Der Extract, Transform, Load Prozess (kurz: ETL) beschreibt die Schritte zwischen dem Sammeln von Daten aus verschiedenen Quellen bis zum dem Punkt, an dem sie schließlich in einer Data Warehouse Lösung gespeichert werden können. Wenn große Datenmengen oder Daten visualisiert werden sollen, kommen die einzelnen Stufen zum Einsatz.
Was ist ETL?
Unternehmen und Organisationen stehen vor der Herausforderungen mit immer größeren Datenmengen umgehen zu müssen. Dabei stammen diese Informationen auch aus vielen, verschiedenen Systemen mit eigenen Datenstrukturen und Logiken. Diese Daten sollen möglichst einheitlich in einem zentralen Data Warehouse abgespeichert werden, um dann für Data Mining oder Data Analytics zur Verfügung zu stehen.
Damit diese Informationen verlässlich und belastbar sind, müssen sie aus den verschiedenen Quellsystemen gezogen, aufbereitet und dann in ein Zielsystem geladen werden. All das passiert in dem ETL Prozess.
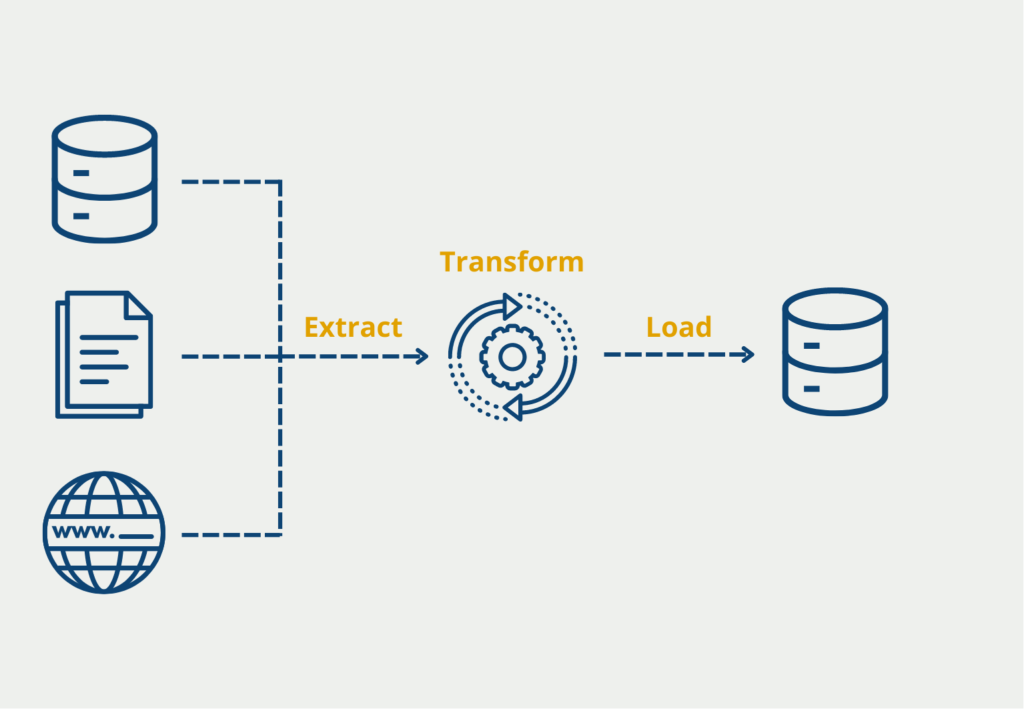
Was ist der ETL Prozess?
Um den Extract, Transform, Load Prozess besser verstehen zu können, lohnt es sich die einzelnen Phasen im Detail zu betrachten:
ETL Extract
Das Extrahieren bezeichnet den Prozessschritt, in dem Daten aus verschiedenen Quellen geholt werden, um sie zentral abzulegen. In diesem Schritt werden unter anderem auch Prüfungen zur Datenqualität durchgeführt, damit man einen sauberen Stand im Data Warehouse hat. Diese Prüfungen können beispielsweise die Übereinstimmung des Datentypes oder die Suche nach fehlenden Werten beinhalten. Beispielsweise könnte untersucht werden, ob alle Elemente, die einen Preis darstellen, auch in USD gekennzeichnet sind. Wenn die Daten grobe Qualitätsmängel aufweisen, können sie in dieser Stufe auch zurückgewiesen werden. Wenn keine oder nur wenige Mängel vorhanden sind, werden die Daten an die nächste Stufe übergeben und dort die notwendigen Änderungen vorgenommen.
Der Extract Schritt umfasst das Laden von Informationen aus den unterschiedlichsten Quellen. Dazu gehören unter anderem:
ETL Transform
In dieser Stufe werden alle Daten in eine Struktur transformiert, welche mit dem Datenmodell des Data Warehouses oder der Anwendung übereinstimmt. Wenn es noch Datenqualitätsprobleme geben sollte, werden diese nun bearbeitet. Dazu gehören zum Beispiel das Füllen von fehlenden Werten oder das Korrigieren von Fehlern. Darüber hinaus werden hier auch schon grundlegende Berechnungen vorgenommen mit denen die Daten zusammengefasst oder aufbereitet werden können. Darunter könnte beispielsweise fallen, dass der Umsatz bereits auf Tagesbasis aggregiert wird und nicht jeder Auftrag einzeln abgespeichert wird, wenn dies gefordert ist.
ETL Load
Die Daten, die wir in den vorherigen Schritten aufbereitet haben, können nun in das Data Warehouse oder die Zieldatenbank geladen werden. Falls sich dort schon ältere Informationen derselben Art befinden, müssen diese entsprechend ergänzt oder sogar ausgetauscht werden. Dies passiert häufig anhand einer eindeutigen ID oder indem der Zeitpunkt zu dem die Informationen gespeichert wurden mit eingetragen wird. Dadurch können die Daten verglichen werden und die veralteten Informationen gezielt gelöscht werden.
Wie wird ETL in Business Intelligence Anwendungen genutzt?
Business Intelligence (BI) ist der Prozess der Umwandlung von Rohdaten in aussagekräftige Erkenntnisse zur Unterstützung der strategischen Entscheidungsfindung in einem Unternehmen. ETL spielt eine zentrale Rolle bei der Ermöglichung effektiver BI, indem es die erforderlichen Datenintegrations-, Transformations- und Ladefunktionen bereitstellt. Im Folgenden werden einige wichtige Anwendungen von ETL in der Business Intelligence beschrieben:
- Datenintegration: ETL dient als Rückgrat von BI, indem es Daten aus verschiedenen Quellen integriert, darunter Datenbanken, Tabellenkalkulationen, Anwendungen und Cloud-Dienste. Die Datenintegration stellt sicher, dass alle relevanten Informationen in einem zentralen Datenspeicher gesammelt werden, so dass Geschäftsanalysten und Entscheidungsträger auf eine umfassende und einheitliche Ansicht der Unternehmensdaten zugreifen können.
- Datenbereinigung und -validierung: BI ist in hohem Maße auf genaue und zuverlässige Daten angewiesen. ETL-Prozesse umfassen Schritte zur Datenbereinigung und -validierung, bei denen Dateninkonsistenzen, Fehler und Duplikate identifiziert und korrigiert werden. Durch die Sicherstellung der Datenqualität trägt ETL dazu bei, die Integrität von BI-Berichten und Dashboards zu erhalten, was zu zuverlässigeren Erkenntnissen und Analysen führt.
- Laden historischer Daten: BI erfordert häufig die Analyse historischer Daten, um Trends, Muster und langfristige Leistungsindikatoren zu ermitteln. ETL ermöglicht das Laden historischer Daten in Data Warehouses oder Data Marts, so dass BI-Tools auf diese Informationen zugreifen können, um rückwirkende Analysen durchzuführen und Trends zu erkennen.
- Daten-Streaming in Echtzeit: In bestimmten BI-Szenarien sind Echtzeitdaten für eine zeitnahe Entscheidungsfindung unerlässlich. ETL kann so konzipiert werden, dass es Echtzeit-Daten-Streaming unterstützt, bei dem Daten kontinuierlich oder in regelmäßigen Abständen extrahiert, transformiert und in das BI-System geladen werden. Auf diese Weise wird sichergestellt, dass die BI-Berichte und -Dashboards die aktuellsten Informationen anzeigen, was eine agile und reaktionsschnelle Entscheidungsfindung ermöglicht.
- Inkrementelles Laden von Daten: ETL bietet die Möglichkeit des inkrementellen Datenladens, bei dem nur neue oder aktualisierte Daten extrahiert und in das BI-System geladen werden. Dieser Ansatz reduziert die Verarbeitungszeit und den Ressourcenverbrauch, da nur die Änderungen seit der letzten Datenaktualisierung berücksichtigt werden, was eine häufigere Aktualisierung der BI-Daten ermöglicht.
Zusammenfassend lässt sich sagen, dass ETL eine wichtige Rolle bei Business Intelligence spielt, indem es die Datenintegration, -bereinigung und -validierung, das Laden von historischen und Echtzeitdaten, inkrementelle Datenaktualisierungen, Datenaggregation, multidimensionale Datenmodellierung und Data Governance ermöglicht. Mithilfe von ETL können BI-Anwendungen genaue, zuverlässige und umsetzbare Erkenntnisse liefern, die Unternehmen in die Lage versetzen, fundierte Entscheidungen zu treffen und sich in der heutigen datengesteuerten Geschäftswelt einen Wettbewerbsvorteil zu verschaffen.
Welche Vorteile hat ETL?
ETL (Extrahieren, Transformieren, Laden) ist ein wichtiger Prozess im modernen Datenmanagement, der es Unternehmen ermöglicht, Daten aus verschiedenen Quellen zu sammeln, zu bearbeiten und in ein zentrales Daten-Repository zu integrieren. Dieser Datenintegrationsansatz bietet zahlreiche Vorteile, die es Unternehmen ermöglichen, datengestützte Entscheidungen zu treffen, die betriebliche Effizienz zu steigern und einen Wettbewerbsvorteil zu erlangen. Im Folgenden sind einige der wichtigsten Vorteile von ETL aufgeführt:
- Datenintegration und -konsolidierung: Mit ETL können Unternehmen Daten aus heterogenen Quellen wie Datenbanken, Tabellenkalkulationen, Webservices und Cloud-Anwendungen extrahieren und in ein einheitliches, standardisiertes Format umwandeln. Durch die Konsolidierung von Daten aus verschiedenen Quellen können Unternehmen Datensilos beseitigen und einen ganzheitlichen Überblick über ihre Abläufe gewinnen, was zu besseren Einblicken und fundierten Entscheidungen führt.
- Verbesserte Datenqualität: Die Datenqualität ist entscheidend, um genaue und zuverlässige Entscheidungen zu treffen. Die Transformationsphase in ETL ermöglicht die Bereinigung, Anreicherung und Validierung von Daten. Sie stellt sicher, dass fehlerhafte, doppelte oder unvollständige Daten erkannt und korrigiert werden, was zu einer höheren Datenqualität führt. Saubere und konsistente Daten erhöhen die Vertrauenswürdigkeit von Analysen und Berichten und verringern das Risiko, falsche Geschäftsentscheidungen zu treffen.
- Effiziente Datenverarbeitung: ETL-Prozesse sind darauf ausgelegt, große Datenmengen effizient zu verarbeiten. Durch die Optimierung von Datenextraktions- und -umwandlungsaufgaben können ETL-Tools die Zeit, die für die Verarbeitung großer Datenmengen benötigt wird, erheblich reduzieren. Dank dieser Effizienz können Unternehmen ihre Datenbestände häufiger aktualisieren und so sicherstellen, dass Entscheidungen auf aktuellen Informationen beruhen.
- Verbesserte Business Intelligence: ETL dient als Rückgrat für Business Intelligence (BI)-Initiativen. Durch die Integration unterschiedlicher Datenquellen schaffen ETL-Pipelines ein umfassendes Data Warehouse, das BI-Tools abfragen können, um aussagekräftige Erkenntnisse und Visualisierungen zu generieren. Die Verfügbarkeit zuverlässiger, integrierter Daten beschleunigt den BI-Prozess und ermöglicht es den Benutzern, Trends, Muster und Leistungsindikatoren problemlos zu analysieren.
- Skalierbarkeit und Flexibilität: Mit dem Wachstum von Unternehmen nehmen auch das Volumen und die Vielfalt der von ihnen verarbeiteten Daten zu. ETL bietet die Flexibilität, sich an veränderte Datenanforderungen anzupassen, so dass Unternehmen neue Datenquellen einbeziehen und ihre Datenverarbeitungsfunktionen nach Bedarf skalieren können. Diese Anpassungsfähigkeit stellt sicher, dass die Dateninfrastruktur mit dem Wachstum des Unternehmens und den sich ändernden Datenanforderungen Schritt halten kann.
- Einhaltung gesetzlicher Vorschriften und Datensicherheit: Viele Branchen müssen strenge Vorschriften zum Datenschutz und zur Datensicherheit einhalten. ETL ermöglicht die Datenbereinigung und -maskierung, wodurch sichergestellt wird, dass sensible Informationen geschützt sind, bevor sie im Data Warehouse gespeichert werden. Durch die Kontrolle des Zugriffs und die Implementierung von Data-Governance-Richtlinien während des ETL-Prozesses können Unternehmen die Einhaltung gesetzlicher Vorschriften gewährleisten und sensible Daten schützen.
- Zeit- und Kostenersparnis: Durch die Automatisierung von Datenintegrations- und -umwandlungsaufgaben reduzieren ETL-Prozesse den Zeit- und Arbeitsaufwand für die manuelle Datenverwaltung. Diese Automatisierung führt zu erheblichen Kosteneinsparungen, da sie die Notwendigkeit der manuellen Dateneingabe verringert und das Risiko menschlicher Fehler bei der Datenverarbeitung minimiert.
Zusammenfassend lässt sich sagen, dass ETL ein grundlegender Prozess ist, der Unternehmen, die datengesteuerte Entscheidungen treffen wollen, zahlreiche Vorteile bietet. Mit Datenintegration, verbesserter Datenqualität, effizienter Verarbeitung, verbesserter Business Intelligence, Skalierbarkeit und Einhaltung von Vorschriften legt ETL den Grundstein für ein robustes Datenmanagement und hilft Unternehmen, ihre Ziele zu erreichen und in einer datenzentrierten Welt wettbewerbsfähig zu bleiben.
Welche Herausforderungen ergeben sich bei ETL?
Die ETL Stufen stellen vor allem eine möglichst große Herausforderung, wenn viele und sehr unterschiedliche Systeme und deren Daten migriert werden sollen. Dann kommt es nicht selten vor, dass die Datenmodelle komplett unterschiedlich sind und viel Arbeit in deren Transformation fließen muss.
Ansonsten ist der Transformationsschritt auch sehr aufwendig, wenn die Datenqualität Mängel aufweist, die erst behoben werden müssen. In manchen Anwendungen lassen sich zum Beispiel fehlende Werte gar nicht verhindern und müssen aber trotzdem entsprechend behandelt werden. Wenn wir Messdaten in einer Produktionsstraße beispielsweise haben, die die Bauteile auf dem Fließband misst, aber zwischen dem 30.05.2021 und dem 01.06.2021 gewartet wurde und somit in diesem Zeitraum keine Daten erhoben wurden. Entsprechend fehlen uns für alle Datensätze in diesem Zeitraum die Messungen der Bauteillänge. Wir könnten nun entweder die Datensätze aus dem Zeitraum nicht beachten oder beispielsweise die fehlenden Felder durch den Durchschnitt der Messwerte aus den Tagen unmittelbar davor und danach ersetzen.
ETL vs. ELT
Der ETL Prozess hat sich bereits über mehrere Jahre und Jahrzehnte etabliert. Jedoch sind die Datenmengen, welche in vielen Anwendungen anfallen, im selben Zeitraum auch sehr stark gestiegen. Deshalb wäre es eine sehr teure Angelegenheit alle entstehenden Daten auch direkt zu strukturieren und in einem Data Warehouse abzuspeichern. Vielmehr werden unstrukturierte Daten in den meisten Fällen erst in einem sogenannten Data Lake abgelegt. Dort liegen die Daten in ihrem Rohformat vor bis sie für eine konkrete Anwendung benötigt werden.
Für diesen Ablauf wurde der ETL Prozess zum sogenannten ELT Prozess abgewandelt. Wie die Anordnung der Buchstaben bereits verrät wird bei der Befüllung eines Data Lakes erst der “Load” Step vorgenommen. Im Data Lake sind die Daten also noch unstrukturiert, unsortiert und auch nicht korrigiert.

Sobald diese Informationen für einen konkreten Use Case benötigt werden und das Zieldatenformat festgelegt wurden, passiert der “Transform” Prozess in dem die Daten aufbereitet werden. Als Technologie für den Data Lake kann beispielsweise Hadoop genutzt werden.
Welche anderen Methoden gibt es zur Datenintegration?
Neben ETL und ELT gibt es noch andere, häufig genutzte Möglichkeiten zur Dateningetration. Die Auswahl hängt dabei immer stark vom konkreten Anwendungsfall und den Prioritäten ab. Eine Auswahl an Methoden zum Datenaustausch und zur Datenintegration sind:
- ETL (Extrahieren, Transformieren, Laden): Hierbei handelt es sich um einen Prozess, bei dem Daten aus verschiedenen Quellen extrahiert, in ein leicht zu analysierendes Format umgewandelt und dann in ein Zielsystem geladen werden.
- ELT (Extrahieren, Laden, Transformieren): Ähnlich wie ETL, jedoch erfolgt die Umwandlung, nachdem die Daten in das Zielsystem geladen wurden.
- Datenvirtualisierung: Bei dieser Methode wird eine virtuelle Ebene zwischen den Datenquellen und dem Zielsystem geschaffen. Die virtuelle Schicht ermöglicht es dem Zielsystem, auf die Daten aus mehreren Quellen zuzugreifen, ohne dass eine physische Integration erforderlich ist. Im Klartext bedeutet dies, dass der Nutzer nicht erkennt, dass er auf verschiedene Quellen zugreift, jedoch die Daten nicht aus dem Quellsystem transportiert werden müssen.
- Data Federation: Bei dieser Methode werden Daten aus mehreren Quellen integriert, indem eine virtuelle Datenbank erstellt wird, die alle Daten aus den verschiedenen Quellen enthält.
- Datenreplikation: Bei dieser Methode werden Daten aus mehreren Quellen in ein einziges Zielsystem repliziert.
- Stammdatenverwaltung (MDM): Hierbei handelt es sich um eine Methode zur Erstellung einer Stammdatenbank mit gemeinsamen Datenelementen, die von mehreren Systemen gemeinsam genutzt werden können.
- Anwendungsprogrammierschnittstellen (APIs): APIs ermöglichen es verschiedenen Systemen, miteinander zu kommunizieren und Daten auszutauschen.
- Änderungsdatenerfassung (CDC): Bei dieser Methode werden Datenänderungen in Echtzeit erfasst und aufgezeichnet, so dass die Systeme immer mit den aktuellsten Daten arbeiten können.
Wie findet man das richtige ETL-Tool?
Im Internet finden sich heute viele kostenlose und kostenpflichtige Tools mit denen sich die Datenintegration im Unternehmen organisieren lässt. Bei dieser schieren Masse an Optionen benötigt man verschiedene Kriterien, an denen sich die Werkzeuge neutral vergleichen und bewerten lassen. Die folgenden Punkte können in vielen Fällen weiterhelfen das passende Tool für den Anwendungsfall zu finden:
- Budget: Die Kosten für ETL-Tools können von wenigen Euros bis zu einem halben Vermögen reichen. Es muss festgelegt werden, wie viel Geld man bereit ist für die Lösung aufzuwenden. Dabei muss man auch bedenken, dass manche eine Einmalzahlung fordern und andere Lösungen monatlich bezahlt werden.
- Ausgangssituation: Die konkreten Aufgaben und anfallenden Datenmengen müssen neutral betrachtet werden, um festzustellen, wie leistungsstark die Lösung sein muss und welche Speichermengen benötigt werden. Dabei sollte auch in Betracht gezogen werden, wie sich die Situation mittelfristig entwickeln wird.
- Personelle Ressourcen: Bei der Auswahl eines geeigneten ETL-Tools sollte auch festgestellt werden, welche Personen das Programm in welchem Umfang nutzen werden. Wenn man ausgebildetes Personal hat, das in der Lage ist das Programm an die individuellen Bedürfnisse anzupassen, kann ein anderes Tool gewählt werden. Ansonsten sollte es eher eine leicht zu bedienende Lösung sein, die am Besten direkt nutzbar ist. Genauso stellt sich die Frage, ob das vorhandene Personal bereits mit der Programmiersprache arbeiten kann, die das ETL-Tool nutzt. Wenn nicht, müssen teure, externe Berater genutzt werden, welche wiederum einen Einfluss auf das Budget haben.
- Kompatibilitäten: Ein weiterer wichtiger Punkt ist die Frage, welche Datenquellen an das System angeschlossen werden sollen. Nicht alle Lösungen bieten passende Konnektoren für alle Datenbanklösungen an. Somit ist dies auch ein wichtiges Auswahlkriterium.
Welche Programme für ETL gibt es?
Im Folgenden präsentieren wir eine kleine Auswahl an ETL-Tools, die sich bereits etabliert haben und in vielen ähnlichen Artikeln positiv hervorgehoben werden. Alle vorgestellten Programme sind darüber hinaus entweder komplett kostenlos oder bieten die Möglichkeit eine kostenlose Probezeit zu machen.
IBM DataStage
Hierbei handelt es sich um ein Data Integration Tool, das speziell für Unternehmen konzipiert wurde. Es biete sowohl die Möglichkeit den klassischen ETL Prozess zu durchlaufen, als auch ELT Pipelines zu bauen. Die Ausführung der Pipelines wird dabei parallelisiert und bietet automatisches Load Balancing, um die Performance weiter zu verbessern.
Wie die meisten Tools, gibt es bestehende Konnektoren für viele Datenbanken und Programme, die nicht unbedingt von IBM direkt sein müssen. Das Tool bietet sich vor allem auch dann an, wenn die Daten für nachgeschaltete AI Services genutzt werden sollen.
Apache Hadoop
Diese open-source Lösung ist der Quasi-Standard für viele Big Data Anwendungen und kann auch für Extract-Transform-Load Pipelines eingesetzt werden. Es bietet vor allem dann Vorteile, wenn große Mengen unstrukturierte Daten aufbereitet und transportiert werden sollen. Durch das verteilte Rechencluster kann die Performance gesteigert werden.
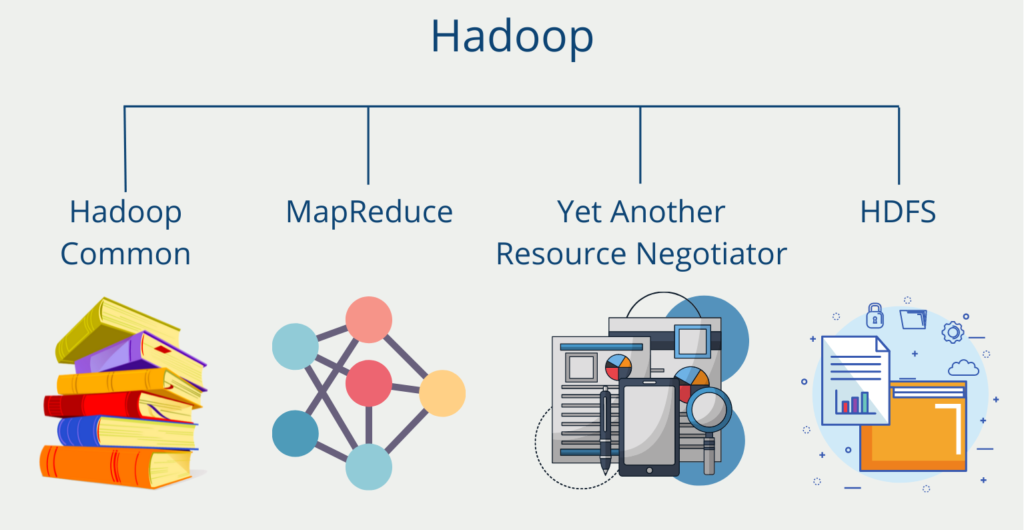
Darüber hinaus bietet es viele Integration von verschiedensten Plattformen und starke eingebaute Features, wie beispiels das Hadoop Distributed File System oder den MapReduce Algorithmus.
Hevo Pipeline
Hevo bietet ein leistungsfähiges Framework bei der Arbeit mit ETL und ELT Pipelines. Im Vergleich zu den bisherigen Programmen sticht es auch durch das einfache Frontend hervor, das es vielen Anwendern ermöglicht innerhalb von Minuten Datenpipelines aufzusetzen. Das ist besonders im Vergleich zu Hadoop ein Vorteil, da auch nicht geschultes Personal das Programm bedienen kann.
Zusätzlich können bereits mehr als 150 verschiedene Datenquellen angebunden werden, darunter auch SaaS Programme oder Datenbanken mit Change Data Capturing. Diese Basis wird ständig erweitert, um ein reibungsloses Plug-and-Play mit vielen Datenbanken herstellen zu können. Darüber hinaus loben Nutzer auch den Kundenservice, der bei möglichen Problemen schnell und kompetent helfen kann.
Das solltest Du mitnehmen
- ETL enthält wichtige Prozessschritte zur Datensammlung aus verschiedenen Systemen, deren Aufbereitung und Speicherung in ein Zielsystem.
- In den einzelnen Stufen wird sichergestellt, dass die Informationen dem Datenmodell angeglichen werden und gewisse Qualitätsstandards eingehalten werden.
- ETL kommt vor allem dann zum Einsatz, wenn Daten in einem Data Warehouse abgespeichert werden sollen oder in BI-Anwendungen zur Anzeige kommen.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema ETL
- Hier findest Du einen Vergleich von beliebten ETL Tools, die viele der beschriebenen Schritte automatisieren.
- Ansonsten können auch viele, grundlegende ETL Schritte innerhalb von Python erledigt werden. Einige grundlegende Befehle findest Du in unserem dazugehörigen Abschnitt.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.