A Data Lakehouse is a data management technique that combines the Data Lake and the Data Warehouse by having a single point of truth without needing a data schema in advance. It provides the basis for Business Intelligence and reduces costs since no data schema is defined which enables the usage of cheaper data storage.
Why is data important for businesses?
Data has become a critical component for businesses across various industries. Companies need to store, manage, and analyze their data efficiently to make informed decisions that can improve their operations and ultimately drive revenue. As a result, businesses have been relying on two primary data storage solutions: data lake and data warehouse. However, with the rise of Data Lakehouse, businesses can now enjoy the benefits of both data lake and data warehouse in a single solution. In this article, we will discuss what is Data Lakehouse, how it differs from a data lake and data warehouse, and the benefits it offers.
What is Data Lakehouse?
A Data Lakehouse is a hybrid data storage and processing architecture that combines the best of both a data lake and a data warehouse. It is a unified data platform that integrates data storage, processing, and analytics, providing businesses with a single source of truth for all their data needs.
Unlike traditional data warehouse solutions that rely on a schema-on-write approach, Data Lakehouses use a schema-on-read approach. This means that data is stored in its raw form, and the schema is applied at the time of query execution. This approach gives businesses greater flexibility, scalability, and agility to process and analyze large volumes of data.
Which problems are solved by a Data Lakehouse?
Data Lakehouses solve a range of problems that businesses face in managing and processing large volumes of data. Some of the common problems that it solves are:
- Data silos: Many businesses have data stored in multiple systems and formats, leading to data silos. Data Lakehouses provide a centralized repository where businesses can store all their data in its raw form, eliminating data silos.
- Limited scalability: Traditional data warehouses have limited scalability, making it challenging to handle large volumes of data. Data Lakehouses provide businesses with the flexibility to scale their operations as needed, enabling them to handle large volumes of data without compromising performance.
- Complex data management: Data warehouses often require extensive ETL (extract, transform, load) processes to transform and load data into the warehouse. This process can be complex and time-consuming, making it challenging to manage data effectively. Data Lakehouses eliminate the need for extensive ETL processes, enabling businesses to manage their data more effectively.
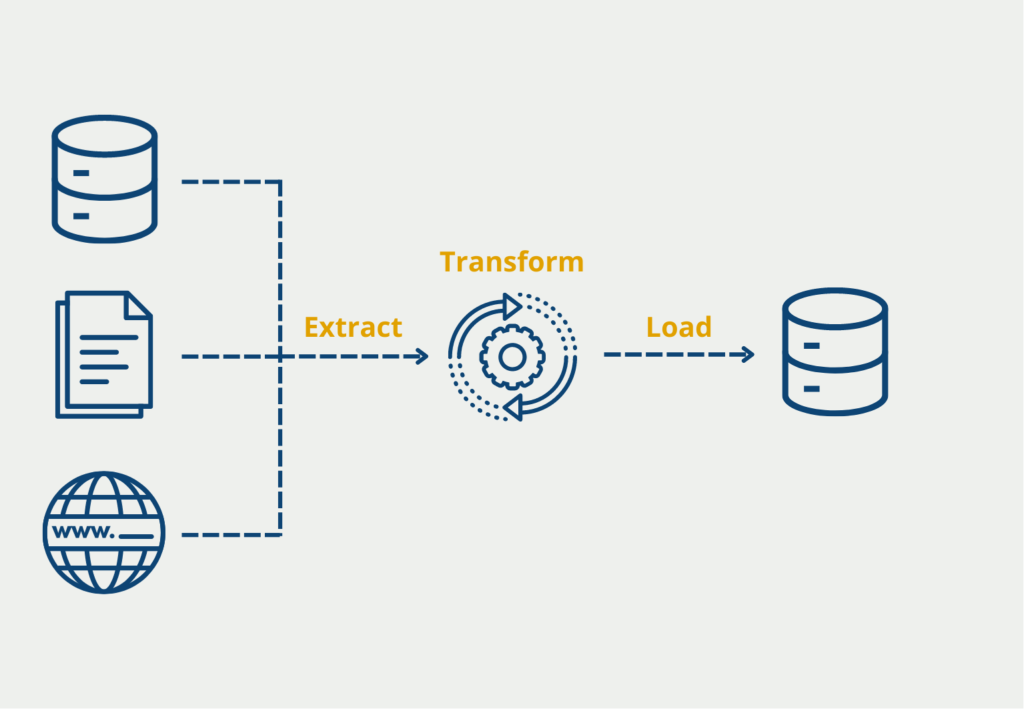
- Slow query performance: Traditional data warehouses rely on a schema-on-write approach, which can result in slow query performance. Data Lakehouses use a schema-on-read approach, enabling businesses to analyze data without compromising performance.
- Limited analytics capabilities: Traditional data warehouses are designed primarily for storing data, and they often have limited analytics capabilities. They provide businesses with advanced analytics capabilities, enabling them to derive insights from their data quickly and make informed decisions.
- Data quality issues: With the increasing volume and variety of data, ensuring data quality has become a challenge for businesses. Data Lakehouses provide businesses with tools and processes to monitor and ensure data quality, enabling them to trust their data and make data-driven decisions with confidence.
How can data be collected and stored in a Data Lakehouse?
Data lakes and data warehouses have long been the go-to solutions for storing and managing data in the world of analytics and business intelligence. However, as data sources have become increasingly diverse and complex, a new concept has emerged: the data lakehouse. Combining the best of both worlds, the data lakehouse architecture offers a powerful way to collect, store, and analyze data. But before we dive into the details, let’s explore what data ingestion is and what considerations beginners should keep in mind when collecting data for a data lakehouse.
Data ingestion is the process of collecting, importing, and processing data from various sources and making it available for analysis in a centralized repository. In the context of a data lakehouse, this repository is a unified storage system that combines the flexibility of a data lake with the query performance and structure of a data warehouse.
Data Sources:
- Identify Data Sources: Begin by identifying the sources of data within your organization. These can include databases, cloud storage, streaming platforms, IoT devices, external APIs, and more.
- Understand Data Types: Different sources produce data in various formats, such as structured (relational databases), semi-structured (JSON, XML), or unstructured (text documents, images). Understanding the types of data you’re dealing with is crucial.
Data Quality:
- Data Cleansing: Before ingesting data into your lakehouse, it’s essential to clean and preprocess it. This includes handling missing values, removing duplicates, and addressing data inconsistencies.
- Data Validation: Implement validation checks to ensure data integrity. This can involve verifying data against predefined rules or constraints.
Data Transformation:
- Schema Evolution: Data sources can change over time. Consider how your lakehouse handles schema changes and versioning to ensure compatibility with existing data.
- ETL (Extract, Transform, Load): Develop ETL pipelines to transform data into a format suitable for analysis. This might involve aggregating data, enriching it with additional information, or performing calculations.
Data Security and Compliance:
- Access Control: Define access controls and permissions to restrict who can access and modify data in the lakehouse. This is critical for data security.
- Compliance Regulations: Be aware of any regulatory compliance requirements (e.g., GDPR, HIPAA) that apply to your data. Ensure your data handling processes are compliant.
Data Catalog and Metadata:
- Catalog Data: Maintain a data catalog that provides metadata information about the ingested data. This makes it easier for users to discover and understand available data assets.
- Metadata Management: Implement metadata management practices to keep track of data lineage, versioning, and usage.
Scalability and Performance:
- Scalability: Consider how your data ingestion processes can scale as the volume of data grows. Cloud-based solutions often provide elasticity to handle varying workloads.
- Performance Optimization: Tune the performance of your data lakehouse by indexing, partitioning, and optimizing queries to ensure fast and efficient data retrieval.
Monitoring and Logging:
- Monitoring Tools: Set up monitoring tools to track the health and performance of your data ingestion processes. This includes error monitoring, latency tracking, and resource utilization.
- Logging: Maintain detailed logs of data ingestion activities for auditing, troubleshooting, and historical analysis.
Data Governance:
- Data Lineage: Establish data lineage to track how data moves through your organization. This helps in maintaining data quality and compliance.
- Data Stewardship: Appoint data stewards responsible for ensuring data quality, security, and compliance within your lakehouse.
Remember, data ingestion is just the first step in the journey of data utilization within a data lakehouse. Well-considered data ingestion practices lay the foundation for effective data analytics, reporting, and decision-making. By addressing these considerations, beginners can embark on their data lakehouse journey with a strong foundation for success.
Data Lakehouse vs. Data Lake
Data Lakehouses and data lakes share some similarities, but they are fundamentally different in their approach to data management. A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw form. The data is not processed or transformed, and there is no defined schema or structure. This approach provides businesses with the flexibility to store data from various sources and formats, but it can be challenging to analyze and derive insights from the data.
In contrast, Data Lakehouses provide businesses with the benefits of a data lake, such as flexibility and scalability, while also providing the structure and organization of a data warehouse. Data Lakehouses store data in its raw form, but they also enforce a schema-on-read approach, making it easier for businesses to analyze and derive insights from their data.
Data Lakehouse vs. Data Warehouse
Data warehouse solutions have been around for a long time, and they have been the go-to solution for businesses that need to store and analyze their data. However, data warehouses have some limitations. They rely on a schema-on-write approach, which means that data must be transformed and loaded into the data warehouse before it can be analyzed. This approach can be time-consuming and challenging to scale.
In contrast, Data Lakehouses provide businesses with the benefits of a data warehouse, such as structure and organization, while also providing the flexibility and scalability of a data lake. Data Lakehouses store data in its raw form and the schema is applied at the time of query execution. This approach gives businesses the agility to process and analyze large volumes of data in real time, making it easier to derive insights and make informed decisions.
What are the benefits of a Data Lakehouse?
In practice, the lakehouse concept combines the advantages of the data warehouse and the data lake and enables companies to operate efficient data management. The most frequently mentioned advantages include:
Flexibility and Scalability
Data Lakehouses provide businesses with the flexibility and scalability of a data lake, allowing them to store and analyze data from various sources and formats. This flexibility and scalability enable businesses to scale their operations and handle large volumes of data without compromising performance.
Real-time Analytics
Data Lakehouses enable businesses to analyze data in real-time, providing them with the agility to make informed decisions quickly. With real-time analytics, businesses can detect trends, patterns, and anomalies as they occur, enabling them to take proactive measures and make data-driven decisions.
Cost-Effective
Data Lakehouses are cost-effective solutions, as they allow businesses to store data in its raw form without expensive ETL processes. Businesses can store all their data in a centralized repository, reducing the need for multiple data storage
This is what you should take with you
- The Data Lakehouse combines the benefits of data lakes and data warehouses, offering a unified platform for storing, processing, and analyzing large amounts of data.
- Unlike traditional data warehouses, the lakehouse allows for flexible schema management, enabling organizations to store structured, semi-structured, and unstructured data.
- With the use of modern big data technologies like Apache Spark and Delta Lake, the lakehouse concept provides faster and more efficient data processing and querying capabilities.
- By leveraging the benefits of the cloud, it offers scalable and cost-effective data storage and processing, eliminating the need for costly on-premises infrastructure.
- Overall, the Data Lakehouse represents a promising solution for organizations looking to harness the power of big data to drive innovation and gain a competitive edge in today’s data-driven business landscape.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of Data Lakehouse
Microsoft provides an interesting article on the topic.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.