, and ACLs.
Overall, the Kafka APIs provide a flexible and powerful way to interact with the Kafka messaging system and create robust, scalable, and ec
What are the capabilities of Apache Kafka?
Apache Kafka offers two different types of topics, namely “Normal” and “Compacted ” topics. Normal topics have a maximum memory size and sometimes also a certain amount of time in which data is stored. When the memory limit is reached, the oldest events, i.e. those with the smallest offset, are deleted to make room for new events.
This is different from the Compacted Topics. These have neither a time nor a memory limitation. They are therefore similar to a database in that the data is retained. Because of these Compact Topics, some companies, such as Uber, are already using Kafka as a data lake. The complete data stream can also be queried using SQL via the additional KSQL functionality.
What tools can you combine Apache Kafka with?
Apache Kafka is a powerful distributed streaming platform that can be used to process large amounts of data in real time. It can also be integrated with various other technologies and tools to provide an end-to-end solution for data processing and analysis. Here are some of the most popular tools and technologies that can be used with Kafka:
- Apache Spark: Apache Kafka can integrate with Apache Spark to create a powerful streaming analytics platform. Spark can read data from the stream, perform data transformations, and write the results back to Kafka for further processing or storage.
- Hadoop: It can integrate with Hadoop to create a scalable data processing pipeline. Kafka can serve as a data source for Hadoop jobs, and Hadoop can write the results back to Kafka for further processing or storage.
- Cassandra: Kafka can integrate with Apache Cassandra to create a scalable real-time data processing platform. Kafka can serve as a data source for Cassandra, and Cassandra can store the results for further analysis.
- Elasticsearch: The streaming tool can be integrated with Elasticsearch to create a scalable real-time search platform. Kafka can serve as a data source for Elasticsearch, and Elasticsearch can index the data for rapid search and query.
- Flume: Kafka can integrate with Apache Flume to create a scalable data collection and input pipeline. Flume can read data from various sources and write it to Kafka for further processing or storage.
- Storm: Kafka can integrate with Apache Storm to create a real-time distributed data processing platform. Storm can read data from Kafka, perform data transformations, and write the results back to Kafka for further processing or storage.
- Flink: Kafka can integrate with Apache Flink to create a scalable, fault-tolerant data processing platform. Flink can read data from Kafka, perform data transformations, and write the results back to Kafka for further processing or storage.
Overall, the ability to integrate with various tools and technologies makes Kafka a versatile and powerful platform for processing data.
What applications can be implemented with Kafka?
Kafka is used to building and analyze real-time data streams. Thus, it can be used to implement applications where data timeliness plays an immense role. These include, among others:
- Production line monitoring
- Analysis of website tracking data in real-time
- Merging data from different sources
- Change data capturing from databases to detect changes
In addition, machine learning is also increasingly becoming the focus of Apache Kafka applications. An e-commerce website runs many ML models whose results must be available in real-time. For example, these websites have a recommendation function that suggests suitable products to the customer based on his or her previous journey.
Thus, the model needs the previous events in real time to start a calculation. The website, in turn, needs the result of the model as quickly as possible in order to display the found products to the customer. For these two data streams, the use of Apache Kafka lends itself.
What are the benefits of using Apache Kafka?
Kafka’s widespread popularity is due in part to these advantages:
- Scalability: Due to the architecture with topics and partitions, Kafka is horizontally scalable in many aspects such as storage space or performance.
- Possibility of data storage: The use of Compacted Streams offers the possibility to store data permanently.
- Ease of use: The concept of producers and consumers is easy to understand and implement.
- Fast processing: In real-time applications, not only the fast transport of data is of great importance, but also fast processing. Apache Kafka offers the so-called Streaming API an easy way to process real-time data.
This is what you should take with you
- Apache Kafka is an open-source event streaming platform that enables companies to build real-time data streams and store the data.
- In short, producers write their data into so-called topics, which can be read by consumers.
- In Topics, the oldest data is deleted once a certain amount of storage has been reached. With Compacted Topics, the information is never deleted. Therefore, they are suitable for long-term data storage.
- Apache Kafka is popular among users mainly because of its ease of use and scalability.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of Apache Kafka

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.