Ein Data Lakehouse ist eine Datenverwaltungstechnik, die den Data Lake und das Data Warehouse kombiniert, indem sie einen einzigen Punkt der Wahrheit hat, ohne dass im Voraus ein Datenschema festgelegt werden muss. Es bietet die Grundlage für Business Intelligence und senkt die Kosten, da kein Datenschema definiert ist und somit kostengünstigere Datenspeicher verwendet werden können.
Warum sind Daten für Unternehmen so wichtig?
Daten sind zu einer entscheidenden Komponente für Unternehmen in verschiedenen Branchen geworden. Unternehmen müssen ihre Daten effizient speichern, verwalten und analysieren, um fundierte Entscheidungen zu treffen, die ihre Abläufe verbessern und letztlich den Umsatz steigern können. Aus diesem Grund haben sich Unternehmen bisher auf zwei primäre Datenspeicherlösungen verlassen: Data Lake und Data Warehouse. Mit dem Aufkommen von Data Lakehouse können Unternehmen nun jedoch die Vorteile von Data Lake und Data Warehouse in einer einzigen Lösung nutzen. In diesem Artikel werden wir erörtern, was Data Lakehouse ist, wie es sich von einem Data Lake und Data Warehouse unterscheidet und welche Vorteile es bietet.
Was ist ein Data Lakehouse?
Ein Data Lakehouse ist eine hybride Architektur zur Datenspeicherung und -verarbeitung, die das Beste aus einem Data Lake und einem Data Warehouse vereint. Es handelt sich um eine einheitliche Datenplattform, die Datenspeicherung, -verarbeitung und -analyse integriert und Unternehmen eine einzige Quelle der Wahrheit für alle ihre Datenanforderungen bietet.
Im Gegensatz zu herkömmlichen Data-Warehouse-Lösungen, die auf einem Schema-on-write-Ansatz basieren, verwenden Data Lakehouses einen Schema-on-read-Ansatz. Dies bedeutet, dass die Daten in ihrer Rohform gespeichert werden und das Schema zum Zeitpunkt der Abfrageausführung angewendet wird. Dieser Ansatz bietet Unternehmen mehr Flexibilität, Skalierbarkeit und Agilität bei der Verarbeitung und Analyse großer Datenmengen.
Welche Probleme werden durch ein Data Lakehouse gelöst?
Data Lakehouses lösen eine Reihe von Problemen, die Unternehmen bei der Verwaltung und Verarbeitung großer Datenmengen haben. Einige der häufigsten Probleme, die damit gelöst werden können, sind:
- Datensilos: Viele Unternehmen haben Daten in verschiedenen Systemen und Formaten gespeichert, was zu Datensilos führt. Data Lakehouses bieten ein zentrales Repository, in dem Unternehmen alle ihre Daten in ihrer Rohform speichern können, wodurch Datensilos beseitigt werden.
- Begrenzte Skalierbarkeit: Herkömmliche Data Warehouses sind nur begrenzt skalierbar, so dass es schwierig ist, große Datenmengen zu verarbeiten. Data Lakehouses bieten Unternehmen die Flexibilität, ihre Abläufe nach Bedarf zu skalieren, so dass sie große Datenmengen ohne Leistungseinbußen verarbeiten können.
- Komplexes Datenmanagement: Data Warehouses erfordern oft umfangreiche ETL-Prozesse (Extrahieren, Transformieren, Laden), um Daten zu transformieren und in das Warehouse zu laden. Dieser Prozess kann komplex und zeitaufwändig sein, was eine effektive Datenverwaltung erschwert. Data Lakehouses machen umfangreiche ETL-Prozesse überflüssig und ermöglichen es Unternehmen, ihre Daten effektiver zu verwalten.
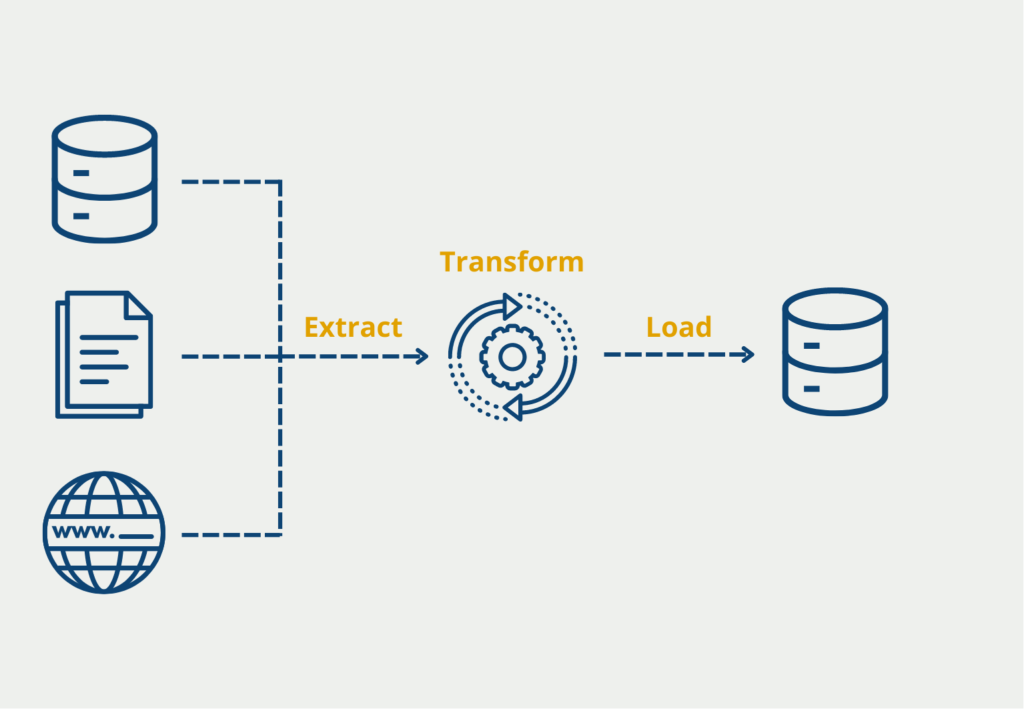
- Langsame Abfrageleistung: Herkömmliche Data Warehouses basieren auf einem Schema-on-write-Ansatz, der zu einer langsamen Abfrageleistung führen kann. Data Lakehouses verwenden einen Schema-on-read-Ansatz, der es Unternehmen ermöglicht, Daten ohne Leistungseinbußen zu analysieren.
- Begrenzte Analysefunktionen: Herkömmliche Data Warehouses sind in erster Linie für die Speicherung von Daten konzipiert und verfügen oft nur über begrenzte Analysefunktionen. Sie bieten Unternehmen fortschrittliche Analysefunktionen, mit denen sie schnell Erkenntnisse aus ihren Daten ableiten und fundierte Entscheidungen treffen können.
- Probleme mit der Datenqualität: Angesichts der zunehmenden Datenmenge und -vielfalt ist die Sicherstellung der Datenqualität zu einer Herausforderung für Unternehmen geworden. Data Lakehouses bieten Unternehmen Tools und Prozesse zur Überwachung und Sicherstellung der Datenqualität, so dass sie ihren Daten vertrauen und datengestützte Entscheidungen mit Zuversicht treffen können.
Wie können Daten in einem Data Lakehouse gespeichert werden?
Data Lakes und Data Warehouses sind schon lange die bevorzugten Lösungen zur Speicherung und Verwaltung von Daten in der Welt der Analytik und Business Intelligence. Da Datenquellen jedoch zunehmend vielfältig und komplex geworden sind, hat sich ein neues Konzept entwickelt: das Data Lakehouse. Diese Architektur kombiniert das Beste aus beiden Welten und bietet eine leistungsstarke Möglichkeit zur Sammlung, Speicherung und Analyse von Daten. Bevor wir jedoch in die Details eintauchen, lassen uns erkunden, was Datenübernahme ist und welche Überlegungen Einsteiger beachten sollten, wenn sie Daten für ein Data Lakehouse sammeln.
Datenübernahme ist der Prozess der Sammlung, des Imports und der Verarbeitung von Daten aus verschiedenen Quellen und deren Bereitstellung zur Analyse in einem zentralen Repository. Im Kontext eines Data Lakehouse ist dieses Repository ein vereinheitlichtes Speichersystem, das die Flexibilität eines Datensees mit der Abfrageleistung und Struktur eines Datenwarenhauses kombiniert.
Datenquellen:
- Identifiziere Datenquellen: Beginne damit, die Quellen von Daten in deiner Organisation zu identifizieren. Dazu können Datenbanken, Cloud-Speicher, Streaming-Plattformen, IoT-Geräte, externe APIs und mehr gehören.
- Verstehe Datentypen: Unterschiedliche Quellen erzeugen Daten in verschiedenen Formaten, wie strukturiert (relationale Datenbanken), halbstrukturiert (JSON, XML) oder unstrukturiert (Textdokumente, Bilder). Das Verständnis der Datentypen, mit denen du arbeitest, ist entscheidend.
Datenqualität:
- Datenbereinigung: Bevor du Daten in dein Lakehouse übernimmst, ist es wichtig, sie zu bereinigen und vorzuverarbeiten. Dies umfasst das Bearbeiten von fehlenden Werten, das Entfernen von Duplikaten und das Beheben von Dateninkonsistenzen.
- Datenvalidierung: Implementiere Validierungsprüfungen, um die Datenintegrität sicherzustellen. Dies kann die Überprüfung von Daten anhand vordefinierter Regeln oder Einschränkungen beinhalten.
Datenverarbeitung:
- Schemaevolution: Datenquellen können sich im Laufe der Zeit ändern. Überlege, wie dein Lakehouse mit Schemaänderungen und Versionierung umgeht, um die Kompatibilität mit vorhandenen Daten sicherzustellen.
- ETL (Extrahieren, Transformieren, Laden): Entwickle ETL-Pipelines, um Daten in ein für die Analyse geeignetes Format zu transformieren. Dies kann die Aggregierung von Daten, die Anreicherung mit zusätzlichen Informationen oder die Durchführung von Berechnungen umfassen.
Datensicherheit und Compliance:
- Zugriffskontrolle: Lege Zugriffssteuerungen und Berechtigungen fest, um zu beschränken, wer auf Daten im Lakehouse zugreifen und sie bearbeiten kann. Dies ist entscheidend für die Datensicherheit.
- Compliance-Vorschriften: Achte auf eventuelle regulatorische Compliance-Anforderungen (z.B. DSGVO, HIPAA), die auf deine Daten zutreffen. Stelle sicher, dass deine Datenverarbeitungsprozesse konform sind.
Datenkatalog und Metadaten:
- Datenkatalogisierung: Pflege einen Datenkatalog, der Metadateninformationen über die übernommenen Daten bereitstellt. Dies erleichtert es Benutzern, verfügbare Datenressourcen zu entdecken und zu verstehen.
- Metadatenverwaltung: Setze Praktiken zur Metadatenverwaltung ein, um den Datenverlauf, die Versionierung und die Verwendung zu verfolgen.
Skalierbarkeit und Leistung:
- Skalierbarkeit: Überlege, wie deine Datenübernahme-Prozesse mit zunehmender Datenmenge skalieren können. Cloud-basierte Lösungen bieten oft die Elastizität, um sich an wechselnde Workloads anzupassen.
- Leistungsoptimierung: Stimme die Leistung deines Data Lakehouse ab, indem du Indizierung, Partitionierung und Optimierung von Abfragen durchführst, um schnelle und effiziente Datenabfragen sicherzustellen.
Überwachung und Protokollierung:
- Überwachungstools: Richte Überwachungstools ein, um die Gesundheit und Leistung deiner Datenübernahme-Prozesse zu verfolgen. Dies umfasst Fehlerüberwachung, Latenzverfolgung und die Nutzung von Ressourcen.
- Protokollierung: Halte detaillierte Protokolle über die Aktivitäten der Datenübernahme für Prüfungszwecke, Fehlerbehebung und historische Analysen aufrecht.
Datenverwaltung:
- Datenverlauf: Etabliere einen Datenverlauf, um nachzuverfolgen, wie Daten in deiner Organisation bewegt werden. Dies hilft bei der Aufrechterhaltung der Datenqualität und -compliance.
- Datenverantwortung: Benenne Datenverantwortliche, die für die Sicherung der Datenqualität, -sicherheit und -compliance innerhalb deines Lakehouses verantwortlich sind.
Denke daran, dass die Datenübernahme nur der erste Schritt in der Reise der Datennutzung innerhalb eines Data Lakehouses ist. Durchdachte Praktiken zur Datenübernahme legen den Grundstein für effektive Datenanalyse, Berichterstellung und Entscheidungsfindung. Indem du diese Überlegungen berücksichtigst, kannst du als Einsteiger deine Reise mit einem starken Fundament für den Erfolg im Data Lakehouse beginnen.
Data Lakehouse vs. Data Lake
Data Lakehouses und Data Lakes haben zwar einige Gemeinsamkeiten, unterscheiden sich aber grundlegend in ihrem Ansatz für die Datenverwaltung. Ein Data Lake ist ein zentrales Repository, in dem strukturierte, halbstrukturierte und unstrukturierte Daten in ihrer Rohform gespeichert werden. Die Daten werden nicht verarbeitet oder umgewandelt, und es gibt kein definiertes Schema oder eine Struktur. Dieser Ansatz bietet Unternehmen die Flexibilität, Daten aus verschiedenen Quellen und Formaten zu speichern, aber es kann schwierig sein, die Daten zu analysieren und Erkenntnisse daraus abzuleiten.
Im Gegensatz dazu bieten Data Lakehouses den Unternehmen die Vorteile eines Data Lakes, wie Flexibilität und Skalierbarkeit, und gleichzeitig die Struktur und Organisation eines Data Warehouse. Data Lakehouses speichern Daten in ihrer Rohform, setzen aber auch einen Schema-on-Read-Ansatz durch, der es den Unternehmen erleichtert, ihre Daten zu analysieren und Erkenntnisse daraus abzuleiten.
Data Lakehouse vs. Data Warehouse
Data Warehouse-Lösungen gibt es schon seit langem, und sie sind die bevorzugte Lösung für Unternehmen, die ihre Daten speichern und analysieren müssen. Data Warehouses haben jedoch einige Einschränkungen. Sie basieren auf einem Schema-on-Write-Ansatz, d. h. die Daten müssen transformiert und in das Data Warehouse geladen werden, bevor sie analysiert werden können. Dieser Ansatz kann zeitaufwändig und schwierig zu skalieren sein.
Im Gegensatz dazu bieten Data Lakehouses den Unternehmen die Vorteile eines Data Warehouse, wie Struktur und Organisation, und gleichzeitig die Flexibilität und Skalierbarkeit eines Data Lake. Data Lakehouses speichern Daten in ihrer Rohform und das Schema wird zum Zeitpunkt der Abfrageausführung angewendet. Dieser Ansatz gibt Unternehmen die Möglichkeit, große Datenmengen in Echtzeit zu verarbeiten und zu analysieren, was die Gewinnung von Erkenntnissen und das Treffen fundierter Entscheidungen erleichtert.
Was sind die Vorteile eines Data Lakehouse?
In der Praxis kombiniert das Lakehouse-Konzept die Vorteile von Data Warehouse und Data Lake und ermöglicht Unternehmen ein effizientes Datenmanagement. Zu den am häufigsten genannten Vorteilen gehören:
Flexibilität und Skalierbarkeit
Data Lakehouses bieten Unternehmen die Flexibilität und Skalierbarkeit eines Data Lakes und ermöglichen es ihnen, Daten aus verschiedenen Quellen und Formaten zu speichern und auszuwerten. Diese Flexibilität und Skalierbarkeit ermöglicht es Unternehmen, ihre Abläufe zu skalieren und große Datenmengen zu verarbeiten, ohne die Leistung zu beeinträchtigen.
Analysen in Echtzeit
Data Lakehouses ermöglichen es Unternehmen, Daten in Echtzeit zu analysieren und so schnell fundierte Entscheidungen zu treffen. Mit Echtzeit-Analysen können Unternehmen Trends, Muster und Anomalien erkennen, sobald sie auftreten, und so proaktive Maßnahmen ergreifen und datengestützte Entscheidungen treffen.
Kosteneffizient
Data Lakehouses sind kosteneffiziente Lösungen, da sie es Unternehmen ermöglichen, Daten in ihrer Rohform ohne teure ETL-Prozesse zu speichern. Unternehmen können alle ihre Daten in einem zentralen Repository speichern, wodurch der Bedarf an mehreren Datenspeichern reduziert wird.
Das solltest Du mitnehmen
- Das Data Lakehouse kombiniert die Vorteile von Data Lakes und Data Warehouses und bietet eine einheitliche Plattform für die Speicherung, Verarbeitung und Analyse großer Datenmengen.
- Im Gegensatz zu herkömmlichen Data Warehouses ermöglicht das Lakehouse ein flexibles Schema-Management, so dass Unternehmen strukturierte, halbstrukturierte und unstrukturierte Daten speichern können.
- Durch den Einsatz moderner Big-Data-Technologien wie Apache Spark und Delta Lake bietet das Lakehouse-Konzept schnellere und effizientere Datenverarbeitungs- und Abfragefunktionen.
- Durch die Nutzung der Vorteile der Cloud bietet es eine skalierbare und kosteneffiziente Datenspeicherung und -verarbeitung und macht eine kostspielige Infrastruktur vor Ort überflüssig.
- Insgesamt stellt das Data Lakehouse eine vielversprechende Lösung für Unternehmen dar, die die Möglichkeiten von Big Data nutzen möchten, um Innovationen voranzutreiben und einen Wettbewerbsvorteil in der heutigen datengesteuerten Unternehmenslandschaft zu erlangen.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Data Lakehouse
Microsoft bietet einen interessanten Artikel zu diesem Thema.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.