For machine learning models to learn and improve their predictions, they need so-called loss functions that measure how large the difference is between the prediction and the actual value. Binary cross-entropy (BCE) is a central loss function used for binary classifications, i.e. those that assign objects to one of two classes. It helps to train models precisely and reliably, whether in the recognition of spam emails or the medical diagnosis of patients.
In this article, we will take a basic look at what loss functions are and how binary cross-entropy works. We will also take a detailed look at the mathematical structure of the function and explain it using a simple example. Furthermore, we examine the various areas of application in which BCE is used and highlight the advantages and disadvantages of this loss function.
What is a Loss Function?
The loss function, also known as the objective function or cost function, is a crucial concept in machine learning that evaluates the performance of the training model and guides the learning process. Put simply, it calculates the difference between the actual target values in the data set and the model’s prediction. In short, it measures how well or poorly the model performs.
During the training process, the loss function serves as a guideline to optimize the model parameters, such as the neuron weights in a neural network. This generally involves the following steps:
- The loss function calculates the current error of the model.
- The model parameters are modified in such a way that they significantly reduce the error in the next training run. Backpropagation, for example, can be used for this purpose.
- This process is repeated until the model has achieved the lowest possible error and, in the best case, has reached the global minimum of the loss function.
Without the loss function, it would not be possible to train a model, as there would be no method for evaluating the quality of the predictions. However, with the help of this function, there are concrete mathematical calculations that can be made to change the model parameters and improve the model. A good loss function should have the following properties:
- It should be sensitive to deviations in the predictions so that even small discrepancies between the prediction and the target value carry weight and can be recognized.
- Depending on the model, the loss function should also be differentiable, i.e. the derivative of the function should be defined. This allows methods such as gradient descent to be used, which utilizes differentiation.
- The function should be adapted to the characteristics of the specific model so that, for example, classifications can be mapped.
In combination with the appropriate model, the loss function is a central tool for training powerful and accurate machine learning models that can be used in a wide range of applications.
What is Binary Cross-Entropy?
The binary cross-entropy loss is a loss function that is used for binary applications, i.e. when the predictions can only assume one of two states, for example, “true/false” or “sick/healthy”. This is used, for example, in classifications in which the creditworthiness of people is to be classified as “good” and “bad”. Within machine learning, it is one of the most important loss functions and is used in many binary classifications.
Binary cross-entropy can be used to measure how close the model’s prediction is to the actual target value. For this purpose, the classifications of the model are constructed in such a way that they lie between 0 and 1, with 0 indicating membership of one class, such as “false” or “sick”, and 1 indicating membership of the other class, such as “true” or “healthy”. The model can predict all values between 0 and 1, whereby the distance to the respective classes provides information on how certain the model is that a data point should be assigned to a class.
A value of 0.15, for example, indicates that the model is fairly certain that the data point should be assigned to class 0, while a prediction of 0.48 indicates that the model cannot make up its mind. The strength of binary cross-entropy lies in the fact that it penalizes incorrect predictions with a high degree of certainty and thus leads the model to make correct decisions with a high degree of certainty.
The mathematical formulation of binary cross-entropy is as follows:
\(\)\[\text{BCE} = -\frac{1}{N} \sum_{i=1}^{N} \left[ y_i \cdot \log(\hat{y}_i) + (1 – y_i) \cdot \log(1 – \hat{y}_i) \right]\]
Where \(y_i\) is the actual class of the data point and \(\hat{y_i}\) is the predicted class of the model for this data point. The number of data points in the dataset is represented by \(N\). The errors of all data points are finally summed up and then divided by the number of data points to calculate an average value.
In addition, the binary cross-entropy consists of the following two components:
- \(y_i \cdot \log(\hat{y_i})\): This term evaluates the loss if the actual class is \(y_i = 1\). The loss in this part is minimized if the prediction \(\hat{y_i}\) is close to 1. The second part of the loss function is automatically dropped, as \(1 – y_i = 0\) and therefore has no influence.
- \((1-y_i) \cdot \log(1-\hat{y_i})\): This second part of the function is activated if the actual class is 0, i.e. \(y_i = 0\). The first part of the equation is dropped, as the logarithm is multiplied by \(y_i\), i.e. 0. The loss is minimized if the model is particularly certain and the prediction \(\hat{y_i}\) is close to 0.
The binary cross-entropy loss is characterized by the fact that errors are treated asymmetrically so that larger errors and deviations are penalized more than smaller deviations. This may seem illogical at first, as all errors in a binary classification are actually “equally bad” because the wrong class was predicted. In practice, however, it is also important how certain the model is about a classification to prevent different predictions in similar cases, which could jeopardize the credibility of the model.
What are the theoretical Concepts of Binary Cross-Entropy?
As the name Binary Cross-Entropy suggests, this loss function contains some theoretical concepts from information theory and statistics that are essential to understanding the functionality of this loss function in more detail. The BCE is used in models that predict a binary classification and use probabilities for this. These are in a range between 0 and 1, where a probability close to 1 means that the model is very certain that a data point should be assigned to class 1, and a value close to 0 means that the model would assign class 0 to the data point.
Logarithm
The logarithmic terms \(\log(\hat{y_i})\) and \(\log(1-\hat{y_i})\) are used to evaluate the predictions of the model non-linearly, but to reward the model if it is certain about the decisions.
The logarithm is characterized by its exponential growth, which ensures that values close to zero take on a very large absolute value and values close to 1 take on a very small absolute value. As a result, the loss function provides a strong reward for decisions that were made with a high probability, whereby it is initially irrelevant whether these were correct or not.
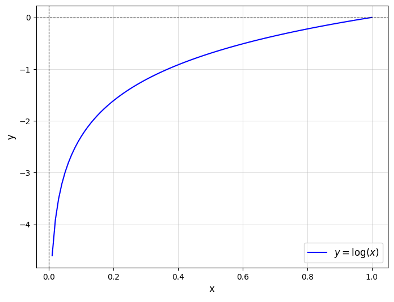
The binary cross-entropy includes the correctness of the prediction by having the two terms inside the brackets. If the data point belongs to class 0, then only the second part of the term determines the loss. If the model incorrectly predicts a value close to 1 here, then the term within the logarithm approaches zero and the model is penalized more than if it is uncertain, i.e. predicts a value of 0.5 or even makes a correct prediction close to 1.
The logarithm is also responsible for the minus at the beginning of the term. As can be seen in the diagram, the logarithm in the range between 0 and 1 is in the negative y-range. This means that the sum within the brackets is also negative, as neither \(y_i\) nor \(1-y_i\) can become negative by definition and therefore the two products will always remain negative. Since loss functions are usually positive, the preceding minus sign is used to ensure that the entire term is positive.
Entropy and Cross-Entropy
Entropy describes a concept from information theory that measures how uncertain or unpredictable a situation or event is. If an event is very certain and predictable, there is little entropy, such as in a coin toss, where in practice there are only two possible outcomes: Heads or Tails (if you rule out the coin landing on the edge). On the other hand, if an event is difficult to predict, then it has a high entropy because it is more uncertain. Compared to a coin toss, the roll of a die has a higher entropy because it is more difficult to predict this event.
Cross entropy goes beyond this and compares two probability distributions, more precisely:
- The true distribution underlies the random event and includes the actual outcomes or target values from the data set.
- The predicted distribution describes the probability distribution that the model learns during training.
In the best case, the model approaches the true distribution over time. The cross-entropy helps to measure exactly this property. In a perfect world, a good model would predict a probability of 1 if a data point belongs to class 1 and vice versa. In reality, however, this is rarely the case and the predicted probabilities tend to approach these extreme values.
Binary cross-entropy implements cross-entropy by penalizing the model particularly harshly if the model predicts a particularly high probability of an incorrect result because the difference between the true distribution and the predicted distribution is high. This behavior is implemented mathematically using the described properties of the logarithm and the term that includes both states.
Which Applications Use Binary Cross-Entropy?
Binary cross-entropy is a central loss function in the field of machine learning and is used in a wide variety of applications. Due to its structure, it is particularly suitable for binary classifications such as the following:
- Spam Detection: BCE is used to detect fraudulent activity and classify corresponding objects. For example, it can be used to detect spam emails or fraudulent transfers from bank accounts.
- Disease Diagnosis: Within the healthcare sector, the BCE loss function can be used for models that support medical diagnoses. These can be trained to predict whether or not a patient is suffering from a particular disease based on various symptoms and measurements.
- Sentiment Analysis: Natural language processing is concerned with making human language understandable for machines and thus being able to process texts. Sentiment analysis attempts to predict whether a passage reflects a positive or negative mood. This can be used primarily for social media comments or product reviews to obtain a quick classification and then process these comments separately.
These are just a few of the applications in which binary cross-entropy is used. Due to its positive properties, it has established itself as the standard loss function for a wide variety of model architectures.
What are the Advantages and Disadvantages of BCE?
The use of binary cross-entropy offers various advantages for use in the field of machine learning. However, there are also some challenges and problems that need to be considered when using it. Therefore, in this section, we work through the opportunities and challenges so that, depending on the application, an informed decision can be made as to whether binary cross-entropy is the right loss function.
Advantages:
- Specialization on binary classifications: The architecture of this loss function is designed for two-class applications and works very well for them. In addition, it is usually easy to use in this context, as the models are designed for use with BCE.
- Intuitive model evaluation: The interpretation of the results is particularly simple, as lower values indicate a better model. A high value, on the other hand, indicates that the predicted class usually does not match the actual class or that the model is not very confident in its prediction.
- Comparability of models: BCE can additionally be used to compare different model architectures trained on the same data set. Due to the fixed mathematical basis, the architecture that provides the lowest loss value based on BCE is the best. This makes it easy to test different architectures and then select the model that gives the best results for that dataset.
- Sensitivity to probabilities: Compared to other loss functions, BCE not only prioritizes that the model makes the correct predictions and thus achieves high accuracy, but also rewards models that do so with a high probability, i.e. a high degree of certainty.
- Combination with activation functions: Particularly in the field of neural networks, BCE can also be combined with various activation functions, such as the softmax function.
Disadvantages:
- Problems with unbalanced data sets: A common problem in creating a classification model is the unbalanced data set, which often contains more examples of one class than the other. In medicine, for example, many datasets contain more healthy patients than sick patients, simply because they occur more frequently. In such cases, even BCE can produce unbalanced results, as the more common class dominates and the model tends to simply ignore the rarer class. To counteract this problem, a weighted binary cross-entropy can be used, which assigns a higher weight to the underrepresented class and thus counteracts this behavior.
- Numerical stability: In the extreme cases where the model is particularly certain and predicts either \(\hat{y_i} = 0\) or \(\hat{y_i} = 1\), it happens that the loss value tends to infinity, since \(log(0) \rightarrow – \infty\). Although this scenario is very rare, it can occur and lead to numerical problems. To prevent this, the predictions can be limited so that they can assume values very close to 0 and 1, but not exactly these values, for example: \(\hat{y_i} = max(\epsilon, 1-\epsilon)\).
- Interpretation for probabilities: The binary cross-entropy is a loss function that measures the difference between the predicted probabilities and the actual classes. However, the final classification of the model depends not only on the prediction but also on the threshold value chosen to distinguish the classes. In the simplest case, 0.5 can be used as a threshold, so that any prediction greater than 0.5 means an assignment to class 1. However, in medical diagnosis and other applications, other thresholds can also be used, which have a major impact on the model’s accuracy.
Binary cross-entropy is a powerful loss function that has great advantages when used with binary classification models. However, it can also cause problems if the data set is unbalanced. The above points should therefore be considered before using binary cross-entropy for your model.
How can Binary Cross-Entropy be used with more than two classes?
Although binary cross-entropy is designed for classification models with only two classes, it can also be used for multi-class problems with slight modifications. The most common approach is the so-called “one-vs-all” or “one-vs-rest”, which organizes the class labels in a binary format so that a model can be trained that makes binary predictions.
For example, an application with three classes “A”, “B” and “C” can then be rewritten to produce binary vectors with three entries. This means that a data point belonging to class “B” does not have the target value “B”, but [0, 1, 0]. The model, such as a neural network, would have to be modified so that the output layer has three nodes and predicts a probability between 0 and 1 at each node.
This allows the binary cross-entropy to be calculated for each class individually, as this is an isolated, binary classification, and then the total loss can be calculated from the sum of the individual classes.
How can you use Binary Cross-Entropy in Python?
Binary cross-entropy is part of many modules in Python, such as PyTorch or TensorFlow, and can be very easily integrated into existing models in these libraries. In this section, we will look at a simple example of how to load and use binary cross-entropy from TensorFlow.
To do this, we load TensorFlow and create two simple lists, one with fictitious class assignments of three data points and one with the hypothetical predictions made by a model.
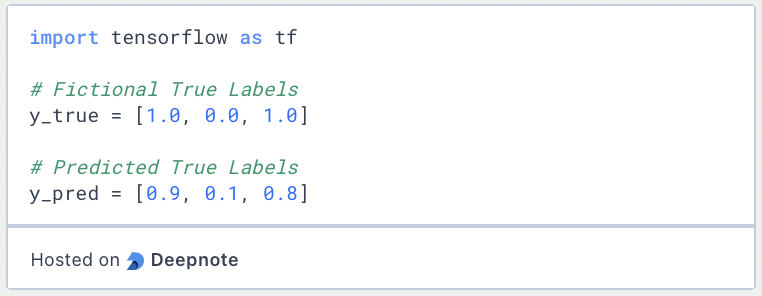
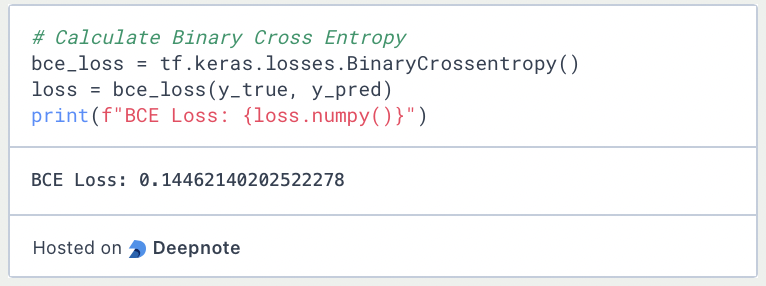
We can then load the BinaryCrosentropy() function from the Keras loss functions and pass the two lists as parameters. This gives us the loss value for the data set consisting of three data points.
This is what you should take with you
- Binary cross-entropy is a central loss function in machine learning that is used for binary classification models.
- It is characterized by the fact that it not only includes the accuracy of a model in the loss but also the certainty with which a model predicts the correct class.
- Due to the logarithm, larger deviations from the correct class are also penalized more than small deviations.
- The use of binary cross-entropy can lead to problems if the data set is unbalanced or the model predicts the extreme values 0 or 1.
- Binary cross-entropy can also be used for multi-class problems using the “one-vs-all” approach.
- In Python, various libraries, such as PyTorch or TensorFlow, offer functions with which binary cross-entropy can be easily used.

Prompt Engineering Explained: Basics, Examples and Best Practices
Why good prompts rarely start with “Write me…” “Write an analysis of this customer feedback.” At first glance, that sounds clear. But an AI model may still return a polished answer that is too broad to be useful. That is where prompt engineering starts: not with magic words, but with removing ambiguity from the task.… Read More »Prompt Engineering Explained: Basics, Examples and Best Practices
Retrieval Augmented Generation: Using Your Own Data with AI
Learn Retrieval Augmented Generation step by step and connect AI with your own data. Start building smarter AI systems today!

Retrieval-Augmented Generation (RAG) Explained: How to Connect LLMs to Your Own Data (Python Tutorial)
Why LLMs Fail at Private Data — And Why RAG Solves It Large language models like GPT-5 or Claude are trained on data up to a certain date. They don’t know what’s inside your company’s internal documentation, your product database, or last quarter’s sales report. They also can’t browse a private Notion workspace or read… Read More »Retrieval-Augmented Generation (RAG) Explained: How to Connect LLMs to Your Own Data (Python Tutorial)

What is a Boltzmann Machine?
Unlocking the Power of Boltzmann Machines: From Theory to Applications in Deep Learning. Explore their role in AI.

What is the Gini Impurity?
Explore Gini impurity: A crucial metric shaping decision trees in machine learning.

What is the Hessian Matrix?
Explore the Hessian matrix: its math, applications in optimization & machine learning, and real-world significance.
Other Articles on the Topic of Binary Cross-Entropy
Here you can find the TensorFlow documentation explaining how to use the loss function.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.