In den letzten Jahren hat sich das maschinelle Lernen zu einem beliebten Bereich in der Welt der Informatik und Datenanalytik entwickelt. Es wird verwendet, um Modelle zu erstellen, die Vorhersagen machen, Muster erkennen und Daten auf der Grundlage verschiedener Merkmale klassifizieren können. Bei der Erstellung eines Modells für maschinelles Lernen geht es jedoch nicht nur darum, einen Algorithmus mit Rohdaten zu füttern und Ergebnisse zu erhalten. Einer der wichtigsten Schritte bei der Erstellung eines erfolgreichen Modells für maschinelles Lernen ist das Feature Engineering. Dabei handelt es sich um den Prozess der Auswahl und Umwandlung von Rohdaten in Merkmale, die von einem Algorithmus verwendet werden können, um genaue Vorhersagen zu treffen.
In diesem Artikel werden wir in die Welt des Feature Engineering eintauchen und erörtern, was es ist, warum es wichtig ist, welche Techniken verwendet werden und welche Herausforderungen bei diesem Prozess auftreten. Außerdem werden wir einige Beispiele für das Feature Engineering in Python untersuchen.
Was ist Feature Engineering?
Feature Engineering ist der Prozess der Auswahl und Umwandlung von Rohdaten in Merkmale, die von einem Algorithmus für maschinelles Lernen verwendet werden können, um genaue Vorhersagen zu treffen. Das Ziel des Feature Engineering ist es, die wichtigsten Informationen aus den Rohdaten zu identifizieren und zu extrahieren und sie in ein Format umzuwandeln, das von Algorithmen für maschinelles Lernen leicht verstanden werden kann.
Die Rohdaten können in verschiedenen Formen vorliegen, z. B. als numerische Daten, kategorische Daten und Textdaten. Für diese unterschiedlichen Datentypen sind verschiedene Techniken des Feature Engineering erforderlich, um sie in ein Format zu konvertieren, das von Algorithmen des maschinellen Lernens verwendet werden kann.
Bei numerischen Daten kann der Prozess des Feature-Engineering beispielsweise die Skalierung der Merkmale auf einen gemeinsamen Bereich, die Normalisierung der Merkmale oder die Umwandlung der Merkmale mithilfe mathematischer Funktionen umfassen. Bei kategorialen Daten kann der Prozess die Umwandlung der Kategorien in numerische Werte, die One-Hot-Codierung der Kategorien oder die Verwendung von Zielcodierungstechniken umfassen. Bei Textdaten kann der Prozess die Umwandlung des Textes in numerische Vektoren mithilfe von Techniken wie Bag-of-Words, TF-IDF oder Worteinbettungen umfassen.
Insgesamt besteht der Zweck des Feature Engineering darin, eine Reihe von Merkmalen zu erstellen, die die wichtigsten Informationen aus den Rohdaten erfassen, und diese Merkmale in ein Format umzuwandeln, das von Algorithmen für maschinelles Lernen leicht verstanden werden kann. Auf diese Weise können wir Modelle erstellen, die genau und effektiv sind und Vorhersagen für neue Daten machen können.
Welche Arten von Daten werden beim Feature Engineering verwendet?
Beim Feature Engineering können verschiedene Datentypen verwendet werden, darunter numerische Daten, kategorische Daten und Textdaten. Jede Art von Daten erfordert unterschiedliche Techniken, um Merkmale effektiv zu entwickeln.
- Numerische Daten: Numerische Daten werden als kontinuierliche oder diskrete Werte dargestellt. Beispiele für numerische Daten sind Temperatur, Größe, Gewicht und Alter. Der Prozess des Feature Engineering für numerische Daten kann Techniken wie Skalierung, Normalisierung und Transformation beinhalten. Bei der Skalierung werden beispielsweise alle Merkmale auf dieselbe Skala gebracht, während bei der Normalisierung die Merkmale in einen Bereich zwischen 0 und 1 umgewandelt werden.
- Kategorische Daten: Kategoriale Daten stellen Variablen dar, die eine begrenzte Anzahl von Kategorien haben. Beispiele für kategoriale Daten sind Geschlecht, Bildungsgrad und Familienstand. Die Merkmalstechnik für kategoriale Daten kann Techniken wie One-Hot-Codierung und Zielcodierung umfassen. Bei der One-Hot-Codierung werden kategoriale Variablen in binäre Vektoren umgewandelt, wobei jede Kategorie durch einen eindeutigen Binärwert dargestellt wird. Bei der Zielkodierung wird jede Kategorie durch den mittleren Zielwert der entsprechenden Klasse ersetzt.
- Textdaten: Textdaten stellen menschliche Sprache dar und sind oft unstrukturiert. Beispiele für Textdaten sind Produktbewertungen, Kundenfeedback und Beiträge in sozialen Medien. Die Merkmalstechnik für Textdaten kann Techniken wie Bag-of-Words, TF-IDF und Worteinbettungen umfassen. Bei Bag-of-Words wird die Häufigkeit von Wörtern in einem Dokument gezählt und die Anzahl als Merkmal verwendet. Bei TF-IDF werden die Zählungen nach ihrer inversen Dokumenthäufigkeit gewichtet, um die relevantesten Wörter zu ermitteln. Bei der Worteinbettung werden Wörter mithilfe eines neuronalen Netzes in numerische Vektoren umgewandelt.

Durch das Verständnis der verschiedenen Datentypen, die beim Feature-Engineering verwendet werden, und der Techniken, die zur Entwicklung von Merkmalen für jeden Datentyp verwendet werden, können wir effektive Merkmale erstellen, die zum Training genauer und robuster Modelle für maschinelles Lernen verwendet werden können.
Welche Techniken werden beim Feature Engineering verwendet?
Das Feature Engineering umfasst eine Reihe von Techniken zur Auswahl und Umwandlung von Rohdaten in Features, die von Algorithmen für maschinelles Lernen verwendet werden können. Hier sind einige gängige Techniken, die beim Feature-Engineering verwendet werden:
- Skalierung und Normalisierung: Bei dieser Technik werden numerische Merkmale skaliert und normalisiert, um sie vergleichbar zu machen und die Leistung von Modellen für maschinelles Lernen zu verbessern. Zu den gängigen Methoden der Skalierung und Normalisierung gehören die Min-Max-Skalierung, die Standardisierung und die Log-Transformation.
- Imputation: Unter Imputation versteht man das Auffüllen von fehlenden Daten in einem Datensatz. Fehlende Daten können mit verschiedenen Methoden wie Mittelwert-Imputation, Median-Imputation, Modus-Imputation und k-nearest neighbor Imputation aufgefüllt werden.
- Kodierung: Bei der Kodierung werden kategoriale Daten in ein Format umgewandelt, das von Algorithmen für maschinelles Lernen verwendet werden kann. Zu den gängigen Kodierungstechniken gehören One-Hot-Kodierung, Label-Kodierung und Target-Kodierung.
- Merkmalsauswahl: Bei der Merkmalsauswahl werden die wichtigsten Merkmale in einem Datensatz identifiziert und ausgewählt. Diese Technik wird verwendet, um die Anzahl der in einem Modell für maschinelles Lernen verwendeten Merkmale zu reduzieren, wodurch das Modell effizienter und weniger anfällig für Overfitting wird. Zu den gebräuchlichen Verfahren der Merkmalsauswahl gehören die Korrelationsanalyse, die rekursive Merkmalseliminierung und die Hauptkomponentenanalyse.
- Transformation: Bei der Transformation wird die Skalierung, Verteilung oder Form von Merkmalen geändert, um die Leistung von Modellen für maschinelles Lernen zu verbessern. Zu den gängigen Transformationsverfahren gehören die logarithmische Transformation, die Quadratwurzeltransformation und die Box-Cox-Transformation.
- Merkmalsextraktion: Bei der Merkmalsextraktion werden aus vorhandenen Merkmalen neue Merkmale erstellt, um die Leistung von Modellen für maschinelles Lernen zu verbessern. Zu den gängigen Merkmalsextraktionstechniken gehören die Erstellung von Interaktionstermen, polynomialen Merkmalen und statistischen Merkmalen wie Mittelwert, Median und Standardabweichung.
Durch den Einsatz dieser Techniken und die Auswahl der geeigneten Techniken für jeden Datentyp können wir Merkmale entwickeln, die effektiv sind und die Leistung von Modellen für maschinelles Lernen verbessern.
Warum ist Feature Engineering so wichtig?
Das Feature-Engineering ist ein entscheidender Schritt in der Pipeline des maschinellen Lernens, da es die Qualität der von den Modellen des maschinellen Lernens verwendeten Features bestimmt. Ein gutes Feature-Engineering kann zu Modellen führen, die genauer, effizienter und robuster sind, während ein schlechtes Feature-Engineering zu Modellen führen kann, die schlecht funktionieren oder sich nicht auf neue Daten verallgemeinern lassen.
Hier sind einige Gründe, warum Feature Engineering wichtig ist:
- Verbessert die Modellgenauigkeit: Die Entwicklung von Merkmalen hilft dabei, die wichtigsten Informationen in den Daten zu identifizieren, was für die Erstellung genauer und effektiver Modelle entscheidend ist. Durch die Entwicklung relevanter Merkmale können wir die Genauigkeit von Modellen für maschinelles Lernen verbessern und Fehler reduzieren.
- Reduziert die Modellkomplexität: Feature-Engineering kann dazu beitragen, die Komplexität von Modellen für maschinelles Lernen zu verringern, indem Features ausgewählt und umgewandelt werden, die für die jeweilige Aufgabe am relevantesten sind. Dies vereinfacht die Modelle, macht sie effizienter und weniger anfällig für Overfitting.
- Ermöglicht die Interpretierbarkeit von Modellen: Das Feature-Engineering kann dazu beitragen, Modelle besser interpretierbar zu machen, indem es Merkmale schafft, die leicht zu verstehen und zu erklären sind. Dies ist in vielen Anwendungen wichtig, z. B. im Gesundheitswesen, wo es wichtig ist, zu verstehen, wie ein Modell seine Vorhersagen trifft.
- Umgang mit fehlenden Daten: Feature-Engineering kann helfen, fehlende Daten in einem Datensatz zu verarbeiten, indem fehlende Werte imputiert oder neue Features erstellt werden, die gegenüber fehlenden Daten robust sind. Dadurch wird die Qualität der Daten verbessert, die zum Trainieren des Modells verwendet werden, was zu genaueren Vorhersagen führt.
- Erhöht die Modelleffizienz: Feature Engineering kann dazu beitragen, die Anzahl der in einem Modell verwendeten Features zu reduzieren, wodurch das Modell effizienter und schneller trainiert werden kann. Dies ist wichtig für Anwendungen, bei denen es auf Geschwindigkeit ankommt, wie z. B. bei Echtzeit-Vorhersagesystemen.
Zusammenfassend lässt sich sagen, dass das Feature-Engineering ein entscheidender Schritt in der Pipeline des maschinellen Lernens ist, da es die Qualität der von den maschinellen Lernmodellen verwendeten Features bestimmt. Durch die effektive Auswahl und Umwandlung von Merkmalen können wir Modelle erstellen, die genau, effizient und robust sind und genaue Vorhersagen für neue Daten machen können.
Was sind die Herausforderungen beim Feature Engineering?
Einer der wichtigsten Aspekte des Feature Engineering ist die Bestimmung der Wichtigkeit jedes Merkmals in einem Datensatz. Dies ist von entscheidender Bedeutung, um die relevantesten Merkmale für eine bestimmte Aufgabe zu ermitteln und sie für die Verwendung in Modellen für maschinelles Lernen auszuwählen. Die Bestimmung der Bedeutung von Merkmalen ist jedoch mit mehreren Herausforderungen verbunden:
- Korrelierte Merkmale: Korrelierte Merkmale können Probleme bei der Bestimmung der Merkmalsbedeutung verursachen, da es schwierig sein kann, zu bestimmen, welches Merkmal wirklich wichtig ist. Wenn z. B. zwei Merkmale stark korreliert sind, kann es schwierig sein zu bestimmen, welches Merkmal für die Vorhersage ausschlaggebend ist.
- Nicht lineare Beziehungen: In einigen Fällen können Merkmale nichtlineare Beziehungen mit der Zielvariablen aufweisen, was die Bestimmung ihrer Bedeutung mit linearen Modellen wie der linearen Regression erschwert.
- Hochdimensionale Daten: Bei hochdimensionalen Datensätzen, bei denen die Anzahl der Merkmale viel größer ist als die Anzahl der Beobachtungen, kann es schwierig sein, die tatsächliche Bedeutung der einzelnen Merkmale zu bestimmen.
- Verzerrungen: Bei der Bestimmung der Merkmalsbedeutung kann es zu Verzerrungen kommen, insbesondere bei modellbasierten Ansätzen. Dies kann der Fall sein, wenn das Modell auf bestimmte Arten von Merkmalen ausgerichtet ist oder wenn bestimmte Merkmale im Datensatz überrepräsentiert sind.
- Zeitaufwändig und rechenintensiv: Die Bestimmung der Merkmalsbedeutung kann eine zeit- und rechenaufwändige Aufgabe sein, insbesondere wenn Techniken wie die Permutationsbedeutung oder SHAP-Werte verwendet werden.
Um diese Herausforderungen zu meistern, ist es wichtig, die geeignete Technik zur Bestimmung der Merkmalsbedeutung auf der Grundlage des jeweiligen Datensatzes und des jeweiligen Problems sorgfältig auszuwählen. Außerdem ist es wichtig, die Ergebnisse sorgfältig zu analysieren und mögliche Verzerrungen zu berücksichtigen. Wenn wir uns diesen Herausforderungen stellen, können wir die Bedeutung jedes Merkmals in einem Datensatz besser verstehen und genauere und effizientere Modelle für maschinelles Lernen erstellen.
Wie führt man Feature Engineering in Python durch?
Feature-Engineering ist ein entscheidender Schritt in der Pipeline des maschinellen Lernens, bei dem Rohdaten in aussagekräftige Merkmale umgewandelt werden. Im Folgenden werden mehrere Beispiele für Feature-Engineering-Techniken in Python vorgestellt, zusammen mit Erklärungen und entsprechenden Codeschnipseln.
- Polynomiale Merkmale: Polynomielle Merkmale ermöglichen es uns, nicht-lineare Beziehungen in unseren Daten zu erfassen. Durch die Erstellung von Polynomkombinationen bestehender Features können wir Terme höherer Ordnung einführen. Das Modul
sklearn.preprocessingbietet die KlassePolynomialFeatures, die wie folgt verwendet werden kann:

- One-Hot-Kodierung: Die One-Hot-Codierung wird verwendet, um kategoriale Variablen als binäre Vektoren darzustellen. Jede Kategorie wird zu einem separaten Binärmerkmal, wobei der Wert 1 das Vorhandensein dieser Kategorie anzeigt und der Wert 0 das Gegenteil. Die Pandas-Bibliothek bietet die Funktion
get_dummiesfür One-Hot-Codierung:
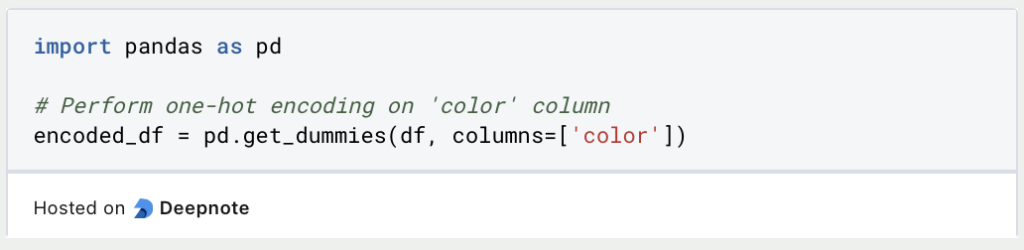
- Merkmalsskalierung: Die Skalierung von Merkmalen stellt sicher, dass die numerischen Merkmale auf einer ähnlichen Skala liegen und verhindert, dass bestimmte Merkmale andere dominieren. Zwei häufig verwendete Methoden sind Min-Max-Skalierung und Standardisierung. Hier ist ein Beispiel mit
sklearn.preprocessing:

- Extraktion von Textmerkmalen (TF-IDF): TF-IDF (Term Frequency-Inverse Document Frequency) ist eine Technik, mit der Textdaten in numerische Merkmale umgewandelt werden. Dabei werden die Wörter auf der Grundlage ihrer Häufigkeit innerhalb eines Dokuments und im gesamten Korpus gewichtet. Das Modul
sklearn.feature_extraction.textbietet die KlasseTfidfVectorizer:

- Datum- und Zeitfunktionen: Das Extrahieren aussagekräftiger Informationen aus Datums- und Zeitdaten kann in verschiedenen Anwendungen nützlich sein. Das datetime-Modul von Python bietet mehrere Methoden zum Extrahieren bestimmter Komponenten wie Tag, Monat, Jahr, Stunde und mehr:

Durch den Einsatz dieser Feature-Engineering-Techniken kannst Du die Qualität und Vorhersagekraft Deiner Machine-Learning-Modelle verbessern.
Das solltest Du mitnehmen
- Feature Engineering ist der Prozess der Auswahl und Umwandlung von Rohdaten in Features, die für Machine-Learning-Modelle relevant und informativ sind.
- Es gibt verschiedene Techniken für das Feature-Engineering, darunter Feature-Auswahl, Feature-Extraktion und Feature-Skalierung.
- Unterschiedliche Datentypen, einschließlich numerischer, kategorischer und Textdaten, erfordern unterschiedliche Techniken für das Feature Engineering.
- Feature-Engineering ist wichtig, weil es die Modellgenauigkeit verbessert, die Modellkomplexität reduziert, die Modellinterpretierbarkeit ermöglicht, fehlende Daten behandelt und die Modelleffizienz erhöht.
- Die Bestimmung der Merkmalsbedeutung ist jedoch mit einigen Herausforderungen verbunden, darunter korrelierte Merkmale, nichtlineare Beziehungen, hochdimensionale Daten, Verzerrungen und Rechenaufwand.
- Es ist wichtig, die geeignete Technik zur Bestimmung der Merkmalsbedeutung sorgfältig auszuwählen und die Ergebnisse zu analysieren, um genaue und effiziente maschinelle Lernmodelle zu erstellen.
- Ein gutes Feature-Engineering erfordert Fachwissen und Kreativität, und es ist ein iterativer Prozess, der eine kontinuierliche Verfeinerung und Verbesserung erfordert.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.

Was ist die Singular Value Decomposition?
Erkenntnisse und Muster freilegen: Lernen Sie die Leistungsfähigkeit der Singular Value Decomposition (SVD) in der Datenanalyse kennen.

Was ist die Poisson Regression?
Lernen Sie die Poisson-Regression kennen, ein statistisches Modell für die Analyse von Zähldaten, inkl. einem Beispiel in Python.

Was ist blockchain-based AI?
Entdecken Sie das Potenzial der blockchain-based AI in diesem aufschlussreichen Artikel über Künstliche Intelligenz und Blockchain.
Andere Beiträge zum Thema Feature Engineering
Einen interessanten Artikel über Feature Engineering findest Du hier auf GitHub.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.