Apache HDFS is a distributed file system for storing large amounts of data in the area of Big Data and distributing it on different computers. This system enables Apache Hadoop to be run in a distributed manner across a large number of nodes, i.e. computers.
What is the Apache Framework Hadoop?
Apache Hadoop is a software framework that can be used to quickly process large amounts of data on distributed systems. It has mechanisms that ensure stable and fault-tolerant functionality so that the tool is ideally suited for data processing in the Big Data environment. The software framework itself is a compilation of four components.
Hadoop Common is a collection of various modules and libraries that support the other components and enable them to work together. Among other things, the Java Archive Files (JAR Files) are stored here, which are required to start Hadoop. In addition, the collection enables the provision of basic services, such as the file system.
The Map-Reduce algorithm has its origins in Google and helps to divide complex computing tasks into more manageable subprocesses and then distribute these across several systems, i.e. scale them horizontally. This significantly reduces the computing time. In the end, the results of the subtasks have to be combined again into the overall result.
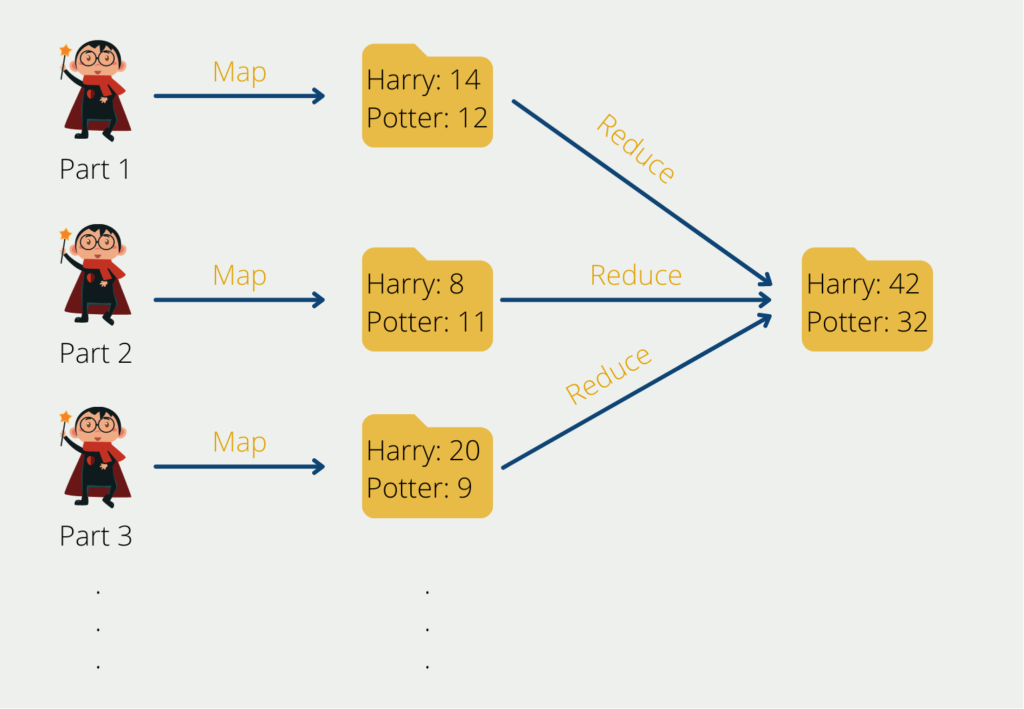
The Yet Another Resource Negotiator (YARN) supports the Map-Reduce algorithm by keeping track of the resources within a computer cluster and distributing the subtasks to the individual computers. In addition, it allocates the capacities for individual processes.
The Apache Hadoop Distributed File System (HDFS) is a scalable file system for storing intermediate or final results, which we will discuss in more detail in this post.
What do we need HDFS for?
Within the cluster, an HDFS is distributed across multiple computers to process large amounts of data quickly and efficiently. The idea behind this is that big data projects and data analyses are based on large volumes of data. Thus, there should be a system that also stores the data in batches and processes it quickly. The HDFS ensures that duplicates of data records are stored in order to be able to cope with the failure of a computer.
According to its own documentation, Hadoop’s goals in using HDFS are as follows:
- Fast recovery from hardware failures
- Enabling stream data processing
- Processing of huge data sets
- Easy to move to new hardware or software
What is the architecture of the Hadoop Distributed File System?
The core of the Hadoop Distributed File System is to distribute the data across different files and computers so that queries can be processed quickly and the user does not have long waiting times. To ensure that the failure of a single machine in the cluster does not lead to the loss of the data, there are targeted replications on different computers to ensure resilience.
Hadoop generally works according to the so-called master-slave principle. Within the computer cluster, we have a node that takes on the role of the so-called master. In our example, this node does not perform any direct computation but merely distributes the tasks to the so-called slave nodes and coordinates the entire process. The slave nodes in turn read the books and store the word frequency and word distribution.
This principle is also used for data storage. The master distributes information from the data set to different slave nodes and remembers on which computers it has stored which partitions. It also stores the data redundantly in order to be able to compensate for failures. When the user queries the data, the master node then decides which slave nodes it must query in order to obtain the desired information.
The master within the Apache Hadoop Distributed File System is called a Namenode. The slave nodes in turn are the so-called data nodes. From bottom to top, the schematic structure can be understood as follows:
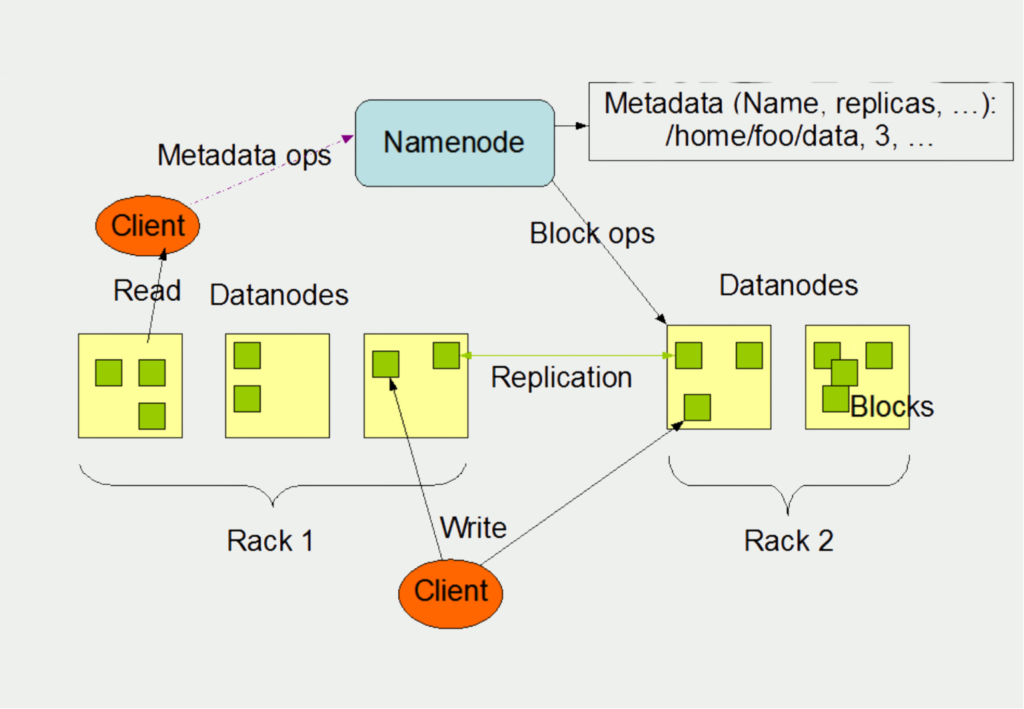
The client writes data to various files, which can be located on different systems, in our example the datanodes on racks 1 and 2. There is usually one datanode per computer in a cluster. These primarily manage the memory that is available to them on a computer. Several files are usually stored in the memory, which in turn are split into so-called blocks.
The task of the name node is to remember which blocks are stored in which datanode. In addition, they manage the files and can open, close, and rename them as needed.
The datanodes in turn are responsible for the read and write processes of the client, i.e. the user. The client also receives the desired information from them in the event of a query. At the same time, the datanodes are also responsible for the replication of data to ensure the fault tolerance of the system.
What are the limitations of HDFS?
The Hadoop Distributed File System (HDFS) has become a popular choice for storing and processing large amounts of data. While HDFS offers several advantages, it also has some limitations that users should be aware of:
- Single point of failure: HDFS has a master-slave architecture in which the NameNode acts as the master and the DataNodes act as slaves. If the NameNode fails, the entire cluster becomes inaccessible and the data is no longer available. Although Hadoop provides a mechanism for automatic failover, downtime can still occur.
- Limited support for small files: The File System is designed to store and process large files, typically in the gigabyte to terabyte range. However, it does not perform well with large numbers of small files because it incurs significant overhead in managing metadata and allocating storage space.
- High storage cost: HDFS uses a replication mechanism to ensure data availability and fault tolerance, which can lead to high storage costs. The more replicas of data stored in the cluster, the higher the storage cost.
- Slow data access: The system uses a WORM (write-once-read-many) model that is optimized for sequential data access. As a result, random data access can be slow and inefficient, especially for small files.
- Limited support for real-time data processing: HDFS is not designed for real-time data processing because it requires a batch-oriented processing model. While the Hadoop ecosystem offers tools such as Apache Spark, Flink, and Storm for real-time processing, they are not directly integrated with HDFS.
Despite these limitations, HDFS remains a widely used distributed file system for storing and processing large amounts of data. It is often used in conjunction with other tools in the Hadoop ecosystem to provide a complete data processing solution
What are the advantages of the Hadoop Distributed File System?
For many companies, the Hadoop framework is also becoming increasingly interesting as a data lake, i.e. as unstructured storage for large amounts of data, due to the HDFS. Various points play a decisive role here:
- Ability to store large amounts of data in a distributed cluster. In most cases, this is significantly cheaper than storing the information on a single machine.
- High fault tolerance and thus highly available systems.
- Hadoop is open source and therefore free to use and the source code can be viewed
These points explain the increasing adoption of Hadoop and HDFS in many applications.
What does the future of HDFS look like?
The Hadoop Distributed File System (HDFS) has made its way into many Big Data environments and has been on the market for more than a decade. As with any technology, the future of HDFS is constantly evolving, and there are several trends that are likely to influence its development.
One of the most important trends shaping the future of HDFS is the growth of the cloud. Cloud computing has become increasingly popular in recent years, and many organizations are moving their data and applications to the cloud. HDFS is no exception, and there are now cloud-based HDFS services that allow organizations to store and manage their Big Data in the cloud. This trend is likely to continue, and we can expect to see more cloud-based HDFS services in the future.
Another trend shaping the future of HDFS is the growth of machine learning and artificial intelligence. As more organizations adopt machine learning and AI technologies, they will need to store and manage large amounts of data. HDFS is ideally suited for this task, and it is expected that more and more organizations will use HDFS as a data storage and management solution for their machine learning and AI workloads.
In addition to these trends, there are also several technical advances that will shape the future of HDFS. For example, HDFS has traditionally been a batch processing system, but there are now efforts to make it more suitable for real-time processing. This requires changes to the underlying architecture of HDFS, and we can expect to see more developments in this area in the future.
Overall, the future of HDFS looks very bright. It is a mature technology that has proven itself in many Big Data environments, and it is well-positioned to meet the needs of organizations looking to store and manage large amounts of data. As cloud computing, machine learning, and real-time processing become more popular, we can expect HDFS to evolve to meet the needs of these trends.
This is what you should take with you
- HDFS is a distributed file system for storing large amounts of data in the field of Big Data and distributing it on different computers.
- It is part of the Apache Hadoop framework.
- The master node divides the data set into smaller partitions and distributes them on different computers, the so-called slave nodes.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of HDFS
- You can find detailed documentation on the Hadoop Distributed File System on their site.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.