Ensemble learning is a Machine Learning technique that involves combining the predictions of multiple individual models to improve the accuracy and stability of the overall prediction. The individual models can be of different types, including decision trees, neural networks, support vector machines, and others. Ensemble learning is widely used in various applications, such as image recognition, speech recognition, and natural language processing. In this article, we will discuss ensemble learning, its applications, advantages, and disadvantages.
What is ensemble learning and boosting in Machine Learning?
In Machine Learning, not only individual models are used. In order to improve the performance of the entire program, several individual models are sometimes combined into a so-called ensemble. A random forest, for example, consists of many individual decision trees whose results are then combined into one result. The basic idea behind this is the so-called “Wisdom of Crowds”, which states that the expected value of several independent estimates is better than each individual estimate. This theory was formulated after the weight of an ox at a medieval fair was not estimated as accurately by any individual as by the average of the individual estimates.
Boosting describes the procedure of combining multiple models into an ensemble. Using the example of decision trees, the training data is used to train a tree. For all the data for which the first decision tree gives bad or wrong results, a second decision tree is formed. This is then trained using only the data that the first misclassified. This chain is continued and the next tree uses the information that led to bad results in the first two trees.
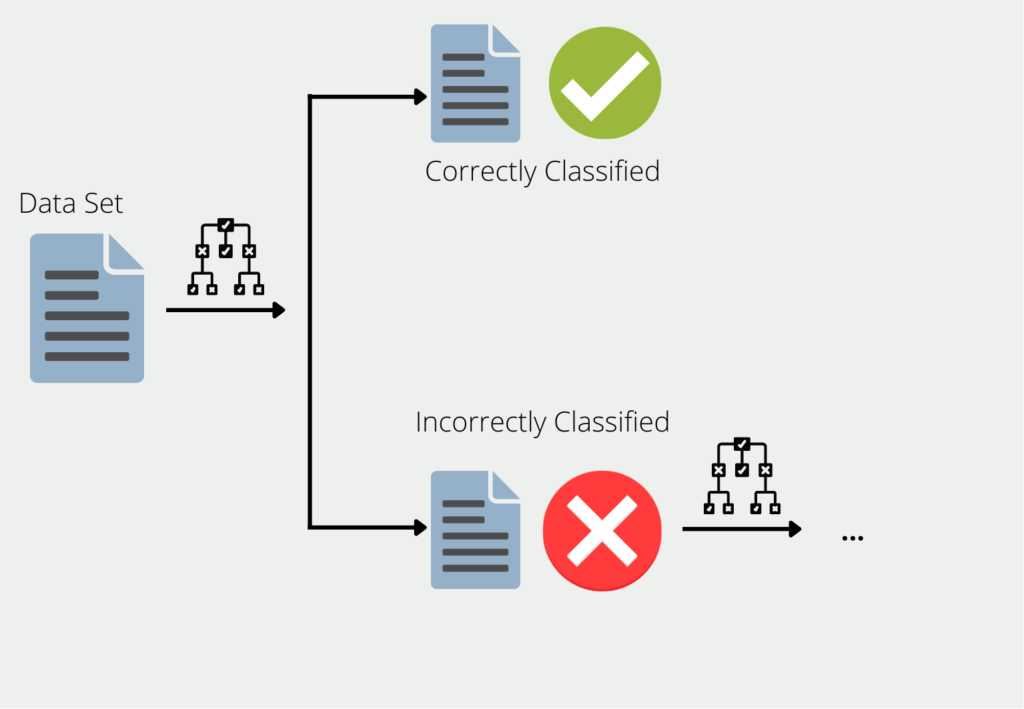
The ensemble of all these decision trees can then provide good results for the entire data set since each individual model compensates for the weaknesses of the others. This is also referred to as combining many “weak learners” into one “strong learner”.
These are referred to as weak learners because they often deliver rather poor results. Their accuracy is in many cases better than simply guessing, but also not significantly better. However, they offer the advantage that they are easy to calculate in many cases and can thus be combined easily and inexpensively.
What is it used for?
Ensemble learning is widely used in various applications, including:
- Image recognition: Ensemble learning is used in image recognition to improve the accuracy of the prediction. Multiple individual models are trained on different image data subsets, and their predictions are combined to improve overall prediction accuracy.
- Speech recognition: It is used in speech recognition to improve the accuracy of the prediction. Multiple individual models are trained on different subsets of the speech data, and their predictions are combined to improve the overall prediction accuracy.
- Natural language processing: Ensemble learning is used in natural language processing to improve the accuracy of the prediction. Multiple individual models are trained on different subsets of the text data, and their predictions are combined to improve the overall prediction accuracy.
- Fraud detection: Banks heavily rely on fraud detection to save their clients’ money and recognize malicious actions in their bank accounts. Multiple individual models are trained on different subsets of the transaction data, and their predictions are combined to improve the overall prediction accuracy.
- Medical diagnosis: In medicine, X-ray images often need to be classified. Here it can be useful to combine many individual classifiers that specialize in specific disease patterns.
What are the advantages and disadvantages of Ensemble Learning?
Ensemble learning is a powerful Machine Learning technique that involves combining the predictions of multiple individual models to improve the overall prediction accuracy. The technique has several advantages, including improved accuracy, increased stability, reduced overfitting, improved robustness, and versatility. By combining the predictions of multiple individual models, ensemble learning can leverage the strengths of each model and mitigate their weaknesses, leading to more accurate and stable predictions.
Additionally, ensemble learning can reduce the risk of overfitting, which occurs when a model is too complex and fits the training data too well, leading to a poor generalization of new data. Moreover, ensemble learning can improve the robustness of the prediction, making it less sensitive to outliers or errors in the data. Finally, ensemble learning can be applied to various types of data and models, making it a versatile and flexible technique.
However, ensemble learning also has some disadvantages. First, it can increase the complexity of the model, making it more difficult to interpret. By using multiple individual models, the overall model becomes more complex and difficult to understand, especially when dealing with large datasets. Second, ensemble learning can require more computational resources. By using multiple individual models, the overall model requires more computational resources for training and prediction, which can be a challenge for resource-limited environments. Finally, ensemble learning can still be prone to overfitting if the individual models are not carefully selected or if the ensemble size is too large. Therefore, careful model selection and ensemble size are crucial to avoid overfitting and maximize the benefits of ensemble learning.
Which algorithms are built on Ensemble Learning?
In the field of Machine Learning, there are some algorithms that combine multiple models and make use of the principles of ensemble learning. We will take a closer look at some of them in the following.
Random Forest
The Random Forest consists of a large number of these decision trees, which work together as a so-called ensemble. Each individual decision tree makes a prediction, such as a classification result, and the forest uses the result supported by most of the decision trees as the prediction of the entire ensemble.
This can be applied in exactly the same way to the Random Forest. A large number of decision trees and their aggregated prediction will always outperform a single decision tree.

However, this is only true if the trees are not correlated with each other and thus the errors of a single tree are compensated by other Decision Trees. The median of the estimates of all 800 people only has the chance to be better than each individual person, if the participants do not agree with each other, i.e. are uncorrelated. However, if the participants discuss together before the estimation and thus influence each other, the wisdom of the many no longer occurs.
AdaBoost
Adaptive boosting, or AdaBoost for short, is a special variant of boosting. It tries to combine several weak learners into a strong model. In its basic form, Adaptive Boost works best with Decision Trees. However, we do not use the “full-grown” trees with partly several branches, but only the stumps, i.e. trees with only one branch. These are called “decision stumps”.

For our example, we want to train a classification that can predict whether a person is healthy or not. To do this, we use a total of three features: Age, weight, and the number of hours of exercise per week. In our dataset, there are a total of 20 studied individuals. The Adaptive Boost algorithm now works in several steps:
- Step 1: For each feature, a decision stump is trained with the weighted data set. In the beginning, all data points still have the same weight. In our case, this means that we have a single stump for age, weight, and sports hours, which directly classifies health based on the feature.
- Step 2: From the three Decision Stumps, we choose the model that had the best success rate. Suppose the stump with the sports lessons performed the best. Out of the 20 people, he was already able to classify 15 correctly. The five misclassified ones now get a higher weighting in the data set to ensure that they will definitely be classified correctly in the next model.
- Step 3: The newly weighted data set is now used to train three new Decision Stumps again. With the “new” dataset”, this time the stump with the “Age” feature performed the best, misclassifying only three people.
- Step 4: Steps two and three are now repeated until either all data points have been correctly classified or the maximum number of iterations has been reached. This means that the model repeats the new weighting of the data set and the training of new decision stumps.
Now we understand where the name “Adaptive” comes from in AdaBoost. By reweighting the original data set, the ensemble “adapts” more and more to the concrete use case.
Gradient Boosting
Gradient boosting, in turn, is a subset of many, different boosting algorithms. The basic idea behind it is that the next model should be built in such a way that it further minimizes the loss function of the ensemble.
In the simplest cases, the loss function simply describes the difference between the model’s prediction and the actual value. Suppose we train an AI to predict a house price. The loss function could then simply be the mean squared error between the actual price of the house and the predicted price of the house. Ideally, the function approaches zero over time and our model can predict correct prices.
New models are added as long as prediction and reality no longer differ, i.e. the loss function has reached the minimum. Each new model tries to predict the error of the previous model.
Let’s go back to our example with house prices. Let’s assume a property has a living area of 100m², four rooms, and a garage and costs 200,000€. The gradient boosting process would then look like this:
- Training of regression to predict the purchase price with the features of living space, the number of rooms, and the garage. This model predicts a purchase price of 170,000 € instead of the actual 200,000 €, so the error is 30,000 €.
- Training another regression that predicts the error of the previous model with the features of living space, number of rooms, and garage. This model predicts a deviation of 23,000 € instead of the actual 30,000 €. The remaining error is therefore 7,000 €.
This is what you should take with you
- Ensemble Learning is a technique in Machine Learning which describes the process of combining several so-called weak learners into an improved model.
- In many application areas, Ensemble models can even achieve better results than neural networks.
- Additionally, they have other advantages over more sophisticated models like a lower risk of overfitting.

What is Grid Search?
Optimize your machine learning models with Grid Search. Explore hyperparameter tuning using Python with the Iris dataset.

What is the Learning Rate?
Unlock the Power of Learning Rates in Machine Learning: Dive into Strategies, Optimization, and Fine-Tuning for Better Models.

What is Random Search?
Optimize Machine Learning Models: Learn how Random Search fine-tunes hyperparameters effectively.

What is the Lasso Regression?
Explore Lasso regression: a powerful tool for predictive modeling and feature selection in data science. Learn its applications and benefits.

What is the Omitted Variable Bias?
Understanding Omitted Variable Bias: Causes, Consequences, and Prevention in Research." Learn how to avoid this common pitfall.

What is the Adam Optimizer?
Unlock the Potential of Adam Optimizer: Get to know the basucs, the algorithm and how to implement it in Python.
Other Articles on the Topic of Ensemble Learning
You can find an overview of Scikit-Learns ensemble methods here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.