Gradient Boosting ist eine Machine Learning Methode, die mehrere sogenannte “weak learners” zu einem leistungsfähigen Modell für Klassifizierungen oder Regressionen zusammenbaut. In diesem Artikel beschäftigen wir uns mit den Konzepten des Boosting und Ensemble Learning und erklären wie das Gradient Boosting funktioniert.
Was ist Ensemble Learning und Boosting im Machine Learning?
Im Machine Learning kommen nicht immer nur einzelne Modelle zum Einsatz. Um die Leistung des gesamten Programms zu verbessern, werden teilweise auch mehrere einzelne Modelle zu einem sogenannten Ensemble zusammengefasst. Ein Random Forest beispielsweise besteht aus vielen, einzelnen Decision Trees, deren Ergebnisse dann zu einem Resultat vereint werden. Die Grundidee dahinter ist die sogenannte “Wisdom of Crowds“, die besagt, dass der Erwartungswert von mehreren unabhängigen Schätzungen besser ist, als jede einzelne Schätzung. Diese Theorie wurde formuliert, nachdem auf einer mittelalterlichen Messe das Gewicht eines Ochsen von keiner Einzelperson so genau geschätzt wurde, wie vom Durchschnitt der Einzelschätzungen.
Das Boosting beschreibt die Vorgehensweise wie mehrere Modelle zu einem Ensemble zusammengefasst werden. Am Beispiel von Decision Trees, werden die Trainingsdaten genutzt, um einen Baum zu trainieren. Für alle die Daten, für die der erste Decision Tree schlechte oder falsche Ergebnisse liefert, wird ein zweiter Decision Tree gebildet. Dieser wird dann ausschließlich mit den Daten trainiert, die der erste falsch klassifiziert hat. Diese Kette wird weitergeführt und der nächste Baum wiederum nutzt die Informationen, die bei den ersten beiden Bäumen zu schlechten Ergebnissen geführt haben.
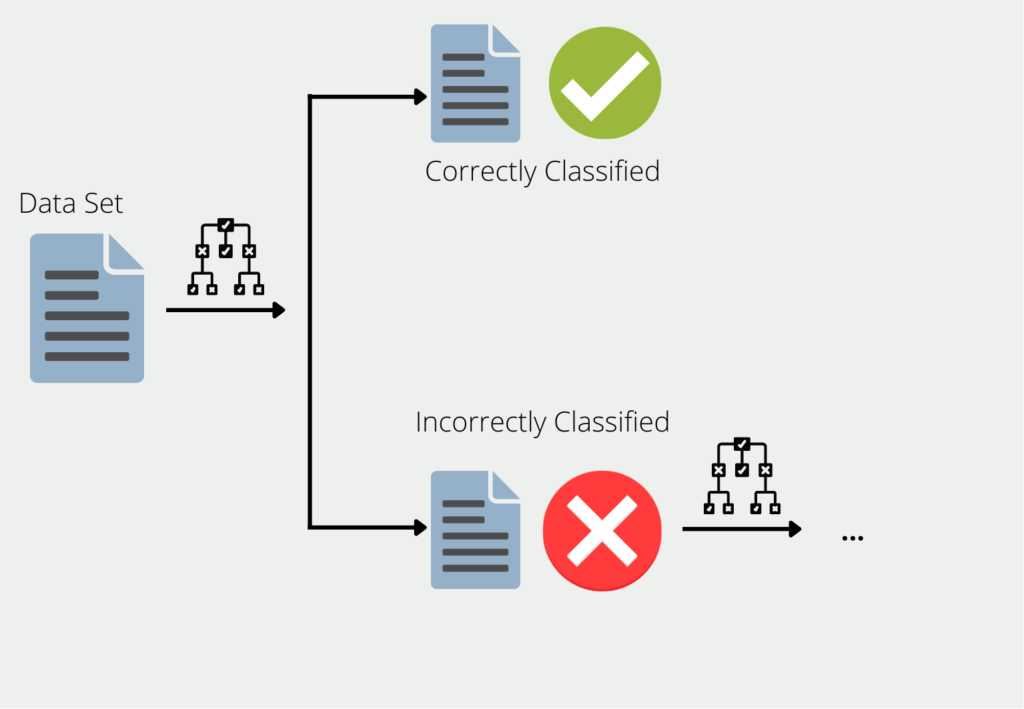
Das Ensemble aus all diesen Decision Trees kann dann für den gesamten Datensatz gute Ergebnisse liefern, da jedes einzelne Modell die Schwächen der anderen kompensiert. Man spricht auch davon, dass viele “schwache Lerner” (english: weak learners) zu einem “starken Lerner” (english: “strong learner”) zusammengefasst werden.
Man spricht von schwachen Lernern, da diese in vielen Fällen nur eher schlechte Ergebnisse liefern. Ihre Genauigkeit ist in vielen Fällen zwar besser als einfaches Raten, aber auch nicht deutlich besser. Sie bieten jedoch den Vorteil, dass sie in vielen Fällen einfach zu berechnen sind und dadurch sich einfach und kostengünstig kombinieren lassen.
Was ist Gradient Boosting?
Das Gradient Boosting wiederum ist eine Untergruppe von vielen, verschiedenen Boosting Algorithmen. Die Grundidee dahinter ist, dass das nächste Modell so gebaut werden sollte, dass es die Verlustfunktion des Ensembles weiter minimiert.
In den einfachsten Fällen beschreibt die Verlustfunktion einfach die Differenz zwischen der Vorhersage des Modells und dem tatsächlichen Wert. Angenommen wir trainieren eine KI zur Vorhersage eines Hauspreises. Die Verlustfunktion könnte dann einfach der Mean Squared Error zwischen dem tatsächlichen Preis des Hauses und dem vorhergesagten Preis des Hauses sein. Im Idealfall nähert sich die Funktion im Lauf der Zeit null an und unser Modell kann korrekte Preise vorhersagen.
Es werden solange neue Modelle hinzugefügt, wie sich Vorhersage und Realität nicht mehr unterscheiden, also die Verlustfunktion das Minimum erreicht hat. Jedes neue Modell versucht dabei den Fehler des vorherigen Modells vorherzusagen.
Kommen wir zurück zu unserem Beispiel mit den Hauspreisen. Angenommen ein Objekt hat eine Wohnfläche von 100m², vier Zimmer, eine Garage und kostet 200.000€. Der Ablauf des Gradient Boostings würde dann wie folgt aussehen:
- Training einer Regression zur Vorhersage des Kaufpreises mit den Features Wohnfläche, Anzahl Zimmer und Garage. Dieses Modell sagt einen Kaufpreis von 170.000 € vorher anstatt den tatsächlichen 200.000 €, der Fehler beträgt also 30.000 €.
- Training einer weiteren Regression die den Fehler des vorherigen Modells vorhersagt mit den Features Wohnfläche, Anzahl Zimmer und Garage. Dieses Modell sagt eine Abweichung von 23.000 € voraus anstatt den tatsächlichen 30.000 €. Der verbleibende Fehler beträgt also 7.000 €.
Was sind die Vor- und Nachteile von Boosting im Allgemeinen?
Der allgemeine Vorteil von Boosting ist, dass viele schwache Lerner zu einem starken und leistungsfähigen Modell kombiniert werden. Trotz der großen Anzahl der kleinen Modelle sind diese Boosting Algorithmen meist einfacher zu berechnen als vergleichbare Neuronale Netzwerke. Das muss jedoch nicht bedeuten, dass sie auch schlechtere Ergebnisse liefern. Teilweise können Ensemble Modelle die komplexeren Netzwerke sogar im Hinblick auf die Genauigkeit schlagen. Somit sind sie auch interessante Kandidaten für Text- oder Bildklassifikationen.
Darüber hinaus neigen Boosting Algorithmen, wie beispielsweise auch AdaBoost, auch weniger zu Overfitting. Dies bedeutet einfach gesagt, dass sie nicht nur mit dem Trainingsdatensatz gute Ergebnisse liefern, sondern auch mit neue Daten mit einer hohen Genauigkeit gut klassifizieren. Man geht davon aus, dass die mehrstufige Modellberechnung von Boosting Algorithmen nicht so anfällig für Abhängigkeiten, wie die Schichten in einem Neuronalen Netzwerk, da die Modelle nicht zusammenhängend optimiert werden, wie dies bei der Backpropagation im Modell der Fall ist.
Durch das schrittweise Trainieren von Einzelmodellen haben Boosting Modelle oft eine relativ langsame Lernrate und benötigen dadurch mehr Iterationen um gute Ergebnisse zu liefern. Des Weiteren benötigen sie sehr gute Datensätze, da die Modelle sehr sensibel auf Noise reagieren und dieses somit im Data Preprocessing entfernt werden sollte.
Was sind die Nachteile von Gradient Boosting?
Das Gradient Boosting ist eine beliebte Wahl für verschiedenste Anwendungen, da es sich auf verschiedenste Szenarien anpassen lässt. Trotz dieser zahlreichen Vorteile gibt es jedoch auch einige Nachteile oder Einschränkungen, die bei der Nutzung beachtet werden sollten:
- Overfitting: Das Gradient Boosting neigt zu Overfitting, wenn die Hyperparameter nicht optimal eingestellt sind bzw. die Modellkomplexität zu hoch ist. Dadurch wird die Generalisierungsleistung beeinträchtigt, sodass das Modell keine guten Vorhersagen für neue Daten liefert.
- Zeit- und Ressourcenverbrauch: Ein weiteres Problem bei Boosting Methoden allgemein ist die verlängerte Trainingszeit, da mehr Modelle trainiert werden, die Rechenressourcen in Anspruch nehmen. Deshalb sollte bei Gradient Boosting darauf geachtet werden, dass die maximale Tiefe der Bäume und die Anzahl der Blätter definiert wird, um den Rechenaufwand zu begrenzen.
- Begrenzte Interpretierbarkeit: Durch die Kombination der verschiedenen Modelle lässt sich eine einzelne Vorhersage nur sehr schwierig interpretieren. Dadurch wird das Modell zu einer Black-Box, sodass sich die Rückschlüsse nicht direkt nachvollziehen lassen. Wenn für die Anwendung ein transparentes Modell mit einer guten Interpretierbarkeit benötigt wird, sollte besser auf einen einzelnen Decision Tree zurückgegriffen werden.
- Vorverarbeitung der Daten: Die Modellleistung bei einem Gradient Boosting Modell ist auch maßgeblich von der Vorverarbeitung der Daten abhängig. Dazu zählt beispielsweise, dass kategorische Variablen kodiert werden oder die Merkmale skaliert sind. Wenn dies nicht der Fall ist, kann es erhebliche, negative Auswirkungen auf die Modellleistung haben. Außerdem führen Ausreißer oft zu schlechteren Ergebnissen und sollten deshalb aus dem Datensatz entfernt werden.
- Unausgewogene Daten: Für Klassifizierungsaufgaben ist die Ausgeglichenheit des Datensatzes immens wichtig, um ein aussagekräftiges Gradient Boosting Modell zu trainieren. Ansonsten kann es zu erheblich verzerrten Modellen kommen.
Abschließend ist das Gradient Boosting eine leistungsstarke Methode, die viele Vorteile mit sich bringt. Wenn die in diesem Abschnitt genannten Punkte beim Training berücksichtigt werden, steht einem leistungsstarken Modell nichts im Wege.
Gradient Boosting vs. AdaBoost
Bei AdaBoost werden viele verschiedene Decision Trees mit nur einer Entscheidungsebene, also sogenannte Decision Stumps, sequenziell mit den Fehlern der vorherigen Modelle zu trainieren. Beim Gradient Boosting hingegen wird versucht durch die sequenzielle Anordnung die Verlustfunktion immer weiter zu minimieren, indem nachfolgende Modelle darauf trainiert werden das sogenannte Residual, also die Differenz zwischen Vorhersage und dem tatsächlichen Wert, weiter zu verringern.

Dadurch lassen sich mit dem Gradient Boosting Regressionen, also die Vorhersage von stetigen Werten, als auch Klassifikationen, also die Einordnung in Gruppen, vornehmen. Der AdaBoost Algorithmus hingegen kann nur für Klassifizierungen genutzt werden. Dies ist tatsächlich auch der Hauptunterschied zwischen diesen beiden Boosting Algorithmen, denn im Kerngedanken versuchen beide durch sequenzielles Lernen und die höhere Gewichtung von falschen Vorhersagen, schwache Lerner zu einem starken Modell zu kombinieren.
Welchen Boosting Algorithmus soll man wählen?
Im Bereich des Machine Learnings stehen verschiedene Boosting Algorithmen zur Verfügung, die alle Vor- und Nachteile haben. Die Wahl des richtigen Modellsl kann deshalb schnell schwieirig werden und hängt von unterschiedlichen Faktoren, wie beipsielsweise der Größe des Datensatzes und dem Grad der Interpretierbarkeit ab.
In diesem Abschnitt geben wir einen kurzen Überblick über die drei wichtigsten Boosting-Algorithmen und wann diese gewählt werden sollten:
- AdaBoost (Adaptive Boosting) ist eine beliebte Wahl für Klassifizierungsaufgaben. Dabei werden mehrere schwache Klassifikatoren kombiniert und in mehreren Iterationen trainiert. Die Durchläufe unterscheiden sich dadurch, dass die Trainingsproben Gewichtungen erhalten und damit ein neuer Klassifikator trainiert wird. Dadurch wird es dem Boosting Algorithmus ermöglicht, sich mehr auf die falsch klassifizierten Trainingsbeispiele zu konzentrieren. Deshalb eignet sich AdaBoost für Klassifizierungsaufgaben mit mittelgroßen Datensätzen.
- XGBoost (Extreme Gradient Boosting) nutzt Decision Trees als Basis und beruht außerdem auf der Regularisierung, um eine Überanpassung zu verhindern. Dadurch können auch große Datensätze mit hochdimensionalen Merkmalen verarbeitet werden. Außerdem lassen sich sowohl Regressions- als auch Klassifikationsaufgaben besonders leistungsfähig verwirklichen. Dadurch ist XGBoost ein sehr breit aufgestelltes Modell, das für viele Anwendungen genutzt werden kann.
- Gradient Boosting ist ein sehr allgemeiner Ansatz, der mit verschiedenen Verlustfunktionen und zugrundeliegenden Modellen individualisiert werden kann. Dabei wird durch die Kombination verschiedener schwacher Lerner ein starker Lerner gebildet, der die Verlustfunktion so weit wie möglich minimiert. Durch diesen flexiblen Aufbau können verschiedenen Datentypen, insbesondere auch kategorische Merkmale, abgebildet werden.
Somit wird AdaBoost vor allem für einfache Klassifizierungsaufgaben mit kleinen bis mittelgroßen Datensätzen genutzt. Für große Datensätze mit hochdimensionalen Merkmalen hingegen ist XGBoost eine gute Wahl, da durch die Regulaisierung Overfitting effektiv verhindert wird. Das Gradient Boosting hingegen ist gewissermaßen die Mitte zwischen diesen
Das solltest Du mitnehmen
- Gradient Boosting ist eine Machine Learning Methode aus dem Bereich der Boosting Algorithmen.
- Das Ziel ist es, mehrere sogenannte “weak learners” zu einem leistungsfähigen Modell zusammenzufügen.
- Beim Gradient Boosting werden dazu hintereinander mehrere Modelle trainiert, die jeweils versuchen den vorherigen Fehler gut vorherzusagen.

Was ist eine Boltzmann Maschine?
Die Leistungsfähigkeit von Boltzmann Maschinen freisetzen: Von der Theorie zu Anwendungen im Deep Learning und deren Rolle in der KI.

Was ist die Gini-Unreinheit?
Erforschen Sie die Gini-Unreinheit: Eine wichtige Metrik für die Gestaltung von Entscheidungsbäumen beim maschinellen Lernen.

Was ist die Hesse Matrix?
Erforschen Sie die Hesse Matrix: Ihre Mathematik, Anwendungen in der Optimierung und maschinellen Lernen.

Was ist Early Stopping?
Beherrschen Sie die Kunst des Early Stoppings: Verhindern Sie Overfitting, sparen Sie Ressourcen und optimieren Sie Ihre ML-Modelle.

Was sind Gepulste Neuronale Netze?
Tauchen Sie ein in die Zukunft der KI mit Gepulste Neuronale Netze, die Präzision, Energieeffizienz und bioinspiriertes Lernen neu denken.

Was ist RMSprop?
Meistern Sie die RMSprop-Optimierung für neuronale Netze. Erforschen Sie RMSprop, Mathematik, Anwendungen und Hyperparameter.
Andere Beiträge zum Thema Gradient Boosting
Eine Anleitung für Gradient Boosting in Scikit-Learn findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.