Data preprocessing is a critical step in any data analysis or Machine Learning project. It involves preparing raw data for analysis by cleaning, transforming, and integrating it. The goal of data preprocessing is to ensure that the data is of high quality, consistent, and in the right format for analysis. In this article, we will discuss the importance of data preprocessing and the steps involved in the process.
Why is Data Preprocessing important?
Data preprocessing is important for several reasons:
- Data Quality: Data preprocessing helps to improve the quality of data by identifying and correcting errors, removing duplicates, and filling in missing values. This ensures that the data is accurate and consistent, which is crucial for making informed decisions.
- Data Integration: Often, data from multiple sources need to be integrated into a single dataset. Data preprocessing helps to merge and transform data from different sources to create a unified dataset that is ready for analysis.
- Data Reduction: In some cases, datasets can be very large and contain unnecessary or redundant information. Data preprocessing helps to reduce the size of the dataset by removing irrelevant or redundant data.
- Data Normalization: Data preprocessing helps to normalize the data by scaling it to a standard range. This ensures that the data is in the same format and can be compared across different datasets.
How can we preprocess the data?
Data preprocessing is a crucial step in any data science project that involves preparing raw data for analysis. It aims to clean, transform, and organize the data in a way that makes it more suitable for analysis.
This process involves various techniques and methods that help improve the quality and usability of the data. In this section, we will discuss some of the most important techniques used in data preprocessing.
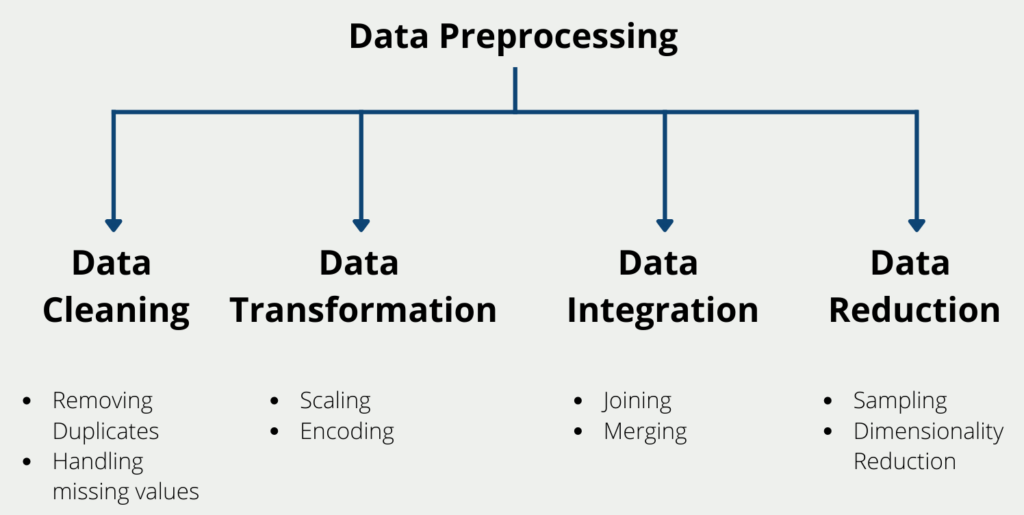
Data Cleaning
Data cleaning is the process of removing or correcting errors, missing values, and inconsistencies in the data. This step is crucial because it ensures that the data is accurate and reliable. Some common techniques used in data cleaning include:
- Removing duplicates: Duplicate data can cause inaccuracies and bias in the analysis. Therefore, it’s essential to identify and remove duplicates in the dataset.
- Handling missing values: Missing values can occur due to various reasons such as data entry errors or equipment malfunction. They can be handled by imputing them with the mean, median or mode values, or by using Machine Learning algorithms to predict missing values.
Data Transformation
Data transformation involves converting the data from one format to another, making it more suitable for analysis. This step includes techniques such as:
- Scaling: Scaling is used to transform numerical data so that it falls within a specific range. It helps to normalize the data, making it easier to compare.
- Encoding: Encoding is used to convert categorical data into numerical data that can be processed by Machine Learning algorithms. There are various encoding techniques such as one-hot encoding, label encoding, and binary encoding.
Data Integration
Data integration involves combining data from multiple sources to create a unified dataset. This step is essential when working with Big Data, where the data is stored in multiple locations. Some common techniques used in data integration include:
- Joining: Joining is the process of combining two or more tables into a single table based on a common column.
- Merging: Merging is similar to joining, but it involves combining two or more datasets based on a common attribute.
Data Reduction
Data reduction involves reducing the size of the dataset while preserving its integrity and usefulness. This step is essential when working with large datasets that can take a long time to process. Some common techniques used in data reduction include:
- Sampling: Sampling is the process of selecting a subset of the data for analysis. It can be done randomly or systematically.
- Dimensionality Reduction: Dimensionality reduction involves reducing the number of variables in the dataset while preserving its important features. It helps to reduce the complexity of the data, making it easier to analyze.
In conclusion, data preprocessing is a crucial step in any data science project that involves preparing raw data for analysis. It involves various techniques and methods that help improve the quality and usability of the data. By using these techniques, data scientists can ensure that the data is accurate, reliable, and suitable for analysis.
Which tools are used for Data Preprocessing?
There are several tools available for data preprocessing, including:
- Excel: Excel is a powerful tool for data preprocessing. It can be used to clean, transform, and integrate data. Excel also provides several functions for data analysis, including statistical analysis and data visualization.
- Python: Python is a popular programming language for data analysis and machine learning. It provides several libraries for data preprocessing, including Pandas, Numpy, and Scikit-learn.
- R: R is another programming language for data analysis and machine learning. It provides several libraries for data preprocessing, including dplyr and tidyr.
- OpenRefine: OpenRefine is a free, open-source tool for data preprocessing. It provides several functions for cleaning, transforming, and integrating data.
Which problems are you facing during the Data Preprocessing phase?
Data scientists often face several challenges during the data preprocessing stage. Some of the common problems they face include:
- Incomplete or Inconsistent Data: Sometimes, the data collected may be incomplete or inconsistent, containing missing values or inconsistent values across the dataset. This can lead to inaccurate results and bias in the analysis.
- Data Cleaning: Cleaning large datasets can be a time-consuming task, and manually identifying and correcting errors in the data can be challenging, especially when working with unstructured data.
- Feature Selection: Selecting the right features for analysis is crucial in data preprocessing, as it can affect the accuracy of the model. However, identifying the right features can be challenging, especially when working with large datasets with many features.
- Data Integration: Integrating data from multiple sources can be challenging, as the data may be in different formats or have different structures. This can lead to data inconsistencies and make it difficult to create a unified dataset.
- Data Reduction: Reducing the size of the dataset can also be challenging, especially when working with large datasets. Choosing the right sampling technique or dimensionality reduction technique is crucial in maintaining the integrity of the data while reducing its size.
By being aware of these common problems, data scientists can take steps to address them and ensure that their data is clean, accurate, and suitable for analysis.
What is Data Discretization?
Data discretization is a data preprocessing technique used to convert continuous variables into discrete variables. In other words, data discretization is a method of transforming continuous variables into categorical variables by dividing the data into intervals. This technique is used to reduce the noise in the data and to simplify the analysis.
Discretization can be done in two ways:
- Supervised Discretization: Supervised discretization is used when the target variable is known. The goal of supervised discretization is to group similar values of the target variable into a single group. This method is useful when the target variable is continuous and the goal is to predict a categorical outcome.
- Unsupervised Discretization: Unsupervised discretization is used when the target variable is unknown. This technique groups similar values of the input variables into intervals. The number of intervals can be determined based on domain knowledge or through the use of algorithms.
Discretization can be done using various methods such as Equal Width, Equal Frequency, K-Means, and Decision Trees. The Equal Width method divides the range of the data into intervals of equal width, while the Equal Frequency method divides the data into intervals with an equal number of observations. The K-Means algorithm uses clustering to group similar values of the input variables, and the Decision Trees algorithm uses decision rules to group similar values of the input variables.
Discretization is commonly used in data mining, Machine Learning, and statistical analysis. It is a useful technique to reduce the amount of noise in the data and simplify the analysis. However, it is important to choose the appropriate discretization method for the data at hand and to be aware of the limitations of the technique.
Why do Machine Learning models need Data Preprocessing?
Machine learning models need data preprocessing because:
- Data may contain missing values, outliers, or noise, which can affect the performance of the model.
- Data may be in different formats or units, making it difficult to compare and analyze.
- Data may have a large number of features, some of which may be irrelevant or redundant, which can lead to overfitting.
- Data may be unbalanced, with some classes having much fewer samples than others, which can bias the model towards the majority class.
- Data may contain categorical variables that need to be converted to numerical values before being used in the model.
- Data may need to be scaled or normalized to ensure that all features are on a comparable scale.
By performing data preprocessing, we can improve the quality of the data, reduce the risk of errors, and increase the accuracy of the machine learning model.
This is what you should take with you
- Data preprocessing is a crucial step in any data science project.
- It involves preparing the data for analysis by cleaning, transforming, and organizing it.
- Common techniques used in data preprocessing include data cleaning, feature scaling, data discretization, and feature engineering.
- Data preprocessing can improve the accuracy of machine learning models by removing noise and irrelevant information from the data.
- The quality of the output of machine learning models is highly dependent on the quality of the preprocessed data.
- In summary, data preprocessing is an essential step that should not be overlooked in any data science project.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of Data Preprocessing
Please find a detailed article on how to do data preprocessing in Scikit-Learn here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.