Das Data Preprocessing ist ein entscheidender Schritt in jedem Datenanalyse- oder Machine Learning-Projekt. Dabei werden die Rohdaten für die Analyse vorbereitet, indem sie bereinigt, transformiert und integriert werden. Das Ziel des Data Preprocessings ist es, sicherzustellen, dass die Daten von hoher Qualität, konsistent und im richtigen Format für die Analyse sind. In diesem Artikel werden wir die Bedeutung des Data Preproessings und die einzelnen Schritte dieses Prozesses erörtern.
Warum ist das Data Preprocessing wichtig?
Die Datenvorverarbeitung ist aus mehreren Gründen wichtig:
- Datenqualität: Das Data Preprocessing trägt dazu bei, die Qualität der Daten zu verbessern, indem Fehler identifiziert und korrigiert, Duplikate entfernt und fehlende Werte ergänzt werden. Dadurch wird sichergestellt, dass die Daten genau und konsistent sind, was für fundierte Entscheidungen unerlässlich ist.
- Datenintegration: Oft müssen Daten aus mehreren Quellen in einen einzigen Datensatz integriert werden. Das Data Preprocessing hilft bei der Zusammenführung und Umwandlung von Daten aus verschiedenen Quellen, um einen einheitlichen Datensatz zu erstellen, der für die Analyse bereit ist.
- Datenreduzierung: In manchen Fällen können Datensätze sehr groß sein und unnötige oder redundante Informationen enthalten. Das Data Preprocessing hilft, die Größe des Datensatzes zu reduzieren, indem irrelevante oder redundante Daten entfernt werden.
- Normalisierung der Daten: Die Datenvorverarbeitung hilft bei der Normalisierung der Daten durch Skalierung auf einen Standardbereich. Dadurch wird sichergestellt, dass die Daten das gleiche Format haben und über verschiedene Datensätze hinweg verglichen werden können.
Wie können wir die Daten vorverarbeiten?
Das Data Preprocessing ist ein entscheidender Schritt in jedem Data-Science-Projekt, bei dem Rohdaten für die Analyse vorbereitet werden. Sie zielt darauf ab, die Daten zu bereinigen, umzuwandeln und so zu organisieren, dass sie für die Analyse besser geeignet sind.
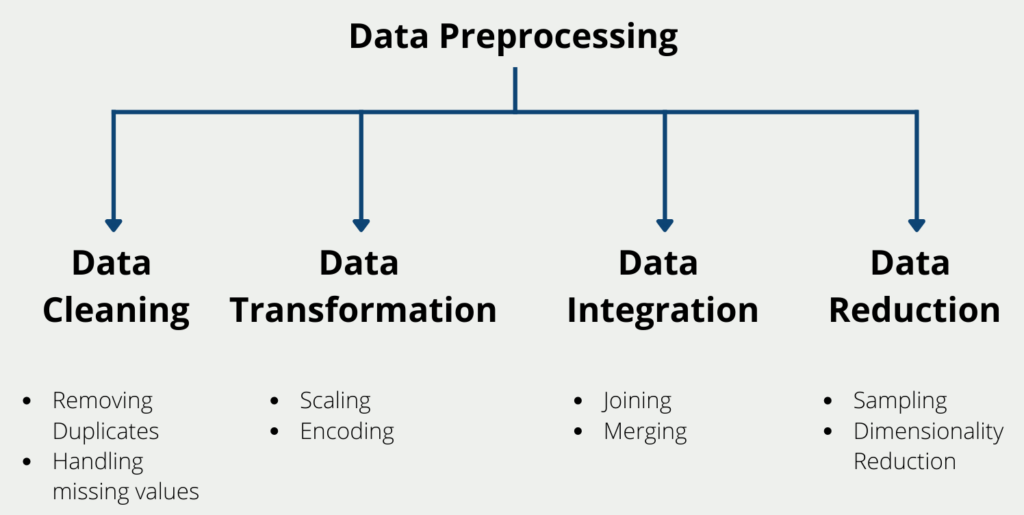
Dieser Prozess umfasst verschiedene Techniken und Methoden, die dazu beitragen, die Qualität und Verwendbarkeit der Daten zu verbessern. In diesem Abschnitt erörtern wir einige der wichtigsten Techniken, die bei der Vorverarbeitung von Daten zum Einsatz kommen.
Datenbereinigung
Bei der Datenbereinigung werden Fehler, fehlende Werte und Unstimmigkeiten in den Daten entfernt oder korrigiert. Dieser Schritt ist entscheidend, da er sicherstellt, dass die Daten genau und zuverlässig sind. Einige gängige Techniken zur Datenbereinigung sind:
- Entfernen von Duplikaten: Doppelte Daten können zu Ungenauigkeiten und Verzerrungen in der Analyse führen. Daher ist es wichtig, Duplikate im Datensatz zu identifizieren und zu entfernen.
- Behandlung fehlender Werte: Fehlende Werte können aus verschiedenen Gründen auftreten, z. B. aufgrund von Dateneingabefehlern oder Gerätefehlfunktionen. Sie können durch Imputation mit dem Mittelwert, Median oder Modus oder durch Verwendung von Algorithmen des maschinellen Lernens zur Vorhersage fehlender Werte behandelt werden.
Datentransformation
Bei der Datentransformation werden die Daten von einem Format in ein anderes umgewandelt, um sie für die Analyse besser geeignet zu machen. Dieser Schritt umfasst Techniken wie:
- Skalierung: Die Skalierung dient dazu, numerische Daten so umzuwandeln, dass sie in einen bestimmten Bereich fallen. Sie trägt zur Normalisierung der Daten bei und macht sie so leichter vergleichbar.
- Kodierung: Mit Hilfe der Kodierung werden kategoriale Daten in numerische Daten umgewandelt, die von Algorithmen des maschinellen Lernens verarbeitet werden können. Es gibt verschiedene Kodierungstechniken wie One-Hot-Kodierung, Label-Kodierung und binäre Kodierung.
Datenintegration
Bei der Datenintegration werden Daten aus verschiedenen Quellen kombiniert, um einen einheitlichen Datensatz zu erstellen. Dieser Schritt ist bei der Arbeit mit Big Data, bei der die Daten an verschiedenen Orten gespeichert sind, von entscheidender Bedeutung. Zu den gängigen Techniken der Datenintegration gehören:
- Joining: Beim Joining werden zwei oder mehr Tabellen auf der Grundlage einer gemeinsamen Spalte zu einer einzigen Tabelle kombiniert.
- Zusammenführen: Das Merging ähnelt dem Joining, aber es beinhaltet die Kombination von zwei oder mehr Datensätzen auf der Grundlage eines gemeinsamen Attributs.
Datenreduzierung
Bei der Datenreduzierung wird die Größe des Datensatzes unter Beibehaltung seiner Integrität und Nützlichkeit reduziert. Dieser Schritt ist unerlässlich bei der Arbeit mit großen Datensätzen, deren Verarbeitung viel Zeit in Anspruch nehmen kann. Einige gängige Techniken zur Datenreduzierung sind:
- Sampling: Bei der Stichprobenziehung wird eine Teilmenge der Daten für die Analyse ausgewählt. Dies kann zufällig oder systematisch geschehen.
- Dimensionalitätsreduktion: Bei der Dimensionalitätsreduktion wird die Anzahl der Variablen im Datensatz reduziert, während die wichtigen Merkmale erhalten bleiben. Sie trägt dazu bei, die Komplexität der Daten zu verringern, was ihre Analyse erleichtert.
Zusammenfassend lässt sich sagen, dass die Datenvorverarbeitung ein entscheidender Schritt in jedem Data-Science-Projekt ist, bei dem Rohdaten für die Analyse vorbereitet werden. Sie umfasst verschiedene Techniken und Methoden, die dazu beitragen, die Qualität und Verwendbarkeit der Daten zu verbessern. Durch den Einsatz dieser Techniken können Datenwissenschaftler sicherstellen, dass die Daten genau, zuverlässig und für die Analyse geeignet sind.
Welche Tools werden für die Datenvorverarbeitung verwendet?
Für die Datenvorverarbeitung stehen mehrere Tools zur Verfügung, darunter:
- Excel: Excel ist ein leistungsstarkes Tool für das Data Preprocessing. Es kann verwendet werden, um Daten zu bereinigen, umzuwandeln und zu integrieren. Excel bietet auch mehrere Funktionen für die Datenanalyse, einschließlich statistischer Analysen und Datenvisualisierung.
- Python: Python ist eine beliebte Programmiersprache für Datenanalyse und maschinelles Lernen. Sie bietet mehrere Bibliotheken für die Datenvorverarbeitung, darunter Pandas, NumPy und Scikit-learn.
- R: R ist eine weitere Programmiersprache für die Datenanalyse und das maschinelle Lernen. Sie bietet mehrere Bibliotheken für die Datenvorverarbeitung, darunter dplyr und tidyr.
- OpenRefine: OpenRefine ist ein kostenloses, quelloffenes Tool für das Data Preprocessing. Es bietet mehrere Funktionen zum Bereinigen, Transformieren und Integrieren von Daten.
Mit welchen Problemen sind Sie während des Data Preprocessing konfrontiert?
Datenwissenschaftler stehen in der Phase des Data Preprocessing häufig vor verschiedenen Herausforderungen. Einige der häufigsten Probleme, mit denen sie konfrontiert werden, sind:
- Unvollständige oder inkonsistente Daten: Manchmal sind die gesammelten Daten unvollständig oder inkonsistent und enthalten fehlende Werte oder inkonsistente Werte im gesamten Datensatz. Dies kann zu ungenauen Ergebnissen und Verzerrungen in der Analyse führen.
- Datenbereinigung: Das Bereinigen großer Datensätze kann eine zeitaufwändige Aufgabe sein, und das manuelle Erkennen und Korrigieren von Fehlern in den Daten kann eine Herausforderung darstellen, insbesondere bei der Arbeit mit unstrukturierten Daten.
- Auswahl von Merkmalen: Die Auswahl der richtigen Merkmale für die Analyse ist beim Data Preprocessing entscheidend, da sie die Genauigkeit des Modells beeinflussen kann. Die Identifizierung der richtigen Merkmale kann jedoch eine Herausforderung darstellen, insbesondere bei der Arbeit mit großen Datensätzen mit vielen Merkmalen.
- Datenintegration: Die Integration von Daten aus verschiedenen Quellen kann eine Herausforderung sein, da die Daten möglicherweise in unterschiedlichen Formaten vorliegen oder unterschiedliche Strukturen aufweisen. Dies kann zu Dateninkonsistenzen führen und die Erstellung eines einheitlichen Datensatzes erschweren.
- Datenreduzierung: Die Verkleinerung des Datensatzes kann ebenfalls eine Herausforderung darstellen, insbesondere bei der Arbeit mit großen Datensätzen. Die Wahl des richtigen Stichprobenverfahrens oder der richtigen Technik zur Dimensionalitätsreduzierung ist entscheidend für die Wahrung der Integrität der Daten bei gleichzeitiger Reduzierung ihres Umfangs.
Wenn sich Datenwissenschaftler dieser häufigen Probleme bewusst sind, können sie Maßnahmen ergreifen, um sie zu lösen und sicherzustellen, dass ihre Daten sauber, genau und für die Analyse geeignet sind.
Was ist Datendiskretisierung?
Bei der Datendiskretisierung handelt es sich um eine Technik des Data Preprocessing, mit der kontinuierliche Variablen in diskrete Variablen umgewandelt werden. Mit anderen Worten, die Datendiskretisierung ist eine Methode zur Umwandlung von kontinuierlichen Variablen in kategorische Variablen durch Unterteilung der Daten in Intervalle. Diese Technik wird eingesetzt, um das Rauschen in den Daten zu reduzieren und die Analyse zu vereinfachen.
Die Diskretisierung kann auf zwei Arten erfolgen:
- Überwachte Diskretisierung: Die überwachte Diskretisierung wird verwendet, wenn die Zielvariable bekannt ist. Das Ziel der überwachten Diskretisierung ist es, ähnliche Werte der Zielvariablen in einer einzigen Gruppe zusammenzufassen. Diese Methode ist nützlich, wenn die Zielvariable kontinuierlich ist und das Ziel darin besteht, ein kategoriales Ergebnis vorherzusagen.
- Unüberwachte Diskretisierung: Die unüberwachte Diskretisierung wird verwendet, wenn die Zielvariable unbekannt ist. Bei dieser Technik werden ähnliche Werte der Eingabevariablen in Intervalle gruppiert. Die Anzahl der Intervalle kann auf der Grundlage von Fachwissen oder durch die Verwendung von Algorithmen bestimmt werden.
Die Diskretisierung kann mit verschiedenen Methoden durchgeführt werden, z. B. Gleiche Breite, Gleiche Häufigkeit, K-Means und Entscheidungsbäume. Bei der Methode der gleichen Breite wird der Bereich der Daten in Intervalle gleicher Breite unterteilt, während bei der Methode der gleichen Häufigkeit die Daten in Intervalle mit einer e
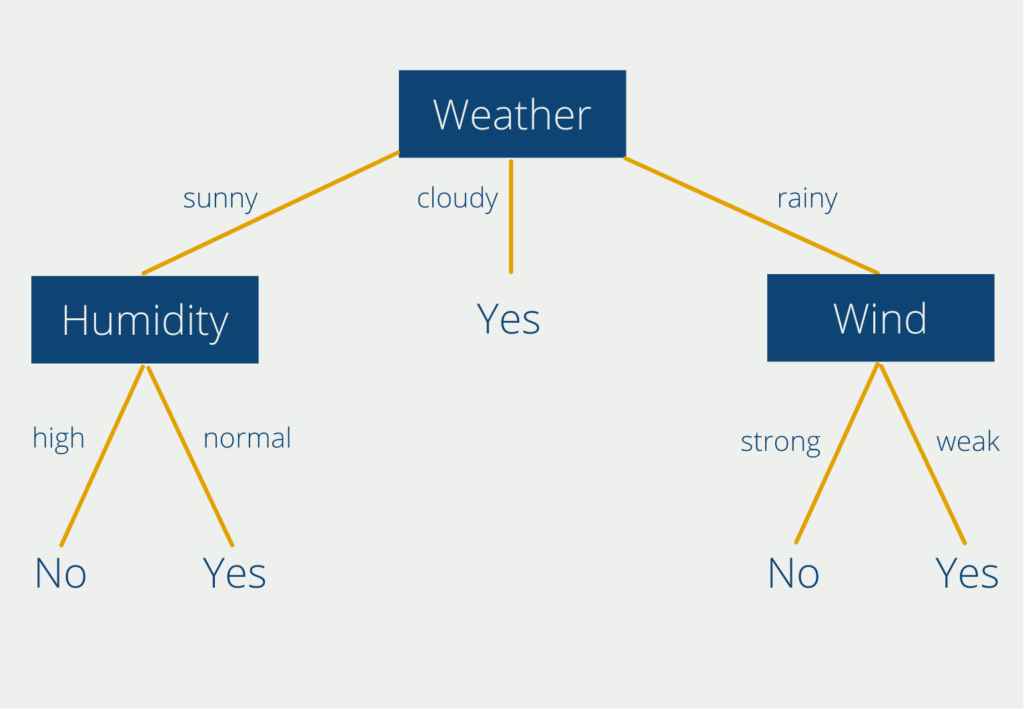
Diskretisierung wird häufig bei Data Mining, maschinellem Lernen und statistischer Analyse eingesetzt. Es ist eine nützliche Technik, um die Menge an Rauschen in den Daten zu reduzieren und die Analyse zu vereinfachen. Es ist jedoch wichtig, die geeignete Diskretisierungsmethode für die vorliegenden Daten zu wählen und sich der Grenzen der Technik bewusst zu sein.
Warum brauchen Modelle für maschinelles Lernen eine Datenvorverarbeitung?
Modelle für maschinelles Lernen benötigen eine Vorverarbeitung der Daten, weil:
- Die Daten können fehlende Werte, Ausreißer oder Rauschen enthalten, was die Leistung des Modells beeinträchtigen kann.
- Die Daten können in unterschiedlichen Formaten oder Einheiten vorliegen, was den Vergleich und die Analyse erschwert.
- Die Daten können eine große Anzahl von Merkmalen enthalten, von denen einige irrelevant oder redundant sein können, was zu einer Überanpassung führen kann.
- Die Daten können unausgewogen sein, wobei einige Klassen viel weniger Stichproben haben als andere, was das Modell in Richtung der Mehrheitsklasse verzerren kann.
- Die Daten können kategoriale Variablen enthalten, die vor der Verwendung im Modell in numerische Werte umgewandelt werden müssen.
- Die Daten müssen möglicherweise skaliert oder normalisiert werden, um sicherzustellen, dass alle Merkmale auf einer vergleichbaren Skala liegen.
- Durch die Vorverarbeitung der Daten können wir die Qualität der Daten verbessern, das Fehlerrisiko verringern und die Genauigkeit des maschinellen Lernmodells erhöhen.
Das solltest Du mitnehmen
- Das Data Preprocessing ist ein entscheidender Schritt in jedem Data-Science-Projekt.
- Dabei werden die Daten für die Analyse vorbereitet, indem sie bereinigt, umgewandelt und organisiert werden.
- Zu den gängigen Techniken des Data Preprocessings gehören Datenbereinigung, Merkmalsskalierung, Datendiskretisierung und Merkmalstechnik.
- Das Data Preprocessing kann die Genauigkeit von Modellen des maschinellen Lernens verbessern, indem Rauschen und irrelevante Informationen aus den Daten entfernt werden.
- Die Qualität der Ergebnisse von Modellen des maschinellen Lernens hängt in hohem Maße von der Qualität der vorverarbeiteten Daten ab.
- Zusammenfassend lässt sich sagen, dass das Data Preprocessing ein wesentlicher Schritt ist, der bei keinem Data-Science-Projekt außer Acht gelassen werden sollte.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Data Preprocessing
Einen ausführlichen Artikel über die Vorverarbeitung von Daten in Scikit-Learn findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.