Multicollinearity is a statistical issue that arises when independent variables in a regression model are highly correlated, making it difficult to isolate the effect of a single independent variable on the dependent variable. It is a common problem in statistical analysis and can lead to unreliable and unstable regression models.
This article will explore the concept of multicollinearity, its causes, and consequences, and how to detect and handle it in regression analysis. We will also discuss the impact of it on model performance and interpretation of the results.
What is Multicollinearity?
Multicollinearity is a statistical phenomenon that occurs when two or more predictor variables in a regression model are highly correlated, making it difficult to determine their individual effects on the outcome variable. In other words, it means a linear relationship among the independent variables in a regression model.
This can cause several issues in the analysis, such as making it difficult to estimate the coefficients of the regression equation, leading to unstable and unreliable estimates of the coefficients, and making it challenging to interpret the results of the regression analysis. Therefore, it is essential to identify and address multicollinearity in regression analysis to obtain accurate and reliable results.
What are the causes of Multicollinearity?
Multicollinearity, the phenomenon where predictor variables in a regression model are highly correlated, can arise due to several reasons. Understanding the causes of it is crucial for identifying and addressing this issue effectively.
- Overlapping Variables: Including multiple variables that measure similar aspects of the same phenomenon can lead to multicollinearity. For example, using both heights in inches and height in centimeters as predictor variables in a model.
- Data Transformation: In some cases, performing certain mathematical transformations on variables can introduce the problem. For instance, taking the square or logarithm of a variable that is already highly correlated with another predictor.
- Categorical Variables: When dealing with categorical variables, multicollinearity can occur if one category is represented by a combination of other categories. This is known as the dummy variable trap.
- Measurement Errors: Inaccurate or imprecise measurement of variables can contribute to the problem. Measurement errors that are consistently present across multiple variables can lead to high correlations.
- Sample Selection: If the data collection process or sample selection is biased, it can introduce multicollinearity. For example, selecting a sample that is not representative of the population or excluding certain groups can result in correlated predictor variables.
- Data Aggregation: Aggregating data at different levels can lead to multicollinearity. For instance, including both individual-level and group-level variables in a regression model.
- Interaction Terms: Including interaction terms (product of two or more variables) can create multicollinearity if the involved variables are already correlated.
Identifying the causes of multicollinearity can help in mitigating the issue by employing appropriate techniques such as feature selection, data transformation, or using regularization methods like ridge regression. It is important to carefully analyze the data, consider the research context, and consult domain experts to address the problem effectively.
Which tools can you use to detect Multicollinearity?
Detecting multicollinearity is a crucial step in regression analysis as it helps ensure the reliability and accuracy of the results. There are several techniques available for identifying multicollinearity in a dataset.
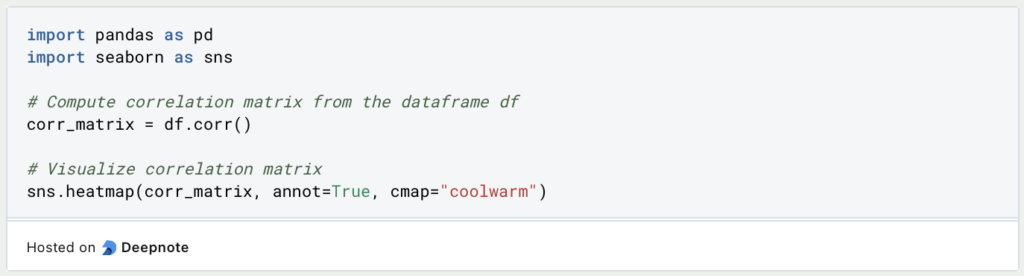
One common approach is to compute the correlation matrix, which measures the linear relationship between each pair of predictor variables. High correlation coefficients (close to 1 or -1) indicate strong linear association and may potentially lead to a problem. Visualizing the correlation matrix using a heatmap can provide a clear overview of the correlations.
Another method is to calculate the Variance Inflation Factor (VIF) for each predictor variable. VIF quantifies how much the variance of an estimated regression coefficient is increased due to multicollinearity. Higher VIF values suggest a stronger effect. Variables with VIF values above a certain threshold, such as 5 or 10, may indicate multicollinearity.
Eigenvalues and the condition number of the correlation matrix can also be examined. If one or more eigenvalues are close to zero or significantly smaller than others, it suggests the presence of multicollinearity. The condition number, calculated as the square root of the ratio of the largest eigenvalue to the smallest eigenvalue, indicates the severity of the problem. A large condition number (>30) implies high multicollinearity.
Tolerance, which is the reciprocal of the VIF, can be analyzed as well. Variables with low tolerance values (close to 0) indicate high multicollinearity. Similarly, considering the proportion of variance explained by each predictor variable can provide insights into the problem. Variables with small variance proportions contribute less unique information and may be correlated with other predictors.
Principal Component Analysis (PCA) is another useful technique. It identifies linear combinations of predictor variables that explain most of the variance in the dataset. If only a few principal components capture a significant portion of the variability, it suggests the presence of multicollinearity. Plotting the scree plot and examining the explained variance ratio can assist in determining the number of principal components affected by multicollinearity.
Additionally, regression coefficients and hypothesis testing can provide insights. Large standard errors and inconsistent signs of the regression coefficients may indicate multicollinearity. Conducting hypothesis tests on the regression coefficients can help evaluate their significance and stability.
While it affects the interpretation and precision of the coefficients, it does not invalidate the entire regression analysis. If multicollinearity is detected, strategies such as feature selection, data transformation, or the use of regularization techniques like ridge regression can help mitigate the issue. It is important to consider domain knowledge and specific context when addressing the problem effectively.
How can you use Python in the detection process?
Detecting multicollinearity in Python can be done using various methods. In all these examples, we assume that you have stored your data in the variable “df” which is a Pandas DataFrame. You can use these examples by replacing the placeholders with the name of your specific columns. Here, we’ll discuss a few common approaches:
- Correlation Matrix: Compute the correlation matrix of the predictor variables using the
corr()function from the pandas library. Visualize the correlation matrix using a heatmap to identify highly correlated variables.
- Variance Inflation Factor (VIF): Calculate the VIF for each predictor variable to assess the magnitude of the problem. Higher VIF values indicate a stronger correlation between variables.

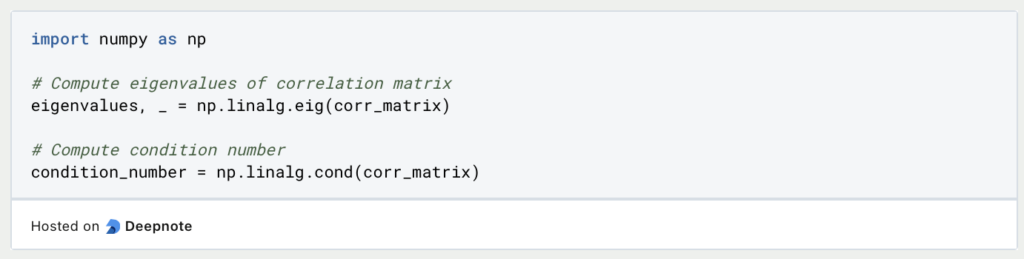
- Eigenvalues and Condition Number: Analyze the eigenvalues of the correlation matrix or compute the condition number. If eigenvalues are close to zero or the condition number is high, multicollinearity may be present.
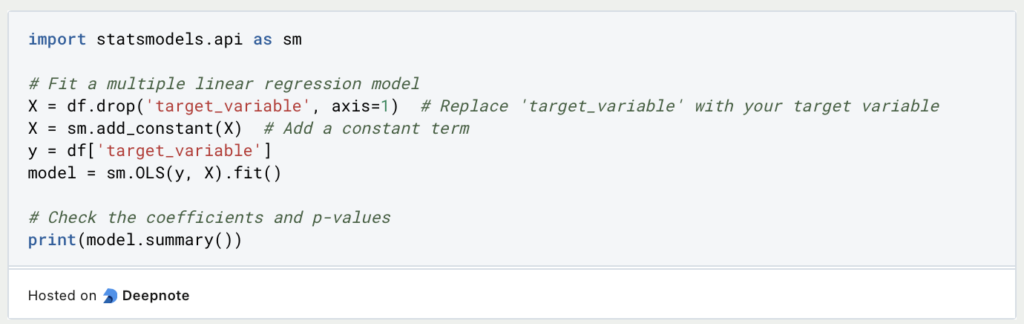
- Regression Models: Fit a regression model and examine the coefficients and their significance. Large coefficients or low p-values can indicate multicollinearity issues.
By applying these techniques, you can identify the problem in your dataset and take appropriate steps to address it before building regression models. Remember to consider the specific context of your data and the desired level of tolerance.
What is the effect of Multicollinearity on Regression Analysis?
Multicollinearity can have significant effects on the results of a regression analysis. When two or more predictor variables are highly correlated, it becomes difficult for the regression model to determine which variable is having the most impact on the response variable. This can lead to incorrect and unstable coefficient estimates, making it hard to interpret the results of the analysis.
One common problem is that multicollinearity can lead to coefficients with the wrong signs or magnitudes. For example, if two variables are highly correlated, the regression model may give one variable a positive coefficient and the other a negative coefficient, even if both variables have a positive relationship with the response variable. This is because the model cannot distinguish the effect of each variable from the other.
Multicollinearity can also lead to wider confidence intervals for the coefficients, making it harder to detect statistically significant effects. This can result in a reduced ability to predict the response variable accurately. Additionally, multicollinearity can lead to unstable and inconsistent coefficients across different samples, which can make it difficult to generalize the results to other populations.

It is important to note that the presence of multicollinearity does not necessarily mean that the regression model is invalid. However, it does mean that the results should be interpreted with caution and that efforts should be made to reduce it if possible.
How to interpret the Regression Results if there is Multicollinearity?
In the presence of multicollinearity, the interpretation of regression results can become difficult. This is because the problem can inflate the standard errors of regression coefficients and lead to unstable and unreliable estimates.
When two or more variables are highly correlated, it can be challenging to determine which variable(s) have a significant effect on the response variable. As a result, the regression coefficients may be difficult to interpret, as their values may be inconsistent with what we expect based on our understanding of the relationship between the predictor and response variables.
One common issue in interpreting regression results in the presence of multicollinearity is the problem of identifying the most important predictor variables. The regression coefficients may be very large, but the standard errors may also be very large, making it difficult to determine the true effect of each predictor variable on the response variable.
Another issue is the possibility of obtaining unstable regression coefficients, which can lead to incorrect or misleading conclusions. For example, a variable that has a small but significant effect on the response variable in a model with no multicollinearity may have a large and insignificant coefficient.
Overall, it is important to carefully evaluate regression results in the presence of multicollinearity and consider alternative methods, such as regularization techniques or principal component analysis, to address the problem.
What are examples of the problems caused by Multicollinearity?
Multicollinearity can cause several real-world problems, and it is essential to address them to obtain accurate regression results. Here are some examples:
- In the field of medical research, multiple predictor variables such as age, sex, and medical history may be included in a regression model to predict the outcome of a disease. However, if these predictor variables are highly correlated with each other, the regression coefficients may become unstable, making it difficult to determine the effect of each variable.
- In the field of finance, a common problem is the multicollinearity between the independent variables in a financial model. For example, in a model predicting stock prices, several variables such as earnings per share, price-earnings ratio, and dividend yield may be highly correlated. This can lead to unstable regression coefficients and inaccurate predictions.
There are several ways to solve the problem of multicollinearity in regression analysis, such as:
- Data collection: Collecting more data can help to reduce the correlation between the independent variables and improve the accuracy of the regression model.
- Variable selection: Removing highly correlated variables from the model can help to reduce multicollinearity and improve the stability of the regression coefficients.
- Data transformation: Transforming the data by standardizing the variables or applying a transformation such as logarithmic or square root can help to reduce the correlation between the independent variables.
- Ridge regression: Ridge regression is a technique used to penalize the regression coefficients, which can help to reduce the impact of multicollinearity and improve the stability of the regression model.
By addressing the problem, we can obtain accurate regression results and make informed decisions based on the analysis.
What are common misconceptions?
Common misconceptions and pitfalls in dealing with multicollinearity include:
- Ignoring multicollinearity: One common mistake is to ignore the problem and continue with the regression analysis. This can lead to unreliable results and incorrect conclusions.
- Removing variables based solely on high correlation: Just because two variables are highly correlated does not necessarily mean they are redundant. It is important to look at the contribution of each variable to the model and assess its importance.
- Only considering pairwise correlations: Multicollinearity can exist even if there are no pairwise correlations between the variables. It is important to consider the overall correlation structure of the data.
- Using stepwise regression: Stepwise regression methods can lead to instability in the model and may not accurately capture the relationship between the predictors and the response variable.
- Assuming causality based on correlation: High correlation between variables does not necessarily imply a causal relationship. It is important to carefully consider the underlying mechanisms and context of the variables.
To avoid these pitfalls, it is important to use appropriate statistical methods to detect and address multicollinearities, such as variance inflation factors (VIF), principal component analysis (PCA), or ridge regression. It is also important to carefully consider the underlying theory and context of the variables and to interpret the results in a cautious and nuanced manner.
This is what you should take with you
- Multicollinearity is a common problem in regression analysis, where independent variables are highly correlated with each other, causing issues in the interpretation of the regression results.
- The presence of multicollinearity can lead to inflated standard errors, unreliable estimates of regression coefficients, and difficulties in identifying the most important predictors.
- Multicollinearity can be detected using statistical methods such as correlation matrices, variance inflation factors (VIF), and eigenvalue decomposition.
- Some common strategies for dealing with multicollinearity include dropping one of the correlated variables, combining the variables into a single predictor, and using dimensionality reduction techniques such as principal component analysis (PCA).
- Misconceptions and pitfalls include assuming that correlation among predictors implies multicollinearity, ignoring the problem and interpreting the results without considering the impact of multicollinearity, and using incorrect methods for detecting and dealing with the problem.
- Overall, it is important to understand and address multicollinearity in regression analysis to obtain accurate and reliable results.

What is the F-Statistic?
Explore the F-statistic: Its Meaning, Calculation, and Applications in Statistics. Learn to Assess Group Differences.

What is Gibbs Sampling?
Explore Gibbs sampling: Learn its applications, implementation, and how it's used in real-world data analysis.

What is a Bias?
Unveiling Bias: Exploring its Impact and Mitigating Measures. Understand, recognize, and address bias in this insightful guide.

What is the Variance?
Explore variance's role in statistics and data analysis. Understand how it measures data dispersion.

What is the Kullback-Leibler Divergence?
Explore Kullback-Leibler Divergence, a vital metric in information theory and machine learning, and its applications.

What is the Maximum Likelihood Estimation?
Unlocking insights: Understand Maximum Likelihood Estimation (MLE), a potent statistical tool for parameter estimation and data modeling.
Other Articles on the Topic of Multicollinearity
You can find a detailed article about Multicollinearity from the University of Kassel here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.