Batch normalization has become a very important technique for training neural networks in recent years, as it makes training much more efficient and stable, which is a crucial factor, especially for large and deep networks. It was originally introduced to solve the problem of internal covariance shift.
In this article, we will examine the problems involved in training neural networks and how batch normalization can solve them. We will describe the process in detail and show how batch normalization can be implemented in Python and integrated into existing models. We will also consider the advantages and disadvantages of this method to determine whether it makes sense to use it.
What Problems arise when training Deep Neural Networks?
When training a deep neural network, backpropagation occurs after each run. The prediction error runs through the network layer by layer from behind. During this process, the weights of the individual neurons are then changed so that the error is reduced as quickly as possible. This changes the weights under the assumption that all other layers remain the same. In practice, however, these conditions only apply to a limited extent, as all layers are changed quickly during backpropagation. In the paper “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” this core problem is described in more detail.
The problem with this fact is that the statistical key figures of the value distribution also change with each change in the weightings. This means that after each run, the weights in a stratum have a new distribution with a different mean value and a new standard deviation. This problem is known as an internal covariance shift and leads to more difficult training, as the subsequent layers cannot optimally process the changed distribution.
To still have successful training, lower learning rates must be used to minimize the fluctuations in the weight changes. However, this means that the model takes significantly longer to converge and training is slowed down overall.
What is Normalization?
The normalization of data is a process that is often used in the preparation of data sets for machine learning. The aim is to bring the numerical values of different attributes onto a common scale. For example, you can divide all numerical values in a data series by the maximum value of the data series to obtain a new data series that lies in the range from 0 to 1.
Suppose you want to train a model to learn different marketing activities and their effect on sales and the quantity sold. You could simply calculate the sum of the quantity sold and the turnover as the dependent variable. However, this can quickly lead to distorted results, for example, if you have a product series in which many products are sold, but these have a relatively low unit price. In a second series, it can be the other way around, i.e. the products are not sold as often, but have a high unit price.
A marketing campaign that leads to 100,000 products being sold, for example, is rated worse in the product series with low unit prices than in the product series with high unit prices. Similar problems also arise in other fields, for example when looking at the private expenditure of individuals. For two different people, food expenditure of €200 can be very different when set concerning monthly income. Normalization therefore helps to bring the data onto a neutral and comparable basis.
What is Batch Normalization?
Batch normalization was introduced to mitigate the problem of internal covariance shifts. Batches are used for this purpose, i.e. certain subsets of the data set with a fixed size, which contain a random selection of the data set in a training run. The main idea is that the activations of each layer within a batch are normalized so that they have a constant mean value of 0 and a constant standard deviation of 1. This additional step reduces the shift of the activation distributions so that the model learns faster and converges better. In addition, poorly chosen initial values can lead to stagnation or slow progress.
How does Batch Normalization work?
When training neural networks, the entire data set is divided into so-called batches. These contain a random selection of data of a certain size and are used for a training run. In most cases, a so-called batch size of 32 or 64 is used, i.e. there are 32 or 64 individual data points in a batch.
The input data that arrives in the input layer of the network is already normalized during normal data preprocessing. This means that all numerical values have been brought to a uniform scale and a common distribution and are therefore comparable. In most cases, the data then has a mean value of 0 and a standard deviation of 1.
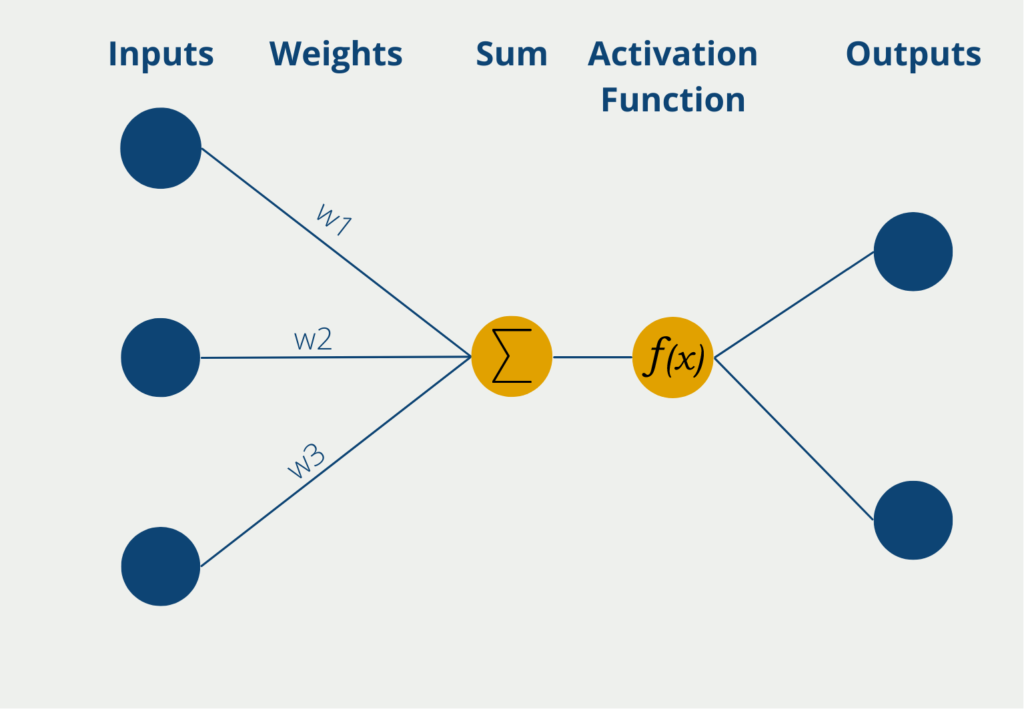
After the first layer, however, the values have already passed through the so-called activation function, which leads to a shift in the distribution and thus denormalizes the values again. An activation function is run through again with each layer in the network and the numbers are no longer normalized in the output layer. This process is also called “internal covariate shift” in the technical literature (Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift).
For this reason, the values are normalized again before each activation function during batch normalization. The following steps are carried out for this purpose.
1. Calculation of the Mean Value and the Variance per Mini-Batch
First, the mean value and the variance for the entire mini-batch are calculated for each activation in a specific layer. If \(x_i\) stands for any activation value of a neuron for a data point \(i\), then the mean \( \mu_{\text{batch}}\) and the variance \(\sigma^2_{\text{batch}}\) are calculated as follows:
\(\)\[\mu_{batch}=\ \frac{1}{m}\sum_{i=1}^{m}x_i \]
\(\)\[\sigma^2_{batch}=\ \frac{1}{m}\sum_{i=1}^{m}{(x_i-\ \mu_{batch})}^2\]
Here, \(m\) is the number of data points in a mini-batch. As these key figures are recalculated for each layer, this ensures that the batch normalization can react flexibly to the different distributions.
2. Normalization of the Activations
In this step, the activations are normalized so that they have a mean value of 0 and a standard deviation of 1. This is done by subtracting the mean of the batch from each activation and dividing it by the standard deviation. To avoid dividing by 0, a small value is added to the variance. This then results in the following formula:
\(\)\[{\hat{x}}_i=\ \frac{x_i-\ \mu_{batch}}{\sqrt{\sigma_{batch}^2+\ \varepsilon}} \]
Here \(\hat{x}_i\) is the normalized activation value for the data point \(i\).
3 Scaling and Shifting the Normalized Activations
After the normalization has taken place, a further step is carried out to give the model more flexibility. Two learnable parameters \(\gamma\) and \(\beta\) are added to scale and shift the normalized values. This allows the model to reverse the normalization if the original distribution of the data was reasonable. The final transformed activation parameters are then calculated as follows:
\(\)\[y_i=\ \gamma\cdot\ {\hat{x}}_i+\ \beta\]
Here, \(\gamma\) is the scaling parameter that determines how strongly the normalized values are scaled, and \(\beta\) is the shift parameter that can shift the values along the y-axis.
The process of batch normalization ensures that the activations in the different layers of the neural network are optimally scaled and that the training is therefore stable. These calculations take place thousands or even millions of times during training, which is why it is very good that we can use simple functionalities in Python for the implementation and do not have to perform these calculations manually. In the next section, we will therefore take a closer look at how this procedure can be implemented in Python.
How can Batch Normalization be implemented in Python?
To implement batch normalization in Python, we can use the TensorFlow library, which already has a built-in function tf.keras.layers.BatchNormalization and can be built directly into a model. As an example, we take a simple Convolutional Neural Network, which we train on the MNIST dataset. We apply the batch normalization after each convolutional or dense layer to stabilize the activations:
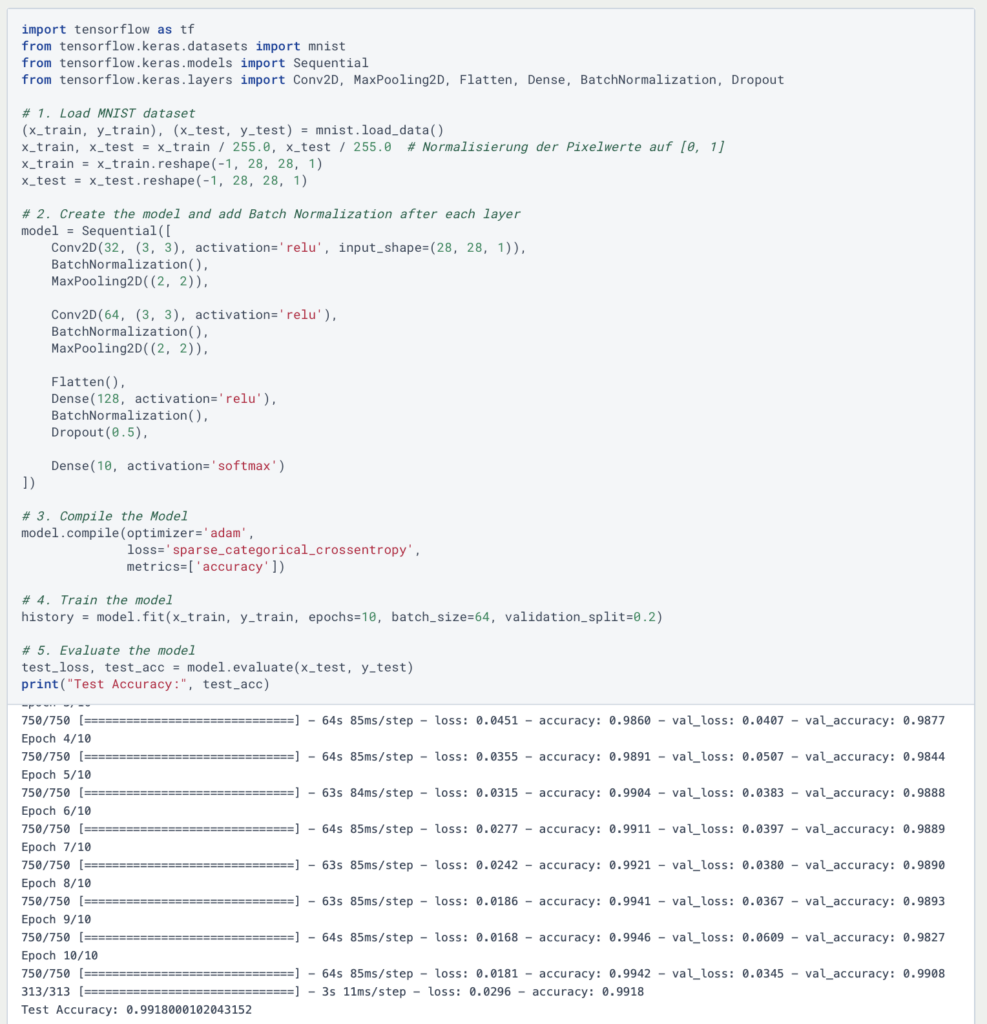
As you can see, batch normalization is simply inserted into the model after each activation layer. No hyperparameters need to be determined, as the function calculates the mean and variance automatically and then adjusts the learnable parameters automatically.
What are the Advantages and Disadvantages of Batch Normalization?
Batch normalization has many advantages, especially when training deep neural networks, as it speeds up training and makes it more stable. However, it is not always the optimal choice for every architecture. Therefore, it is important to know the advantages and disadvantages, which we will explain in more detail in this section.
Advantages:
- Faster convergence: Batch Normalization stabilizes the distribution of activations and thus enables a faster learning process so that fewer epochs are needed to achieve a good result. In addition, higher learning rates can also be used, which in turn lead to faster training.
- Bypassing the internal covariate shift: As already described, the internal covariate shift can at least be mitigated by normalizing the batch. This occurs, for example, in image classifications in which a distinction is to be made between different classes, such as dogs and cats. The different coat colors can lead to different distributions of the image data, which can be smoothed out using batch normalization.
- Less dependence on weight initialization: Without batch normalization, the choice of initial weights can have a strong influence on the training result and process. This is prevented by continuous normalization, making the training more robust even if the initialization is not optimal.
- Preventing overfitting: Without normalization, outliers in training data can lead to a strong adjustment of the model, so that it delivers good results for the training data but generalizes poorly. It also reduces the need for other regularization methods, such as a dropout layer.
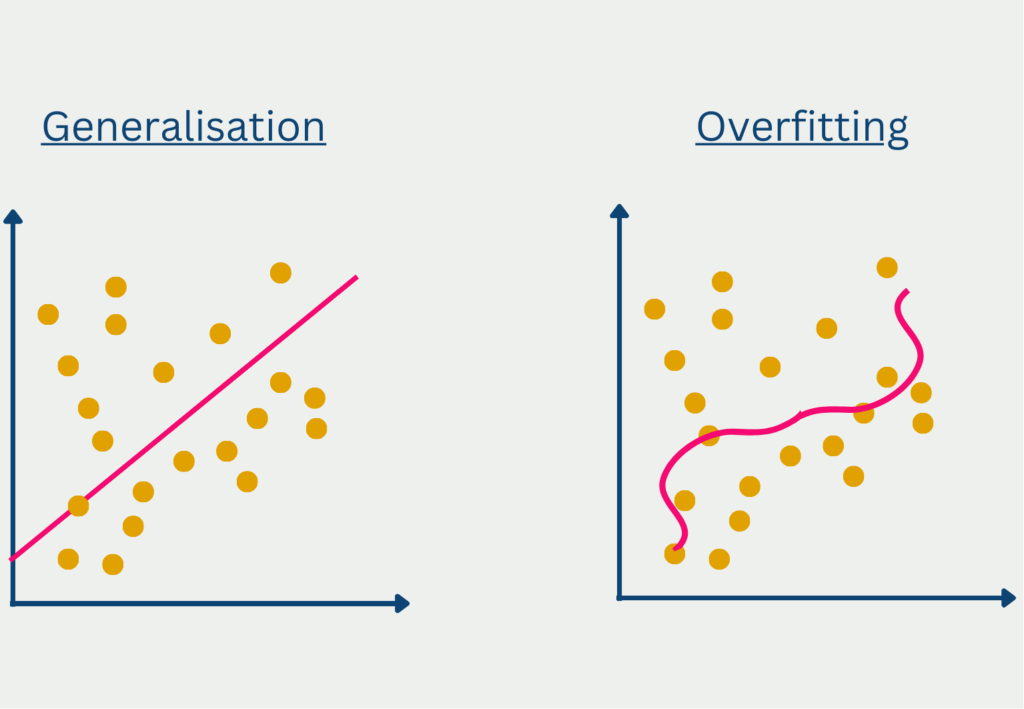
- Different network types possible: Batch normalization can be used with different types of neural networks and often leads to good results. For example, a normalization layer can be built into convolutional or feedforward neural networks.
Disadvantages:
- Dependence on batch size: For the estimates for the variance and mean to be sufficiently accurate, you need a large amount of data in the batch. However, it can happen in various applications that the batch size is very small, for example, if the data is very memory-intensive or for small devices, and therefore the statistical estimates are too unstable.
- Difficulties with predictions: During the training phase, the statistical estimates can simply be calculated from the mini-batches. When predicting new data, however, these batches are missing, so fixed values calculated during training must be used. In some cases, this can lead to discrepancies between the model performance during training and interference.
- Limited applicability of recurrent networks: Recurrent neural networks are characterized by the fact that they process input sequences with varying lengths. This makes it difficult to calculate batch statistics across sequences. For this reason, variants of batch normalization are often used for such models, which have been specially adapted for this purpose.
- Increased computational effort: The introduction of batch normalization means that more calculations have to be carried out during training, which means additional computational complexity. In most cases, this is offset by the faster convergence and the computing power saved, but depending on the model architecture and the training data, it can also lead to increased computational effort compared to a model without batch normalization.
How should the model be structured?
There are a few things to consider when building a model with a batch normalization layer. Among other things, the learning rate should be increased by including the normalization layer. Normalization makes the model more stable, which is why it can change the weightings more quickly and still converge.
At the same time, the use of a dropout layer should be avoided. On the one hand, normalization already provides an additional degree of generalization, which is why the dropout layer may not even be necessary. On the other hand, it can even worsen the result, as noise is generated by the normalization and the simultaneous omission of neurons.
Finally, it may be useful to vary the position of the batch normalization and to test both the normalization before and after the activation function. Depending on the structure of the model, this can lead to better results.
What Variants and Extensions of Batch Normalization are there?
For most neural network architectures, batch normalization has proven to be a useful tool for circumventing the internal covariance shift and achieving faster convergence. However, problems can also arise with recurrent neural networks or small batch sizes. For this reason, different variants of the model have been developed over the years to overcome these disadvantages.
1. Layer Normalization
This method normalizes the activations within a layer and not within a batch. For each input example, the neurons in a layer are normalized separately and must be recalculated in each step. This property makes layer normalization particularly suitable for recurrent neural networks, as it is not only well suited for sequential data but also acts independently of the batch size. Due to these properties, it is often used in the field of natural language processing or for sequential tasks.
2. Group Normalization
With this method, the activations are divided into different groups and then normalized within the groups. It is therefore particularly suitable for image processing, where only small batch sizes are possible because the image files often require a lot of storage space. Group Normalization strikes a balance between dependency on batch size and flexibility in handling different amounts of data.
3. Batch Renormalization
This approach is an extension of Batch Normalization, which was developed to better handle small batch sizes. It introduces additional parameters that strengthen the estimation of the mean and variance, even if the batch statistics are unstable. This enables stable training with fast convergence even for small batch sizes.
These variants enable the use of batch normalization in different application scenarios, so that the disadvantages can be overcome even with demanding models and stable training can be carried out.
This is what you should take with you
- Batch normalization is used in deep neural networks to avoid the so-called internal covariance shift. This refers to the phenomenon that training takes place more slowly because the distribution of the data changes after each activation.
- Batch normalization avoids this by splitting the data set into batches and normalizing them again after each activation so that a mean value of 0 and a standard deviation of 1 is achieved.
- In Python, the TensorFlow library can be used to incorporate this method into an existing network. It should be tested whether it is added before or after a layer.
- When using batch normalization, some factors should be considered when building a deep neural network such as leaving out a dropout layer which could otherwise have a bad influence on the results.
- For use in recurrent neural networks or with smaller batches, different variants of batch normalization have emerged over the years that compensate for the disadvantages of the conventional method.

What is a Boltzmann Machine?
Unlocking the Power of Boltzmann Machines: From Theory to Applications in Deep Learning. Explore their role in AI.

What is the Gini Impurity?
Explore Gini impurity: A crucial metric shaping decision trees in machine learning.

What is the Hessian Matrix?
Explore the Hessian matrix: its math, applications in optimization & machine learning, and real-world significance.

What is Early Stopping?
Master the art of Early Stopping: Prevent overfitting, save resources, and optimize your machine learning models.

What is RMSprop?
Master RMSprop optimization for neural networks. Explore RMSprop, math, applications, and hyperparameters in deep learning.

What is the Conjugate Gradient?
Explore Conjugate Gradient: Algorithm Description, Variants, Applications and Limitations.
Other Articles on the Topic of Batch Normalization
- The Keras documentation on the Batch Normalization Layer can be found here.
- Machine Learning Mystery’s article on Batch Normalization is also well worth reading and was used as a source for this post.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.