Das Apache Hadoop Distributed Filesystem (kurz: HDFS ist ein verteiltes Filesystem, um große Datenmengen im Bereich von Big Data abspeichern und auf verschiedenen Computern verteilen zu können. Dieses System ermöglicht es Apache Hadoop über eine Vielzahl von Nodes, also Computern, verteilt laufen zu können.
Was ist das Apache Hadoop Framework?
Apache Hadoop ist ein Softwareframework mit dem sich große Datenmengen auf verteilten Systemen schnell verarbeiten lassen. Es verfügt über Mechanismen, welche eine stabile und fehlertolerante Funktionalität sicherstellen, sodass das Tool für die Datenverarbeitung im Big Data Umfeld bestens geeignet ist. Das Softwareframework selbst ist eine Zusammenstellung aus insgesamt vier Komponenten.
Hadoop Common ist eine Sammlung aus verschiedenen Modulen und Bibliotheken, welche die anderen Bestandteile unterstützt und deren Zusammenarbeit ermöglicht. Unter anderem sind hier die Java Archive Dateien (JAR Files) abgelegt, die zum Starten von Hadoop benötigt werden. Darüber hinaus ermöglicht die Sammlung die Bereitstellung von grundlegenden Services, wie beispielsweise das File System.
Der Map-Reduce Algorithmus geht in seinen Ursprüngen auf Google zurück und hilft komplexe Rechenaufgaben in überschaubarere Teilprozesse aufzuteilen und diese dann über mehrere Systeme zu verteilen, also horizontal zu skalieren. Dadurch verringert sich die Rechenzeit deutlich. Am Ende müssen die Ergebnisse der Teilaufgaben wieder zu seinem Gesamtresultat zusammengefügt werden.
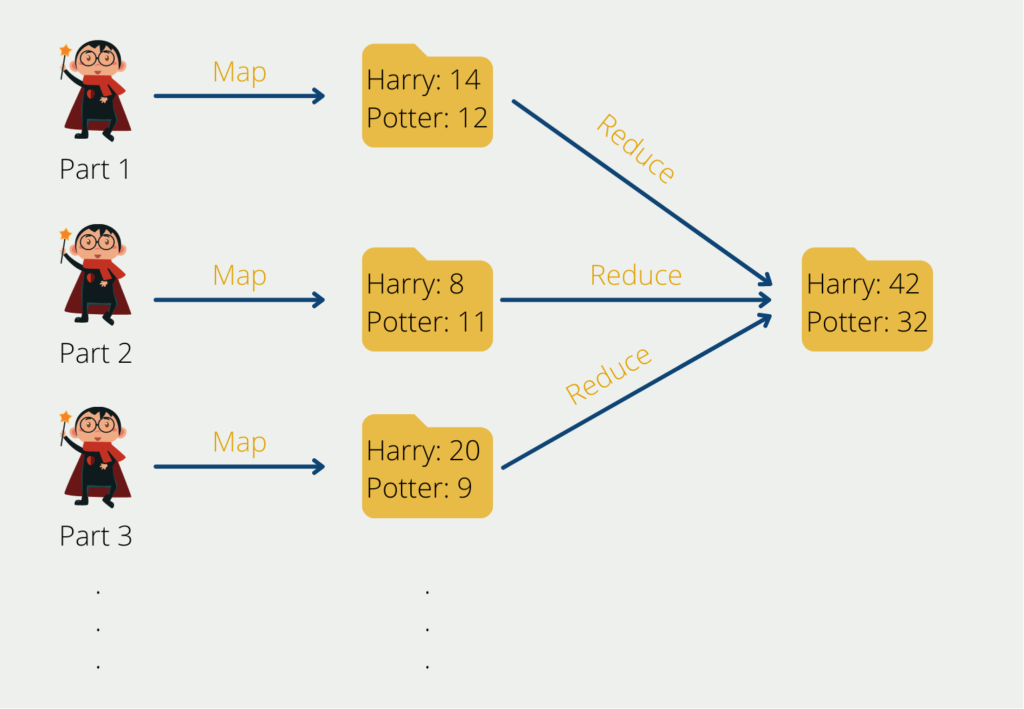
Der Yet Another Resource Negotiator (YARN) unterstützt den Map-Reduce Algorithmus, indem er die Ressourcen innerhalb eines Computer Clusters im Auge behält und die Teilaufgaben auf die einzelnen Rechner verteilt. Darüber hinaus ordnet er den einzelnen Prozessen die Kapazitäten dafür zu.
Das Apache Hadoop Distributed File System (HDFS) ist ein skalierbares Dateisystem zur Speicherung von Zwischen- oder Endergebnissen, auf das wir in diesem Beitrag genauer eingehen werden.
Wofür benötigen wir Apache HDFS?
Innerhalb des Clusters ist ein HDFS über mehrere Rechner verteilt, um große Datenmengen schnell und effizient verarbeiten zu können. Die Idee dahinter ist, dass Big Data Projekte und Datenanalysen auf großen Datenmengen beruhen. Somit sollte es ein System geben, welches die Daten auch stapelweise speichert und dadurch schnell verarbeitet. Das HDFS sorgt auch dafür, dass Duplikate von Datensätzen abgelegt werden, um den Ausfall eines Rechners verkraften zu können.
Laut der eigenen Dokumentation verfolgt Hadoop mit der Nutzung von HDFS die folgenden Ziele:
- Schnelle Erholung von Hardware Ausfällen
- Ermöglichung von Stream-Datenverarbeitung
- Verarbeitung von riesigen Datensätzen
- Leicht umziehbar auf neue Hard- oder Software
Wie ist ein Hadoop Distributed File Systems aufgebaut?
Der Kern des Hadoop Distributed File Systems besteht darin die Daten auf verschiedene Dateien und Computer zu verteilen, sodass Abfragen schnell bearbeitet werden können und der Nutzer keine langen Wartezeiten hat. Damit der Ausfall einer einzelnen Maschine im Cluster nicht zum Verlust der Daten führt, gibt es gezielte Replikationen auf verschiedenen Computern, um eine Ausfallsicherheit zu gewährleisten.
Apache Hadoop arbeitet im Allgemeinen nach dem sogenannten Master-Slave-Prinzip. Innerhalb des Computerclusters haben wir einen Knoten, der die Rolle des sogenannten Masters übernimmt. Dieser führt in unserem Beispiel keine direkte Berechnung durch, sondern verteilt lediglich die Aufgaben auf die sogenannten Slave Knoten und koordiniert den ganzen Prozess. Die Slave Knoten wiederum lesen die Bücher aus und speichern die Worthäufigkeit und die Wortverteilung.
Dieses Prinzip wird auch bei der Datenspeicherung genutzt. Der Master verteilt Informationen aus dem Datensatz auf verschiedenen Slave Nodes und merkt sich, auf welchen Computern er welche Partitionen abgespeichert hat. Dabei legt er die Daten auch redundant ab, um Ausfälle kompensieren zu können. Bei einer Abfrage der Daten durch den Nutzer entscheidet der Masterknoten dann, welche Slaveknoten er anfragen muss, um die gewünschten Informationen zu erhalten.
Den Master innerhalb des Apache Hadoop Distributed File Systems bezeichnet man als Namenode. Die Slave Nodes wiederum sind die sogenannten Datanodes. Von unten nach oben lässt sich der schemahafte Aufbau wie folgt verstehen:
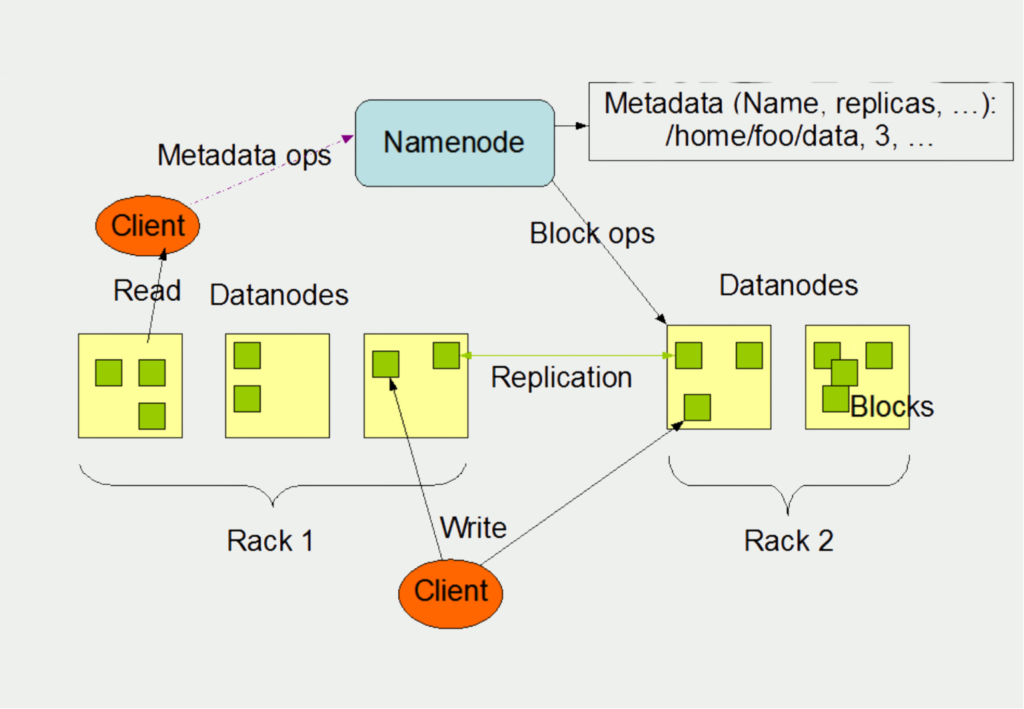
Der Client schreibt Daten in verschiedene Files, welche auf unterschiedlichen Systemen liegen können, in unserem Beispiel die Datanodes auf Rack 1 und 2. Pro Rechner in einem Cluster gibt es in der Regel einen Datanode. Diese verwalten vornehmlich den Speicher, der ihnen auf einem Rechner zur Verfügung steht. Im Speicher werden meist mehrere Files abgelegt, welche wiederum in sogenannte Blocks aufgesplittet sind.
Die Aufgabe des Namenodes besteht darin, sich zu merken, welche Blocks in welchem Datanode gespeichert sind. Zusätzlich verwalten sie die Files und können diese öffnen, schließen und nach Bedarf auch umbenennen.
Die Datanodes wiederum sind verantwortlich für die Lese- und Schreibprozesse des Clients, also des Anwenders. Von ihnen erhält der Client auch die gewünschten Informationen bei einer Abfrage. Gleichzeitig sind die Datanodes auch für die Replikation von Daten verantwortlich, um die Fehlertoleranz des Systems zu gewährleisten.
Was sind die Grenzen von HDFS?
Das Hadoop Distributed File System (HDFS) hat sich zu einer beliebten Wahl für die Speicherung und Verarbeitung großer Datenmengen entwickelt. HDFS bietet zwar mehrere Vorteile, hat aber auch einige Einschränkungen, die die Benutzer kennen sollten:
- Einzelner Fehlerpunkt: HDFS hat eine Master-Slave-Architektur, bei der der NameNode als Master und die DataNodes als Slaves fungieren. Wenn der NameNode ausfällt, wird der gesamte Cluster unzugänglich, und die Daten sind nicht mehr verfügbar. Obwohl Hadoop einen Mechanismus zur automatischen Ausfallsicherung bietet, kann es dennoch zu Ausfallzeiten kommen.
- Begrenzte Unterstützung für kleine Dateien: Das File System ist für die Speicherung und Verarbeitung großer Dateien, in der Regel im Bereich von Gigabyte bis Terabyte, konzipiert. Bei einer großen Anzahl kleiner Dateien ist es jedoch nicht sehr leistungsfähig, da es einen erheblichen Overhead bei der Verwaltung von Metadaten und der Zuweisung von Speicherplatz verursacht.
- Hohe Speicherkosten: HDFS verwendet einen Replikationsmechanismus, um Datenverfügbarkeit und Fehlertoleranz zu gewährleisten, was zu hohen Speicherkosten führen kann. Je mehr Replikate von Daten im Cluster gespeichert werden, desto höher sind die Speicherkosten.
- Langsamer Datenzugriff: Das System verwendet ein WORM-Modell (write-once-read-many), das für den sequentiellen Datenzugriff optimiert ist. Dies hat zur Folge, dass der zufällige Datenzugriff, insbesondere bei kleinen Dateien, langsam und ineffizient sein kann.
- Begrenzte Unterstützung für die Datenverarbeitung in Echtzeit: HDFS ist nicht für die Datenverarbeitung in Echtzeit ausgelegt, da es ein stapelorientiertes Verarbeitungsmodell erfordert. Das Hadoop-Ökosystem bietet zwar Tools wie Apache Spark, Flink und Storm für die Echtzeitverarbeitung, diese sind jedoch nicht direkt mit HDFS integriert.
Trotz dieser Einschränkungen bleibt HDFS ein weit verbreitetes verteiltes Dateisystem für die Speicherung und Verarbeitung großer Datenmengen. Es wird häufig in Verbindung mit anderen Tools des Hadoop-Ökosystems verwendet, um eine vollständige Datenverarbeitungslösung bereitzustellen.
Was sind die Vorteile vom Hadoop Distributed File System?
Für viele Unternehmen wird das Apache Hadoop Framework auch aufgrund des HDFS immer interessanter als Data Lake, also als unstrukturierter Speicher für große Datenmengen. Dabei spielen verschiedene Punkte eine maßgebliche Rolle:
- Möglichkeit große Datenmengen in einem verteilten Cluster zu speichern. Das ist in den meisten Fällen deutlich günstiger als die Informationen auf einer einzigen Maschine abzuspeichern.
- Hohe Fehlertoleranz und dadurch hochverfügbare Systeme
- Hadoop ist Open-Source und somit kostenlos nutzbar und der Quellcode einsehbar
Diese Punkte erklären die steigende Verbreitung von Hadoop und HDFS in vielen Anwendungen.
Wie sieht die Zukunft von HDFS aus?
Das Hadoop Distributed File System (HDFS) hat sich in vielen Big-Data-Umgebungen durchgesetzt und ist seit mehr als einem Jahrzehnt auf dem Markt. Wie bei jeder Technologie entwickelt sich auch die Zukunft von HDFS ständig weiter, und es gibt mehrere Trends, die seine Entwicklung wahrscheinlich beeinflussen werden.
Einer der wichtigsten Trends, der die Zukunft von HDFS bestimmt, ist das Wachstum der Cloud. Cloud Computing ist in den letzten Jahren immer beliebter geworden, und viele Unternehmen verlagern ihre Daten und Anwendungen in die Cloud. HDFS bildet da keine Ausnahme, und es gibt inzwischen cloudbasierte HDFS-Dienste, mit denen Unternehmen ihre Big Data in der Cloud speichern und verwalten können. Dieser Trend wird sich wahrscheinlich fortsetzen, und wir können davon ausgehen, dass es in Zukunft mehr Cloud-basierte HDFS-Dienste geben wird.
Ein weiterer Trend, der die Zukunft von HDFS bestimmt, ist das Wachstum von maschinellem Lernen und künstlicher Intelligenz. Da immer mehr Unternehmen maschinelles Lernen und KI-Technologien einsetzen, müssen sie große Datenmengen speichern und verwalten. HDFS ist für diese Aufgabe bestens geeignet, und es ist zu erwarten, dass immer mehr Unternehmen HDFS als Datenspeicher- und Verwaltungslösung für ihre maschinellen Lern- und KI-Workloads nutzen werden.
Zusätzlich zu diesen Trends gibt es auch einige technische Fortschritte, die die Zukunft von HDFS bestimmen. So ist HDFS traditionell ein Stapelverarbeitungssystem, aber es gibt jetzt Bemühungen, es für die Echtzeitverarbeitung besser geeignet zu machen. Dies erfordert Änderungen an der zugrundeliegenden Architektur von HDFS, und wir können davon ausgehen, dass es in Zukunft weitere Entwicklungen in diesem Bereich geben wird.
Insgesamt sieht die Zukunft von HDFS sehr gut aus. Es handelt sich um eine ausgereifte Technologie, die sich in vielen Big-Data-Umgebungen bewährt hat, und sie ist gut positioniert, um die Anforderungen von Unternehmen zu erfüllen, die große Datenmengen speichern und verwalten wollen. Da Cloud Computing, maschinelles Lernen und Echtzeitverarbeitung immer beliebter werden, können wir davon ausgehen, dass sich HDFS weiterentwickeln wird, um den Anforderungen dieser Trends gerecht zu werden.
Das solltest Du mitnehmen
- HDFS ist ein verteiltes Filesystem, um große Datenmengen im Bereich von Big Data abspeichern und auf verschiedenen Computern verteilen zu können.
- Es ist Teil des Apache Hadoop Frameworks.
- Der Masterknoten teilt die Datenmenge in kleinere Partionen auf und verteilt diese auf verschiedenen Computern, den sogenannten Slaveknoten.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema HDFS
- Eine ausführliche Dokumentation zum Hadoop Distributed File System findest Du auf deren Seite.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.