Apache Parquet is an open-source, column-oriented file format and belongs to the NoSQL databases. It allows efficient data storage of large amounts of data, using various encoding methods and data compression so that even complex data can be processed.
What is a Column-Oriented Database?
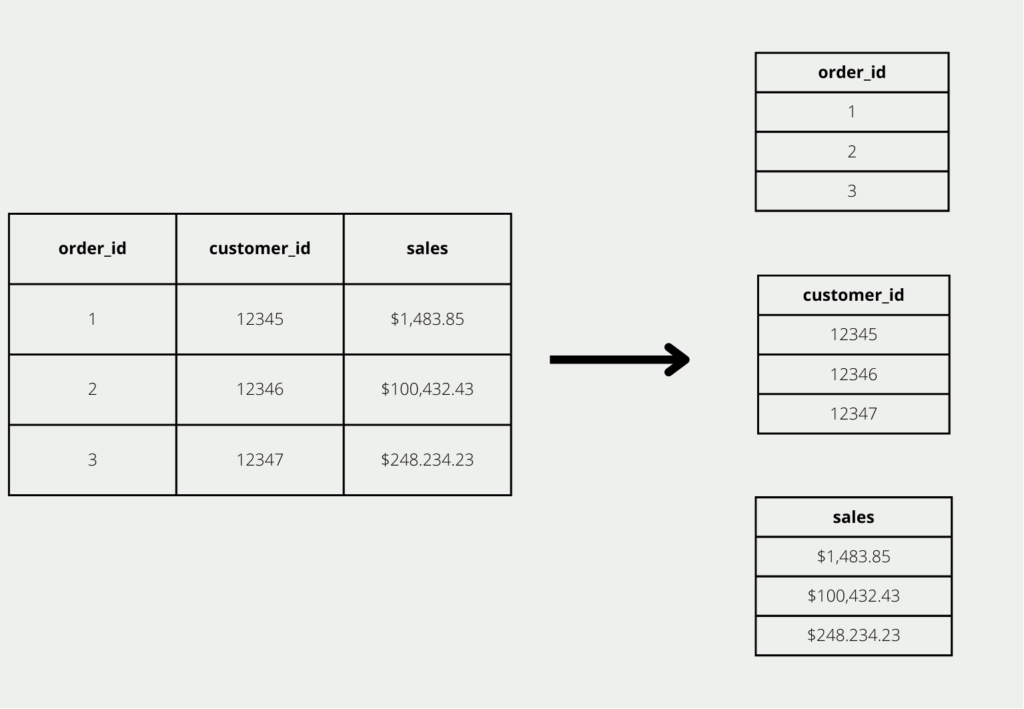
In conventional, relational databases, data is stored row by row. Each row is a self-contained record that contains, for example, information about an order. When a new order is added, the database is simply extended by an additional row.

However, if we want to use such an order database for evaluations, we mainly look at columns. For example, we can find the order with the highest turnover by looking for the maximum value in the “sales” column. Similar analyses, which can only be found by looking at columns, are the number of all customers or orders, as well as how many different products have been sold. That’s why people talk about traditional, row-based being optimized only for transaction processing, but not for data analysis.
The column-oriented database, on the other hand, stores the data column-by-column and tries to store the information in a column block-by-block on a disk rather than storing the rows together. This can significantly reduce query times since fewer disk accesses are required than with row-by-row storage. In addition, the data can also be stored in a much more compressed way, since only values from a column with the same data type are stored close to each other.
What are the Advantages of Column-Oriented Data Formats?
In addition to the fast query times of column-oriented databases, there are also the following advantages:
- Efficient Compression: By storing the same data types in one column, data can be compressed more efficiently.
- Fast Queries: Only the relevant columns need to be processed and not the entire row.
- No more Bottleneck in Queries: The limiting component in many databases is hard disk access. In addition, the development of hard disks is also relatively slow, especially compared to, for example, the CPU. Column-oriented data formats optimize accesses and thus reduce the problem of the hard disk being the bottleneck.
What is Apache Parquet?
Apache Parquet is a column-oriented data format that is not only available as an open source but also enables the efficient processing of complex, large data sets. Furthermore, it can be used in a wide variety of programming languages, including Python.
Parquet was developed to provide a column-oriented database for the Hadoop ecosystem and to further extend its functionalities. It is also designed to represent nested data structures. Additionally, custom encodings for data compression can also be incorporated.
What are the Advantages of Apache Parquet?
In addition to the advantages of storing in column-based formats, Apache Parquet also offers the following benefits:
- Data Compression: Due to the column-based structure, the data can be optimally compressed because a column only has data of the same data type and thus different compression methods can be used. There are thereby for example specialized methods for Strings and Integers.
- Query Speed: Because only the relevant columns are queried and the remaining information of the row is not needed, the query speed is very high. In addition, this method is also very economical in terms of memory, which in turn increases the speed.
- Data Structure: Apache Parquet can also store complex, nested data structures and process queries on them. This makes it so compatible with Big Data applications. In the same way, Parquet files can be created with just a few columns, and then additional columns can be added piece by piece.
- Open Source: Apache Parquet is open source and can therefore be used free of charge. In addition, it is currently used a lot and therefore new developments are published continuously, which can be used immediately.
- Hadoop: Apache Parquet is part of the Hadoop ecosystem and can therefore be very easily integrated into existing Big Data processes.
What are the limitations of Apache Parquet?
Apache Parquet is a popular columnar storage format for the Hadoop ecosystem, which provides high compression ratios, fast query performance, and efficient data encoding. However, it also has some limitations, including:
- Limited support for schema evolution: Once a Parquet file is written, the schema cannot be changed. This means that any changes to the schema will require creating a new file, which can be a time-consuming process for large datasets.
- High memory usage: When reading Apache Parquet files, a significant amount of memory is required to keep the column data in memory, especially when working with large datasets.
- Limited support for nested data: While Apache Parquet supports nested data types, such as arrays and structs, it has limited support for deeply nested or complex data structures, which can make it challenging to work with certain types of data.
- Lack of interoperability with non-Hadoop systems: Parquet is designed to work with Hadoop ecosystem tools, such as Spark and Hive, and is less compatible with other systems outside of the Hadoop ecosystem.
- Potentially slower write performance: While Apache Parquet excels at read performance, its write performance may be slower than other file formats, particularly for small datasets.
Overall, while Parquet is a powerful tool for columnar storage and analysis, it may not be the best fit for all use cases and may require careful consideration of its limitations when selecting a data storage format.
How is Parquet different from CSV?
CSV files are one of the most used file formats in the analytical field and are preferred by many users because they are easy to understand and compatible with many programs. This is why the comparison with Apache Parquet is useful. Furthermore, CSV files are row-oriented, i.e. they store data record by data record and are therefore the exact opposite of Apache Parquet files. For the comparison, we will use some, different criteria.
Data Analysis
For data analysis, CSV files are still quasi-standard, as it is easy to understand for many users and at the same time provide a good basis for fast and uncomplicated data transport. Furthermore, it is compatible with many analysis tools, such as Power BI or Tableau. However, due to its row-oriented structure, individual queries or changes can take a very long time, especially if a table has many columns. At the same time, with CSV, nested data in a column must first be separated in a time-consuming process, while Parquet can already handle this natively very well.
Query Performance
For many queries in the data science area, only individual columns are of interest, since aggregations such as totals or averages are performed with these. Apache Parquet is much better suited for this than CSV because of its column orientation. With CSV files, all columns must always be included in a query, even if they are not needed for the final result. This row orientation can only be useful if you need information from individual rows, for example, if you want to search for individual orders in the entire order backlog. However, this is rarely really desired.
Resource Efficiency
Apache Parquet’s optimal data compression allows the same data to be stored with less disk space than comparable CSV files. This results in less cost in disk consumption or cloud licenses if that is where the data resides. This can quickly add up to a lot of money for large amounts of data. Most importantly, the smaller amount of data also saves money and time in subsequent steps. When the data is processed, this can happen much faster and requires less hardware, which again saves a lot of money.
On the other hand, trained personnel in the use of Apache Parquet is not as widespread as employees who know how to use CSV. So at this point, it depends on the amount of data, and if the purchase of trained personnel actually pays off. However, this is very often the case.
What are the applications of Apache Parquet?
Apache Parquet is a popular columnar storage format that is used in various big data processing systems. Some of the common applications of Apache Parquet include:
- Big Data Analytics: Apache Parquet is widely used in big data analytics applications to store and process large amounts of data efficiently. It is used in systems like Apache Spark, Apache Hive, and Apache Impala to store and process data.
- Business Intelligence: Parquet is an ideal format for business intelligence (BI) applications where data is frequently queried and analyzed. Its columnar structure allows for faster querying and analysis, which is crucial for BI use cases.
- Data Warehousing: Parquet is a popular choice for data warehousing applications where the data is stored for long-term analysis. Its efficient storage and retrieval capabilities make it an ideal format for data warehouses.
- Machine Learning: Parquet is used in machine learning applications where large datasets are involved. Its efficient read and write capabilities make it ideal for training and testing machine learning models.
- Log Analytics: Parquet is also used in log analytics applications where large volumes of log data need to be processed and analyzed. Its columnar structure makes it easy to query and analyze log data efficiently
Overall, Apache Parquet is a versatile and widely used columnar storage format that has many applications in the big data ecosystem.
This is what you should take with you
- Apache Parquet is an open-source, column-oriented file format and belongs to the NoSQL databases.
- Column-oriented means that the data is stored column-wise and not row-wise.
- This results in various advantages, such as more efficient data compression or faster query times.
- Compared to CSV, it is especially better suited when large amounts of data are to be processed since resources are used more efficiently.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of Apache Parquet

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.