Data Mining umfasst alle systematischen Prozesse, um Zusammenhänge oder Abhängigkeiten in Datensätzen zu erkennen, die wiederum für geschäftliche Anwendungen genutzt werden können.
Data Mining verbindet Erkenntnisse und Methoden aus verschiedensten Fachbereichen, wie der Mathematik, der Informatik oder der Statistik. In der Wissenschaft ist es ein unverzichtbarer Bestandteil bei groß angelegten Umfragen oder Experimenten, um die gewonnenen Resultate auch datentechnisch belegen zu können oder Muster in den Versuchsdaten erkennen zu können. Da große Datenmengen mittlerweile auch in vielen Unternehmen anfallen, werden solche Methoden auch immer mehr im geschäftlichen Umfeld genutzt.
Warum ist Data Mining wichtig?
Viele Unternehmen greifen heute bereits auf Business Analytics zurück und visualisieren ihre Daten mithilfe von Business Intelligence Tools, wie Power BI oder Tableau. Darüber lassen sich gut die Veränderungen von Kenngrößen wie Umsatz, Gewinn oder Lagerbestände im Blick halten. Jedoch lassen sich mit reinem Business Intelligence keine abschließenden Aussagen darüber treffen, wie sich diese Änderungen erklären lassen.
Data Mining hilft dabei die offensichtlichen Änderungen in den Daten erklärbar zu machen und die Hintergründe zu verstehen, die vielleicht selbst für die beteiligten Personen auf den ersten Blick nicht eindeutig erscheinen. Zum Beispiel könnte man Algorithmen nutzen, um herauszufinden, ob eine beobachtete Umsatzsteigerung schlussendlich auf eine Marketing-Kampagne, die gesenkten Preise oder doch auf die Modernisierung des Web Shop Frontends zurückzuführen ist. Mögliche positive Zusammenhänge zwischen den drei Maßnahmen lassen sich nur über dedizierte Data Mining Methoden herausfinden.
Was sind die verschiedenen Arten von Data Mining?
Je nachdem welche Art von Daten untersucht werden sollen, gibt es verschiedene Herangehensweisen und Algorithmen, die genutzt werden können. Dies ist auch maßgeblich davon abhängig, welcher Zusammenhang in den Daten besteht oder zumindest vermutet wird:
- Klassifizierung: Wenn einzelne Datenpunkte zu verschiedenen Kategorien zugeordnet werden sollen, helfen Algorithmen, wie Decision Trees oder Random Forests. Sie sind in der Lage, die Klassifzierungsregeln und -merkmale selbstständig aus den Daten zu lernen.
- Clustering: Dieses Verfahren ist relativ ähnlich zur Klassifizierung jedoch nicht dasselbe. Beim Clustering werden einzelne Datensätze Cluster zugeordnet, wenn sie gemeinsame Charakteristiken haben. Beim k-Means Clustering beispielsweise, muss lediglich die Anzahl der zu suchenden Cluster vorgegeben werden und der Algorithmus macht dann selbstständig die Zuordnung.
- Regression: Bei dieser Methode wird versucht mithilfe des Datensatzes neue Datenpunkte anhand von gegebenen Variablen zu errechnen. Dadurch lässt sich beispielsweise herausfinden, wie groß der Einfluss einer Variablen auf das zu erklärende Element ist. Beispiele hierfür sind die lineare oder die logistische Regression.
- Neural Networks: Diese Algorithmen versuchen sich die Funktionsweise des menschlichen Gehirns zunutze zu machen, um komplexe Zusammenhänge aus Datensätzen zu erlernen und auf neue Daten anzuwenden. Je nachdem wie diese Netzwerke im Detail aufgebaut sind, unterscheidet man verschiedene Arten, wie beispielsweise ein Convolutional Neural Network oder ein Recurrent Neural Network.
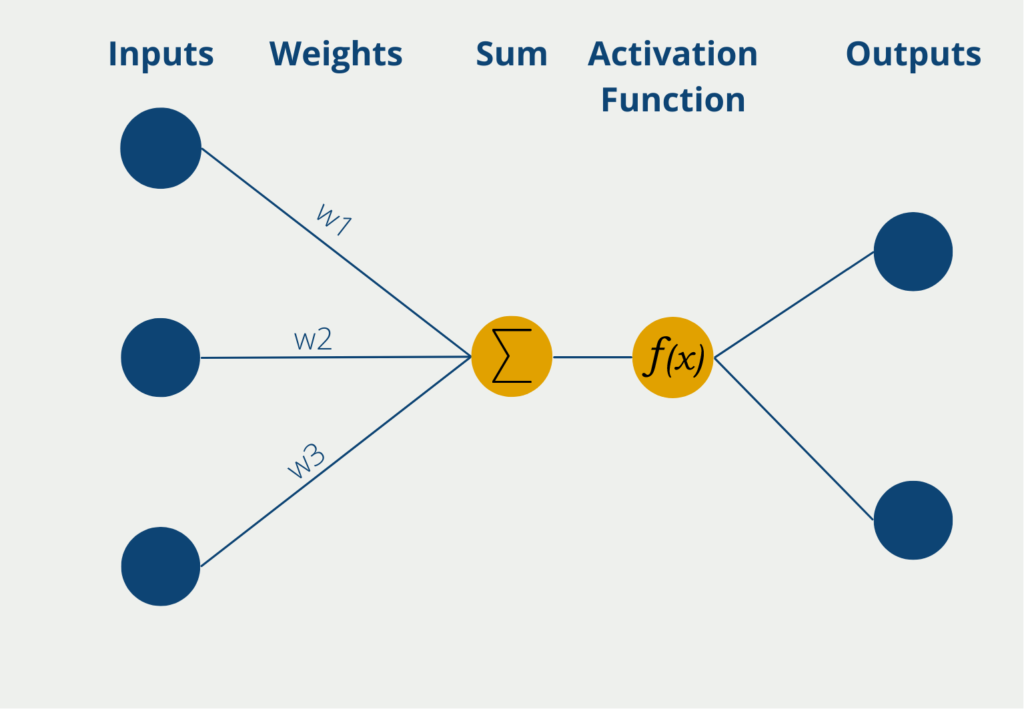
Was sind die Vorteile von Data Mining?
Innerhalb des geschäftlichen Umfelds gibt es einige Vorteile, die mithilfe von Data Mining erreicht werden können:
- Effektive Marketing- und Vertriebsstrategien: Mithilfe von Data Mining kann das Verhalten des Kunden besser verstanden oder gewisse Kundensegmente gebildet werden. Dadurch lassen sich Maßnahmen im Marketing oder Vertrieb besser auf die Kunden zuschneiden und führen so auch zu höheren Erfolgsquoten.
- Schnellerer Kundenservice: Durch gezielte Analyse der eingehenden Service Anfragen können Prozesse im Kundenservice automatisiert und die menschlichen Kollegen damit entlastet werden. Dadurch können aufkommende Fragen des Kunden direkt beantwortet und lange Wartezeiten vermieden werden.
- Verhinderung von Produktionsausfällen: Die Auswertung von Produktionsdaten können zu Algorithmen führen, die bereits frühzeitig mögliche Probleme und bevorstehende Ausfälle im Produktionsprozess erkennen. Wenn diese bereits vor Auftreten bekannt sind, können gezielte Reparaturen oder Eingriffe den Ausfall der Maschine verhindern.
- Einsparung von Kosten: Durch eine Auswertung der Geschäftsprozesse lassen sich Ineffizienzen und kostenintensive Prozessschritte erkennen und optimieren. Dadurch können möglicherweise Wartezeiten oder Fehler vermieden werden, was zu einer Kosteneinsparung führt.
Vor welchen Herausforderungen steht Data Mining?
Data Mining ist der Prozess der Entdeckung nützlicher Muster und Erkenntnisse aus großen Datenbeständen. Dabei werden Daten aus verschiedenen Perspektiven analysiert und zu nützlichen Informationen zusammengefasst, die für fundierte Entscheidungen genutzt werden können. Data Mining bringt jedoch auch eine Reihe von Herausforderungen mit sich. Zu den Herausforderungen des Data Mining gehören unter anderem:
- Probleme mit der Datenqualität: Data Mining ist auf qualitativ hochwertige Daten angewiesen, um genaue Erkenntnisse zu gewinnen. Wenn die Daten unvollständig, ungenau oder inkonsistent sind, sind die Ergebnisse des Data Mining möglicherweise nicht zuverlässig.
- Bedenken hinsichtlich des Datenschutzes: Mit der Zunahme von Datenschutzverletzungen und Datenschutzbestimmungen steht auch das Data Mining vor der Herausforderung, den Schutz persönlicher Daten zu gewährleisten. Datenwissenschaftler müssen sich der potenziellen Datenschutzbedenken bewusst sein und Maßnahmen zur Anonymisierung oder De-Identifizierung sensibler Daten ergreifen.
- Komplexität der Daten: Je größer und komplexer die Datensätze werden, desto schwieriger wird es, aussagekräftige Muster und Erkenntnisse zu finden. Datenwissenschaftler müssen über die nötigen Werkzeuge und Techniken verfügen, um komplexe Daten effektiv zu verwalten und zu analysieren.
- Technische Herausforderungen: Data Mining erfordert oft eine beträchtliche Menge an Rechenleistung und spezielle Softwaretools. Datenwissenschaftler müssen über die technischen Fähigkeiten verfügen, um diese Tools effektiv und effizient zu nutzen.
- Geschäftliches Verständnis: Data Mining ist nicht nur ein technischer Prozess; er erfordert auch ein tiefes Verständnis des Geschäftsbereichs und des zu lösenden Problems. Data Scientists müssen über den nötigen Geschäftssinn verfügen, um die relevanten Variablen und Erkenntnisse zu ermitteln, die den Geschäftswert steigern.
Um diese Herausforderungen zu meistern, müssen Data Scientists eine Kombination aus technischen und geschäftlichen Fähigkeiten sowie ein tiefes Verständnis für statistische Konzepte und Data-Mining-Techniken besitzen. Außerdem müssen sie sich über die neuesten Trends und Tools in diesem Bereich auf dem Laufenden halten, um sicherzustellen, dass sie die effektivsten Methoden für das Data Mining anwenden.
Was ist der Unterschied zwischen Data Mining und Machine Learning?
Data Mining und maschinelles Lernen sind zwei unterschiedliche, aber verwandte Bereiche der Datenanalyse. Beim Data Mining werden mithilfe verschiedener statistischer und computergestützter Techniken Muster und Erkenntnisse aus großen Datenbeständen gewonnen. Das Machine Learning hingegen ist ein Teilbereich der künstlichen Intelligenz (KI), der statistische Algorithmen und Modelle verwendet, damit Maschinen aus Daten lernen können, ohne explizit programmiert zu werden.
Es gibt zwar einige Überschneidungen zwischen den beiden Bereichen, aber auch einige wichtige Unterschiede:
- Umfang: Beim Data Mining geht es im Allgemeinen darum, Muster und Beziehungen in großen Datensätzen zu finden, während sich das maschinelle Lernen auf die Entwicklung von Algorithmen und Modellen konzentriert, die aus Daten lernen können, um Vorhersagen oder Klassifizierungen zu treffen.
- Techniken: Data Mining umfasst häufig Techniken wie Clustering, Assoziationsregel-Mining und die Erkennung von Anomalien, während maschinelles Lernen in der Regel Techniken wie überwachtes Lernen, unüberwachtes Lernen und verstärkendes Lernen umfasst.
- Anwendungen: Data Mining wird häufig in Bereichen wie Marketing, Finanzen und Gesundheitswesen eingesetzt, um Muster und Beziehungen zu erkennen, die als Grundlage für die Entscheidungsfindung dienen können, während maschinelles Lernen in einem breiten Spektrum von Anwendungen wie Bilderkennung, Verarbeitung natürlicher Sprache und vorausschauende Wartung eingesetzt wird.
Trotz dieser Unterschiede sind sowohl Data Mining als auch maschinelles Lernen wichtige Werkzeuge für die Arbeit mit großen Datensätzen und die Extraktion von Werten aus Daten.
Welche Tools werden im Data Mining Umfeld genutzt?
Data Mining ist ein komplexer Prozess, bei dem große Datensätze untersucht und analysiert werden, um versteckte Muster, Trends und Beziehungen aufzudecken. Um dies zu erreichen, greifen Data-Mining-Experten auf verschiedene Tools zurück, die die Gewinnung wertvoller Erkenntnisse aus Daten erleichtern. Einige der am häufigsten verwendeten Data-Mining-Tools sind:
- RapidMiner: Dieses Open-Source Data Mining-Tool bietet eine Reihe von Funktionen, darunter Datenaufbereitung, prädiktive Analysen und maschinelles Lernen.
- IBM SPSS Modeler: Dieses Tool bietet Benutzern eine Reihe von Analysefunktionen, einschließlich prädiktiver Modellierung, Entscheidungsbäumen und neuronalen Netzen.
- KNIME-Analyse-Plattform: Dieses Open-Source-Tool für die Datenanalyse bietet eine breite Palette von Funktionen, darunter Data Blending, maschinelles Lernen und Text Mining.
- SAS Enterprise Miner: Bei diesem Tool handelt es sich um eine umfassende Data-Mining-Lösung, die eine Vielzahl von Analysetechniken unterstützt, darunter Entscheidungsbäume, neuronale Netze und Regression.
- Orange: Dieses Open-Source-Data-Mining-Tool verfügt über eine intuitive Benutzeroberfläche und unterstützt eine Reihe von Data-Mining-Aufgaben, darunter Klassifizierung, Regression und Visualisierung.
- Apache Mahout: Diese Open-Source-Bibliothek für maschinelles Lernen bietet Benutzern eine Reihe skalierbarer Algorithmen für Clustering, Klassifizierung und kollaborative Filterung.
- Microsoft SQL Server Analysis Services: Dieses Tool ist eine umfassende Data Mining- und Analyseplattform, die eine Reihe von von Aufgaben unterstützt, darunter Regression, Clustering und Assoziationsregel-Mining.
Diese Data Mining Tools sind für die Gewinnung von Erkenntnissen aus großen Datensätzen unerlässlich und können in verschiedenen Branchen eingesetzt werden, z. B. im Finanzwesen, im Gesundheitswesen und im Marketing.
Das solltest Du mitnehmen
- Data Mining umfasst alle systematischen Prozesse, um Zusammenhänge oder Abhängigkeiten in Datensätzen zu erkennen.
- Es geht dabei über die reine Business Intelligence hinaus, indem es versucht Erklärungen für die Datenänderungen zu finden.
- Zu den verschiedenen Arten von Data Mining zählen unter anderem die Klassifizierung, verscheidene Arten der Regression oder Neuronale Netzwerke.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Data Mining
- Auf den Seiten des SAS Institute findest Du eine noch ausführlichere Beschreibung zu Data Mining.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.