Apache Parquet ist ein open-source, spaltenorientiertes Dateiformat und zählt zu den NoSQL Datenbanken. Es ermöglicht die effiziente Datenspeicherung von großen Datenmengen und nutzt dabei verschiedene Enconding-Methoden und Datenkomprimierung, sodass auch komplexe Daten verarbeitet werden können.
Was ist eine spaltenorientierte Datenbank?
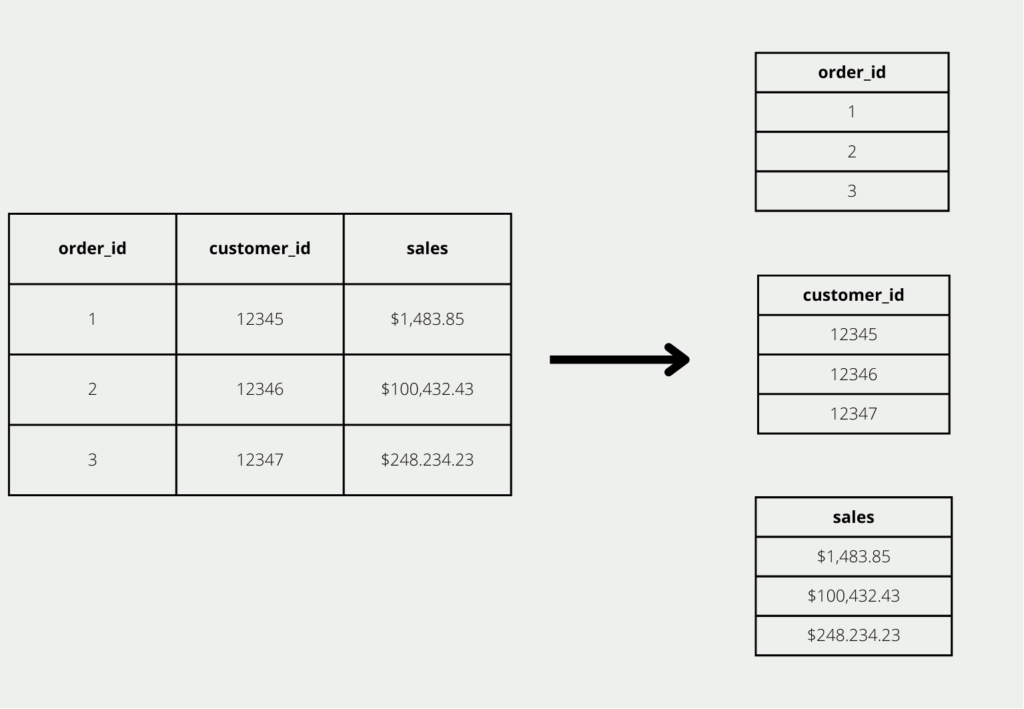
In herkömmlichen, relationalen Datenbanken werden Daten zeilenweise abgespeichert. Jede Zeil ist ein in sich geschlossener Datensatz, der beispielsweise Informationen über einen Auftrag enthält. Wenn ein neuer Auftrag hinzukommt, wird die Datenbank einfach um eine zusätzliche Zeile erweitert.

Wenn wir eine solche Auftragsdatenbank jedoch für Auswertungen nutzen wollen, betrachten wir vor allem Spalten. Den Auftrag mit dem höchsten Umsatz finden wir beispielsweise, indem wir in der Spalte “Umsatz” den maximalen Wert suchen. Ähnliche Analysen, die man nur spaltenorientiert herausfinden kann, sind die Anzahl aller Kunden oder der Aufträge, sowie wie viele unterschiedliche Produkte verkauft wurden. Deshalb spricht man auch davon, dass herkömmlich, zeilenbasierte lediglich für die Transaktionsverarbeitung optimiert sind, nicht aber für die Datenanalyse.
Die spaltenorientierte Datenbank hingegen legt die Daten spaltenweise ab und versucht die Informationen in einer Spalte blockweise auf der Festplatte abzulegen und nicht die Zeilen zusammen abzulegen. Dadurch können die Abfragezeiten deutlich verkürzt werden, da weniger Festplattenzugriffe benötigt werden, als bei einer zeilenweise Speicherung. Zusätzlich können die Daten auch deutlich komprimierter gespeichert werden, da nur Werte aus einer Spalte mit demselben Datentyp nahe beieinander liegen.
Welche Vorteile haben spaltenorientierte Datenformate?
Neben den schnellen Abfragezeiten von spaltenorientierten Datenbanken, ergeben sich auch die folgenden Vorteile:
- Effiziente Komprimierung: Durch die Speicherung von gleichen Datentypen in einer Spalte lassen sich die Daten effizienter komprimieren.
- Schnelle Abfragen: Nur die relevanten Spalten müssen verarbeitet werden und nicht die komplette Zeile.
- Kein Flaschenhals mehr bei Abfragen: Die limitierende Komponente bei vielen Datenbank sind die Festplattenzugriffe. Zusätzlich ist die Entwicklung bei Festplatten auch verhältnismäßig langsam, vor allem im Vergleich zu beispielsweise CPU. Spaltenorientierte Datenformate optimieren die Zugriffe und verringern somit das Problem, dass die Festplatte den Flaschenhals bildet.
Was ist Apache Parquet?
Apache Parquet ist ein spaltenorientiertes Datenformat, das nicht nur als Open-Source zur Verfügung steht, sondern auch die effiziente Verarbeitung von komplexen, großen Datenmengen ermöglicht. Darüber hinaus ist es in den verschiedensten Programmiersprachen nutzbar, darunter auch Python.
Parquet wurde entwickelt, um eine spaltenorientierte Datenbank für das Hadoop Ökosystem anzubieten und dessen Funktionalitäten weiter auszubauen. Darüber hinaus ist es so konzipiert, dass auch verschachtelte Datenstrukturen dargestellt werden können. Zusätzlich können auch eigene Encodings zur Datenkomprimierung eingearbeitet werden.
Welche Vorteile bietet Apache Parquet?
Neben den Vorteilen bei der Speicherung in spaltenbasierten Formaten bietet Apache Parquet auch die folgenden Vorzüge:
- Datenkomprimierung: Durch den spaltenbasierten Aufbau können die Daten optimal komprimiert werden, weil eine Spalte nur Daten im desselben Datentyps besitzt und dadurch verschiedene Komprimierungsverfahren genutzt werden können. Es gibt dabei beispielsweise spezialisierte Methoden für Strings und Integers.
- Abfragegeschwindigkeit: Dadurch dass nur die relevanten Spalten abgefragt werden und die restlichen Informationen der Zeile nicht benötigt werden, ist die Abfragegeschwindigkeit sehr hoch. Zusätzlich ist diese Methode auch sehr sparsam im Bezug auf Arbeitsspeicher, was die Geschwindigkeit wiederum erhöht.
- Datenstruktur: Apache Parquet kann auch komplexe, verschachtelte Datenstrukturen speichern und Abfragen darauf verarbeiten. Das macht es so gut kompatibel mit Big Data Anwendungen. Genauso lassen sich auch erst Parquet Dateien mit wenigen Spalten erstellen und sich dann Stück für Stück weitere Spalten hinzunehmen.
- Open-Source: Apache Parquet ist quelloffen und kann dadurch kostenlos genutzt werden. Hinzu kommt, dass es aktuell viel verwendet wird und somit auch durchgehend neue Weiterentwicklungen veröffentlicht werden, die sofort genutzt werden können.
- Hadoop: Apache Parquet ist Teil des Hadoop-Ökosystems und kann somit sehr einfach in bestehende Big Data Prozesse mit eingebaut werden.
Welche Herausforderungen gibt es mit Apache Parquet?
Apache Parquet ist ein beliebtes spaltenförmiges Speicherformat für das Hadoop-Ökosystem, das hohe Kompressionsraten, eine schnelle Abfrageleistung und eine effiziente Datenkodierung bietet. Allerdings hat es auch einige Einschränkungen, darunter:
- Begrenzte Unterstützung für die Schemaentwicklung: Sobald eine Parquet-Datei geschrieben wurde, kann das Schema nicht mehr geändert werden. Das bedeutet, dass für jede Änderung des Schemas eine neue Datei erstellt werden muss, was bei großen Datenmengen sehr zeitaufwändig sein kann.
- Hoher Speicherbedarf: Beim Lesen von Parquet-Dateien wird eine beträchtliche Menge an Speicher benötigt, um die Spaltendaten im Speicher zu halten, insbesondere bei der Arbeit mit großen Datensätzen.
- Begrenzte Unterstützung für verschachtelte Daten: Apache Parquet unterstützt zwar verschachtelte Datentypen wie Arrays und Structs, bietet aber nur begrenzte Unterstützung für tief verschachtelte oder komplexe Datenstrukturen, was die Arbeit mit bestimmten Datentypen erschweren kann.
- Mangelnde Interoperabilität mit Nicht-Hadoop-Systemen: Parquet wurde für die Arbeit mit Tools des Hadoop-Ökosystems, wie Spark und Hive, entwickelt und ist weniger kompatibel mit anderen Systemen außerhalb des Hadoop-Ökosystems.
- Potenziell langsamere Schreibleistung: Während sich Apache Parquet durch eine hervorragende Leseleistung auszeichnet, kann seine Schreibleistung langsamer sein als die anderer Dateiformate, insbesondere bei kleinen Datensätzen.
Insgesamt ist Apache Parquet zwar ein leistungsfähiges Tool für die Speicherung und Analyse von Spalten, doch ist es möglicherweise nicht für alle Anwendungsfälle am besten geeignet und erfordert bei der Auswahl eines Datenspeicherformats eine sorgfältige Berücksichtigung seiner Einschränkungen.
Wie unterscheidet sich Parquet von CSV?
CSV Dateien sind eine der meistgenutzten Dateiformate im analytischen Bereich und werden von vielen Anwendern bevorzugt, da sie leicht verständlich und mit vielen Programmen kompatibel sind. Deshalb bietet sich der Vergleich mit Apache Parquet an. Des Weiteren sind CSV-Dateien zeilenorientiert, also speichern Datensatz für Datensatz ab und bilden somit das genaue Gegenteil zu Apache Parquet Dateien. Für den Vergleich werden wir einige, verschiedene Kriterien nutzen.
Datenanalyse
Bei der Datenanalyse sind CSV-Dateien immer noch der Quasi-Standard, da es für viele Anwender einfach verständlich ist und gleichzeitig eine gute Basis für einen schnellen und unkomplizierten Datentransport bietet. Des Weiteren ist es mit vielen Analysetools, wie Power BI oder Tableau, kompatibel. Durch den zeilenorientierten Aufbau können jedoch einzelne Abfragen oder Änderungen sehr lange dauern, vor allem wenn eine Tabelle viele Spalten besitzt. Gleichzeitig müssen bei CSV verschachtelte Daten in einer Spalte erst aufwendig getrennt werden, während Parquet damit nativ bereits sehr gut umgehen kann.
Query Performance
Bei vielen Abfragen im Data Science Bereich sind lediglich einzelne Spalten von Interesse, da mit diesen Aggregationen, wie Summen oder Durchschnitte, durchgeführt werden. Dafür ist Apache Parquet aufgrund der Spaltenorientierung deutlich besser geeignet als CSV. Bei CSV Dateien müssen immer alle Spalten bei einer Abfrage berücksichtigt werden, auch wenn diese gar nicht für das schlussendliche Ergebnis benötigt werden. Diese Zeilenorientierung kann nur dann sinnvoll sein, wenn man Informationen aus einzelnen Zeilen benötigt, beispielsweise wenn man einzelne Aufträge im gesamten Auftragsbestand suchen will. Das ist jedoch in den seltensten Fällen wirklich gewünscht.
Ressourceneffizienz
Durch die optimale Datenkomprimierung bei Apache Parquet können dieselben Daten mit weniger Speicherplatz gespeichert werden, als vergleichbare CSV Dateien. Dadurch entstehen weniger Kosten beim Festplattenverbrauch oder bei Cloud-Lizenzen, falls die Daten dort liegen. Das kann bei großen Datenmengen schnell sehr viel Geld ausmachen. Vor allem sparen die geringeren Datenmengen auch in nachfolgenden Schritten Geld und Zeit ein. Wenn die Daten nämlich verarbeitet werden kann dies nämlich dann deutlich schneller passieren und erfordert dadurch weniger Hardware, auch das spart wieder hohe Kosten ein.
Auf der anderen Seite ist geschultes Personal im Umgang mit Apache Parquet nicht so stark verbreitet, wie Mitarbeiter, welche mit CSV umgehen können. In diesem Punkt hängt es also von der Datenmenge ab, ob sich der Einkauf von geschultem Personal auch tatsächlich auszahlt. Jedoch ist dies sehr häufig der Fall.
Welche Anwendungen nutzen Apache Parquet?
Apache Parquet ist ein beliebtes spaltenförmiges Speicherformat, das in verschiedenen Big-Data-Verarbeitungssystemen verwendet wird. Einige der häufigsten Anwendungen von Apache Parquet sind:
- Big Data-Analytik: Apache Parquet wird häufig in Big-Data-Analytics-Anwendungen verwendet, um große Datenmengen effizient zu speichern und zu verarbeiten. Es wird in Systemen wie Apache Spark, Apache Hive und Apache Impala verwendet, um Daten zu speichern und zu verarbeiten.
- Business Intelligence: Parquet ist ein ideales Format für Business Intelligence (BI)-Anwendungen, bei denen Daten häufig abgefragt und analysiert werden. Seine spaltenförmige Struktur ermöglicht eine schnellere Abfrage und Analyse, was für BI-Anwendungsfälle entscheidend ist.
- Data Warehousing: Parquet ist eine beliebte Wahl für Data Warehousing-Anwendungen, bei denen die Daten für langfristige Analysen gespeichert werden. Seine effizienten Speicher- und Abrufmöglichkeiten machen es zu einem idealen Format für Data Warehouses.
- Maschinelles Lernen: Parquet wird in Anwendungen des maschinellen Lernens verwendet, bei denen große Datensätze involviert sind. Seine effizienten Lese- und Schreibfunktionen machen es ideal für das Training und Testen von maschinellen Lernmodellen.
- Protokollanalyse: Parquet wird auch in Log-Analytics-Anwendungen eingesetzt, bei denen große Mengen von Log-Daten verarbeitet und analysiert werden müssen. Seine spaltenförmige Struktur erleichtert die effiziente Abfrage und Analyse von Protokolldaten.
Insgesamt ist Apache Parquet ein vielseitiges und weit verbreitetes spaltenförmiges Speicherformat, das im Big-Data-Ökosystem zahlreiche Anwendungen findet.
Das solltest Du mitnehmen
- Apache Parquet ist ein open-source, spaltenorientiertes Dateiformat und zählt zu den NoSQL Datenbanken.
- Spaltenorientiert bedeutet, dass die Daten spaltenweise und nicht zeilenweise abgespeichert werden.
- Dadurch ergeben sich diverse Vorteile, wie effizientere Datenkomprimierung oder schnellere Abfragezeiten.
- Im Vergleich zu CSV ist es vor allem dann besser geeignet, wenn große Datenmengen verarbeitet werden sollen, da Ressourcen effizienter genutzt werden.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Parquet

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.