Gradient Boosting is a Machine Learning method that combines several so-called “weak learners” into a powerful model for classifications or regressions. In this article, we look at the concepts of boosting and ensemble learning and explain how gradient boosting works.
What are Ensemble Learning and Boosting in Machine Learning?
In Machine Learning, it is not always just individual models that are used. To improve the performance of the entire program, several individual models are sometimes combined into a so-called ensemble. A random forest, for example, consists of many individual decision trees whose results are then combined into one result. The basic idea behind this is the so-called “Wisdom of Crowds”, which states that the expected value of several independent estimates is better than each estimate. This theory was formulated after the weight of an ox at a medieval fair was estimated by no single individual as accurately as by the average of the individual estimates.
Boosting describes the procedure of combining multiple models into an ensemble. Using Decision Trees as an example, the training data is used to train a tree. For all the data for which the first decision tree gives bad or wrong results, a second decision tree is formed. This is then trained using only the data that the first misclassified. This chain is continued and the next tree in turn uses the information that led to bad results in the first two trees.
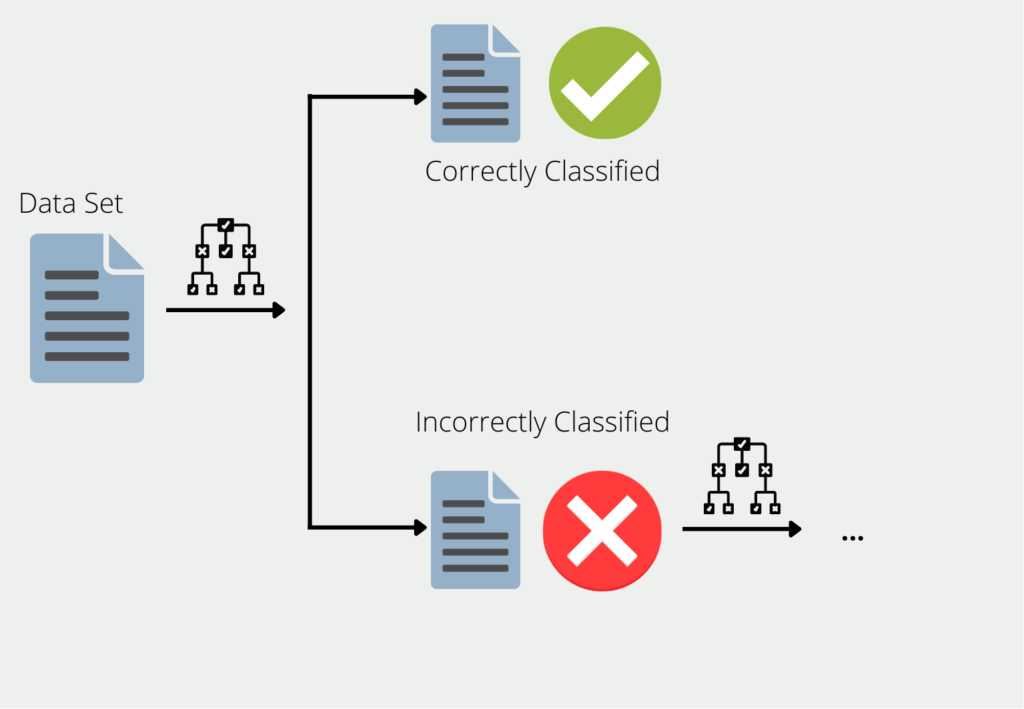
The ensemble of all these decision trees can then provide good results for the entire data set since each model compensates for the weaknesses of the others. It is also said that many “weak learners” are combined into one “strong learner”.
We speak of weak learners because in many cases they deliver rather poor results. Their accuracy is in many cases better than simply guessing, but not significantly better. However, they offer the advantage that they are easy to compute in many cases and thus can be combined easily and cheaply.
What is Gradient Boosting?
Gradient boosting, in turn, is a subset of many, different boosting algorithms. The basic idea behind it is that the next model should be built in such a way that it further minimizes the ensemble loss function.
In the simplest cases, the loss function simply describes the difference between the model’s prediction and the actual value. Suppose we train an AI to predict a house price. The loss function could then simply be the Mean Squared Error between the actual price of the house and the predicted price of the house. Ideally, the function approaches zero over time and our model can predict correct prices.
New models are added as long as the prediction and reality no longer differ, i.e. the loss function has reached the minimum. Each new model tries to predict the error of the previous model.
Let’s go back to our example with house prices. Assume a property has a living area of 100m², four rooms, and a garage, and costs 200.000€. The gradient boosting procedure would then look like this:
Training a regression to predict the purchase price with the features living area, number of rooms, and garage. This model predicts a purchase price of 170,000 € instead of the actual 200,000 €, so the error is 30,000 €.
Training another regression that predicts the error of the previous model with the features of living space, number of rooms, and garage. This model predicts a deviation of 23,000 € instead of the actual 30,000 €. The remaining error is therefore 7,000 €.
What are the advantages and disadvantages of boosting in general?
The general advantage of boosting is that many weak learners are combined into one strong model. Despite a large number of small models, these boosting algorithms are usually easier to compute than comparable neural networks. However, this does not necessarily mean that they also produce worse results. In some cases, ensemble models can even beat the more complex networks in terms of accuracy. Thus, they are also interesting candidates for text or image classifications.
Furthermore, boosting algorithms, such as AdaBoost, are also less prone to overfitting. This simply means that they not only perform well with the training dataset but also classify well with new data with high accuracy. It is believed that the multilevel model computation of boosting algorithms is not as prone to dependencies as the layers in a neural network, since the models are not optimized contiguously as is the case with backpropagation in the model.
Due to the stepwise training of single models, boosting models often have a relatively slow learning rate and thus require more iterations to deliver good results. Furthermore, they require very good data sets, since the models are very sensitive to noise and this should be removed in the data preprocessing.
What are the disadvantages of Gradient Boosting?
Gradient boosting is a popular choice for a wide range of applications as it can be adapted to a variety of scenarios. However, despite these numerous advantages, there are also some disadvantages or limitations that should be considered when using it:
- Overfitting: Gradient boosting is prone to overfitting if the hyperparameters are not set optimally or the model complexity is too high. This impairs the generalization performance so that the model does not provide good predictions for new data.
- Time and resource consumption: Another problem with boosting methods, in general, is the extended training time, as more models are trained, which takes up computing resources. Therefore, with gradient boosting, care should be taken to define the maximum depth of the trees and the number of leaves to limit the computational effort.
- Limited interpretability: The combination of different models makes it very difficult to interpret a single prediction. This turns the model into a black box so that the conclusions cannot be directly understood. If a transparent model with good interpretability is required for the application, it is better to use a single decision tree.
- Pre-processing of the data: The model performance of a gradient boosting model is also largely dependent on the pre-processing of the data. This includes, for example, categorical variables being coded or the features being scaled. If this is not the case, it can have a significant negative impact on model performance. In addition, outliers often lead to poorer results and should therefore be removed from the data set.
- Unbalanced data: For classification tasks, the balance of the data set is immensely important to train a meaningful gradient-boosting model. Otherwise, this can lead to significantly distorted models.
In conclusion, gradient boosting is a powerful method that has many benefits. If the points mentioned in this section are taken into account during training, nothing stands in the way of a high-performance model.
Gradient Boosting vs. AdaBoost
With AdaBoost, many different decision trees with only one decision level, so-called decision stumps, are trained sequentially with the errors of the previous models. Gradient Boosting, on the other hand, tries to minimize the loss function further and further by training the following models to use the so-called decision stumps.

Thus, Gradient Boosting can be used for regressions, i.e. the prediction of continuous values, as well as for classifications, i.e. the classification into groups. The AdaBoost algorithm, on the other hand, can only be used for classifications. This is also the main difference between these two boosting algorithms because, in the core idea, both of them try to combine weak learners into a strong model through sequential learning and the higher weighting of incorrect predictions.
Which boosting algorithm to choose?
Various boosting algorithms are available in the field of machine learning, all of which have advantages and disadvantages. Choosing the right model can therefore quickly become difficult and depends on various factors, such as the size of the data set and the degree of interpretability.
In this section, we provide a brief overview of the three most important boosting algorithms and when they should be selected:
- AdaBoost (Adaptive Boosting) is a popular choice for classification tasks. It combines several weak classifiers and trains them in several iterations. The iterations differ in that the training samples are given weights and thus a new classifier is trained. This allows the boosting algorithm to focus more on the misclassified training samples. AdaBoost is therefore suitable for classification tasks with medium-sized data sets.
- XGBoost (Extreme Gradient Boosting) uses decision trees as a basis and also relies on regularization to prevent overfitting. This means that even large data sets with high-dimensional features can be processed. In addition, both regression and classification tasks can be implemented particularly efficiently. This makes XGBoost a very broad-based model that can be used for many applications.
- Gradient boosting is a very general approach that can be individualized with different loss functions and underlying models. By combining different weak learners, a strong learner is formed that minimizes the loss function as much as possible. This flexible structure allows different data types, in particular categorical features, to be mapped.
AdaBoost is therefore primarily used for simple classification tasks with small to medium-sized data sets. For large data sets with high-dimensional features, on the other hand, XGBoost is a good choice, as the regularization effectively prevents overfitting. Gradient boosting, on the other hand, is to a certain extent the middle ground between these two approaches.
This is what you should take with you
- Gradient Boosting is a Machine Learning method from the field of boosting algorithms.
- The goal is to combine several so-called “weak learners” into one powerful model.
- In gradient boosting, several models are trained in succession, each of which tries to predict the previous error well.

What is a Boltzmann Machine?
Unlocking the Power of Boltzmann Machines: From Theory to Applications in Deep Learning. Explore their role in AI.

What is the Gini Impurity?
Explore Gini impurity: A crucial metric shaping decision trees in machine learning.

What is the Hessian Matrix?
Explore the Hessian matrix: its math, applications in optimization & machine learning, and real-world significance.

What is Early Stopping?
Master the art of Early Stopping: Prevent overfitting, save resources, and optimize your machine learning models.

What is RMSprop?
Master RMSprop optimization for neural networks. Explore RMSprop, math, applications, and hyperparameters in deep learning.

What is the Conjugate Gradient?
Explore Conjugate Gradient: Algorithm Description, Variants, Applications and Limitations.
Other Articles on the Topic of Gradient Boosting
A tutorial for gradient boosting in Scikit-Learn can be found here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.