Die Batch Normalization hat sich in den vergangenen Jahren zu einer sehr wichtigen Technik beim Training von neuronalen Netzwerken entwickelt, da sie das Training deutlich effizienter und stabiler macht, was vor allem bei großen und tiefen Netzwerken ein entscheidender Faktor ist. Sie wurde ursprünglich eingeführt, um das Problem der internen Kovarianzverschiebung zu lösen.
In diesem Beitrag werden wir uns genauer mit den Problemen beim Training von Neuronalen Netzwerken beschäftigen und wie diese durch die Batch Normalization gelöst werden können. Dazu gehen wir im Detail auf den Prozess ein und zeigen auch, wie sich die Batch Normalization in Python umsetzen und in bestehende Modelle integrieren lässt. Zu einem vollständigen Bild gehört es auch, sich mit den Vor- und Nachteilen dieser Methode zu beschäftigen, um festzustellen, ob die Anwendung sinnvoll ist.
Welche Probleme ergeben sich beim Training von Deep Neural Networks?
Beim Training eines tiefen Neuronalen Netzwerks findet nach jedem Durchlauf die sogenannte Backpropagation statt. Dabei durchläuft der Vorhersagefehler von hinten das Netzwerk Schicht für Schicht. Währenddessen werden dann die Gewichtungen der einzelnen Neuronen so geändert, dass sich der Fehler möglichst schnell verringert. Dadurch verändert man die Gewichte unter der Annahme, dass alle anderen Schichten gleichbleiben. In der Praxis gilt diese Bedingungen jedoch nur bedingt, da während der Backpropagation alle Schichten schnell hintereinander geändert werden. In dem Paper “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” wird dieses Kernproblem genauer beschrieben.
Das Problem an dieser Tatsache ist, dass sich mit jeder Änderung der Gewichtungen auch die statistischen Kennzahlen der Werteverteilung ändert. Das heißt nach jedem Durchlauf haben die Gewichte in einer Schicht eine neue Verteilung mit anderem Mittelwert und neuer Standardabweichung. Dieses Problem wird als interne Kovarianzverschiebung, oder auf englisch als Internal Covariance Shift, bezeichnet und führt zu einem erschwerten Training, da die nachfolgenden Schichten die veränderte Verteilung nicht optimal verarbeiten können.
Damit man trotzdem ein erfolgreiches Trainign hat, muss man niedrigere Lernraten nutzen, um die Schwankungen in den Gewichtsänderungen zu minimieren. Dadurch benötigt das Modell jedoch deutlich länger, um zu konvergieren und das Training wird insgesamt verlangsamt.
Was ist Normalisierung?
Die Normalisierung von Daten ist ein Prozess, der häufig in der Aufbereitung von Datensätzen für Machine Learning genutzt wird. Dabei sollen die Zahlenwerte von verschiedenen Attributen auf eine gemeinsame Skala gebracht werden. Dazu kann man beispielsweise alle Zahlenwerte in einer Datenreihe durch den maximalen Wert der Datenreihe teilen und erhält dadurch eine neue Datenreihe, welche im Bereich von 0 bis 1 liegt.
Angenommen man will ein Modell trainieren, das verschiedene Marketingaktivitäten und deren Auswirkung auf den Umsatz und die verkaufte Menge erlernen soll. Dazu könnte man als abhängige Variable einfach die Summe aus verkaufter Menge und dem Umsatz berechnen. Dies kann aber schnell zu verzerrten Ergebnissen führen, beispielsweise, wenn man eine Produktserie hat, in der zwar viele Produkte verkauft werden, diese aber einen verhältnismäßigen geringen Stückpreis haben. In einer zweiten Serie kann es genau andersrum sein, also die Produkte werden zwar nicht so oft verkauft, haben dafür aber einen hohen Stückpreis.
Eine Marketingaktion, die dann beispielsweise zu 100.000 verkauften Produkten führt, ist in der Produktserie mit niedrigen Stückpreisen schlechter zu bewerten als in der Produktserie mit hohen Stückpreisen. Ähnliche Problemstellungen ergeben sich auch in anderen Feldern, zum Beispiel, wenn man sich die privaten Ausgaben von einzelnen Personen anschaut. Für zwei verschiedene Personen können Lebensmittelausgaben von 200 € sehr unterschiedlich sein, wenn man sie im Verhältnis zum monatlichen Einkommen setzt. Deshalb hilft die Normalisierung die Daten auf eine neutrale und vergleichbare Basis zu bringen.
Was ist die Batch Normalization?
Die Batch Normalization wurde eingeführt, um die Problematik des Internal Covariance Shifts abzumildern. Dafür werden sogenannte Batches genutzt, also gewisse Teilmengen des Datensatzes mit einer festen Größe, welche eine zufällige Auswahl des Datensatzes in einem Trainingsdurchlauf enthalten. Die Hauptidee ist nun, dass die Aktivierungen jeder Schicht innerhalb eines Batchs so normalisiert werden, dass sie einen konstanten Mittelwert von 0 und eine konstante Standardabweichung von 1 haben. Durch diesen zusätzlichen Schritt wird die Verschiebung der Aktivierungsverteilungen reduziert, sodass das Modell schneller lernt und besser konvergiert. Außerdem kann es bei schlecht gewählten Anfangswerten zu Stagnation oder nur langsamen Fortschritt kommen.
Wie funktioniert die Batch Normalization?
Beim Training von neuronalen Netzwerken wird der komplette Datensatz in sogenannte Batches aufgeteilt. Diese enthalten eine zufällige Auswahl von Daten einer gewissen Größe und werden für einen Trainingsdurchlauf genutzt. In den meisten Fällen wird eine sogenannte Batch Size von 32 oder 64 verwendet, also befinden sich 32 oder 64 einzelne Datenpunkte in einem Batch.
Die Inputdaten, die in der Eingabeschicht des Netzwerkes ankommen, sind bei einem normalen Data Preprocessing bereits normalisiert. Das bedeutet, dass alle numerischen Werte auf eine einheitliche Skala und eine gemeinsame Verteilung gebracht worden und somit vergleichbar sind. Meist haben die Daten dann einen Mittelwert von 0 und eine Standardabweichung von 1.
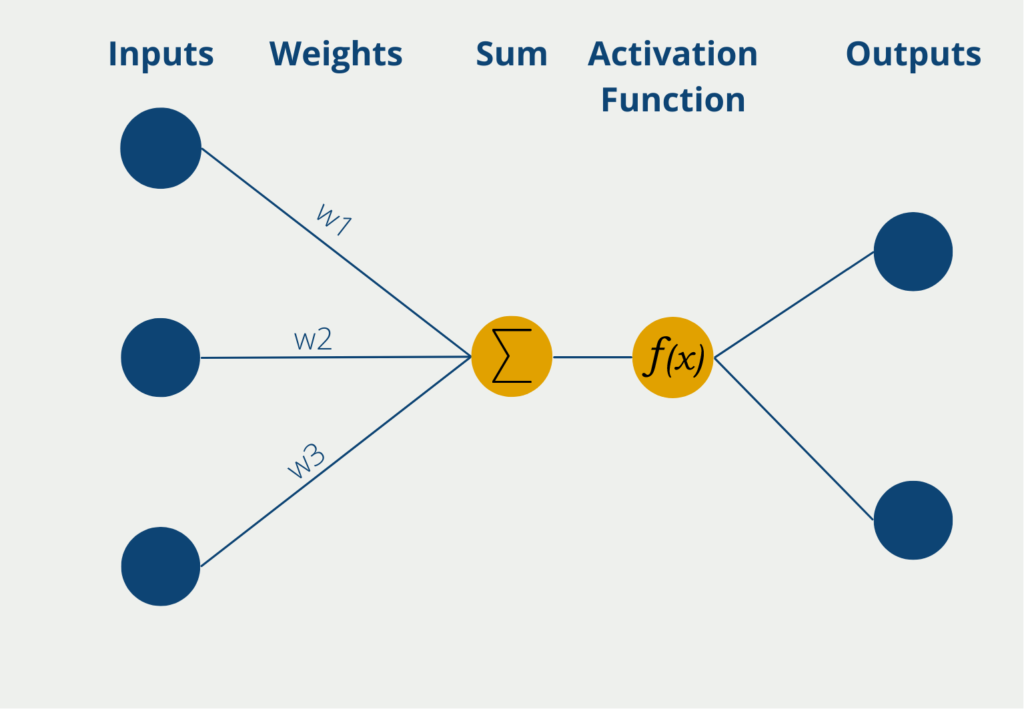
Bereits nach der ersten Schicht jedoch haben die Werte die sogenannte Aktivierungsfunktion durchlaufen, welche zu einer Verschiebung der Verteilung führt und die Werte somit wieder denormalisiert. Mit jeder Schicht im Netzwerk wird wieder eine Aktivierungsfunktion durchlaufen und in der Ausgabeschicht sind die Zahlen nicht mehr normalisiert. Diesen Prozess nennt man in der Fachliteratur auch “internal covariate shift” (Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift).
Aus diesem Grund werden während der Batch Normalization die Werte vor jeder Aktivierungsfunktion wieder aufs Neue normalisiert. Hierfür werden die folgenden Schritte durchlaufen.
1. Berechnung des Mittelwerts und der Varianz pro Mini-Batch
Als Erstes wird für jede Aktivierung in einer bestimmten Schicht der Mittelwert und die Varianz für den gesamten Mini-Batch berechnet. Wenn \(x_i\) für einen beliebigen Aktivierungswert eines Neurons für einen Datenpunkt \(i\) steht, dann berechnet sich der Mittelwert \( \mu_{\text{batch}}\) und die Varianz \(\sigma^2_{\text{batch}}\) wie folgt:
\(\)\[\mu_{batch}=\ \frac{1}{m}\sum_{i=1}^{m}x_i \]
\(\)\[\sigma^2_{batch}=\ \frac{1}{m}\sum_{i=1}^{m}{(x_i-\ \mu_{batch})}^2\]
Dabei ist \(m\) die Anzahl der Datenpunkte in einem Mini-Batch. Da diese Kennzahlen für jede Schicht neu berechnet werden, wird dafür gesorgt, dass die Batch Normalization flexibel auf die unterschiedlichen Verteilungen reagieren kann.
2. Normalisierung der Aktivierungen
In diesem Schritt werden die Aktivierungen so normalisiert, dass sie einen Mittelwert von 0 und eine Standardabweichung von 1 besitzen. Dies passiert, indem der Mittelwert des Batchs von jeder Aktivierung abgezogen wird und durch die Standardverteilung geteilt wird. Um eine Division durch 0 zu vermeiden, wird zur Varianz ein kleiner Wert hinzugefügt. Dies resultiert dann in der folgenden Formel:
\(\)\[{\hat{x}}_i=\ \frac{x_i-\ \mu_{batch}}{\sqrt{\sigma_{batch}^2+\ \varepsilon}} \]
Hierbei ist \(\hat{x}_i\) der normalisierte Aktivierungswert für den Datenpunkt \(i\).
3. Skalierung und Verschiebung der normalisierten Aktivierungen
Nachdem die Normalisierung stattgefunden hat, wird noch ein weiterer Schritt durchgeführt, um dem Modell mehr Flexibilität zu geben. Dabei werden zwei lernbare Parameter \(\gamma\) und \(\beta\) hinzugefügt, um die normalisierten Werte zu skalieren und zu verschieben. Dies ermöglicht es dem Modell, die Normalisierung umzukehren, falls die ursprüngliche Verteilung der Daten sinnvoll war. Die final transformierten Aktivierungsparameter errechnen sich dann wie folgt:
\(\)\[y_i=\ \gamma\cdot\ {\hat{x}}_i+\ \beta\]
Hierbei ist \(\gamma\) der Skalierungsparameter, der darüber bestimmt, wie stark die normalisierten Werte skaliert werden und \(\beta\) ist der Verschiebungsparameter, der die Werte entlang der y-Achse verschieben kann.
Der Prozess der Batch Normalization sorgt dafür, dass die Aktivierungen in den verschiedenen Schichten des neuronalen Netzwerks optimal skaliert sind und das Training dadurch das stabil läuft. Diese Berechnungen finden während eines Trainings zu tausendfach oder sogar millionenfach statt, weshalb es sehr gut ist, dass wir für die Implementierung einfache Funktionalitäten in Python nutzen können und diese Rechnungen nicht von Hand durchführen müssen. Im nächsten Abschnitt schauen wir uns deshalb genauer an, wie sich dieses Vorgehen in Python umsetzen lässt.
Wie kann man die Batch Normalization in Python umsetzen?
Um die Batch Normalization in Python umsetzen, können wir die TensorFlow Bibliothek nutzen, welche bereits eine eingebaute Funktion mit dem Namen tf.keras.layers.BatchNormalization besitzt und direkt in ein Modell eingebaut werden kann. Als Beispiel dafür nehmen wir ein einfaches Convolutional Neural Network, welches wir auf den MNIST Datensatz trainieren. Die Batch Normalization wenden wir nach jeder Convolutional oder Dense Schicht an, um die Aktivierungen zu stabilisieren:
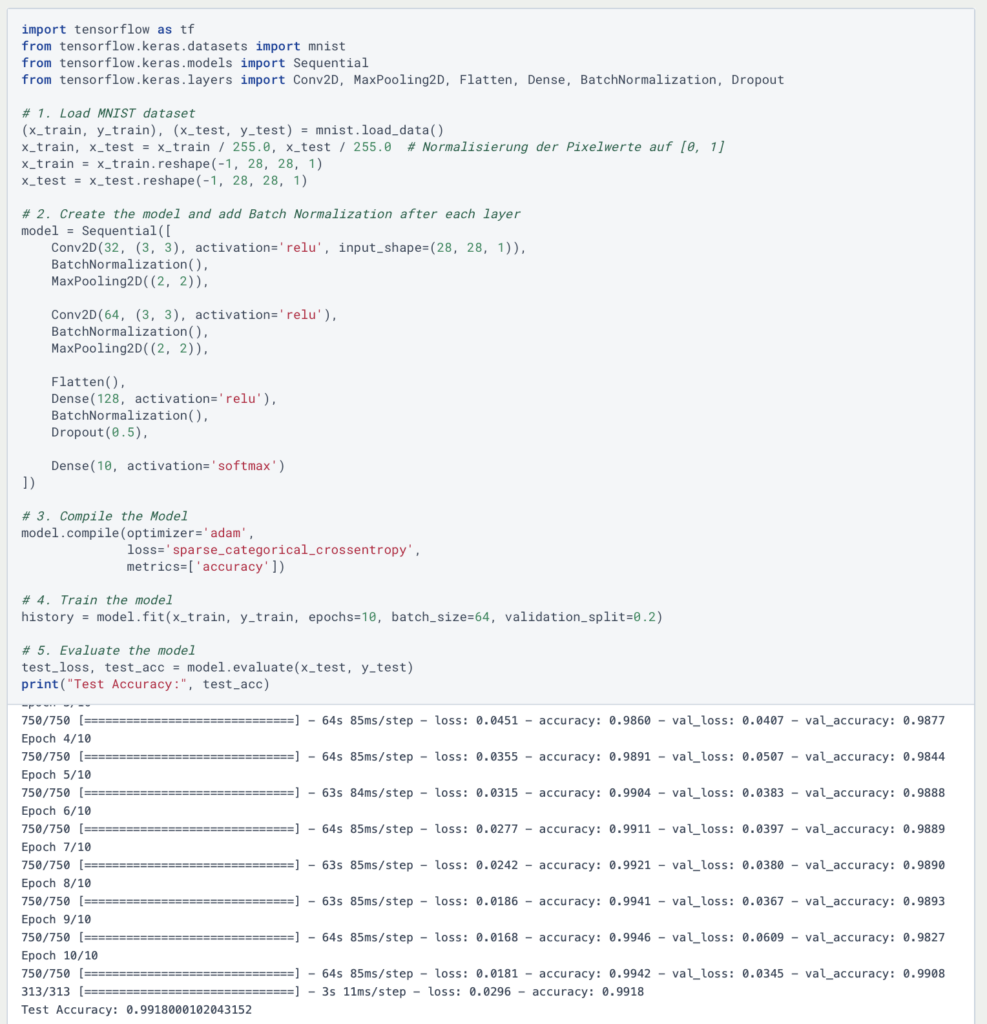
Wie man sehen kann, wird die Batch Normalization einfach nach jeder Aktivierungsschicht in das Modell eingefügt. Dabei müssen keine Hyperparameter bestimmt werden, da die Funktion von sich aus den Mittelwert und die Varianz berechnet und anschließend auch die lernbaren Parameter automatisch anpasst.
Was sind die Vor- und Nachteile der Batch Normalization?
Die Batch Normalization bringt viele Vorteile vor allem beim Training von tiefen, neuronalen Netzen, da es das Training beschleunigt und stabiler macht. Dennoch ist sie nicht immer die optimale Wahl für jede Architektur. Deshalb ist es wichtig, die Vor- und Nachteile zu kennen, die wir in diesem Abschnitt genauer erläutern werden.
Vorteile:
- Schnellere Konvergenz: Die Batch Normalization stabilisiert die Verteilung der Aktivierungen und ermöglicht dadurch einen schnelleren Lernprozess, sodass weniger Epochen benötigt werden, um ein gutes Ergebnis zu erzielen. Außerdem können auch höhere Lernraten verwendet werden, die wiederum zu einem schnelleren Training führen.
- Umgehung des Internal Covariate Shift: Wie bereits beschrieben, lässt sich durch die Normalisierung des Batchs der Internal Covariate Shift zumindest abmildern. Dieser tritt zum Beispiel bei Bildklassifizierungen auf, bei denen zwischen verschiedenen Klassen, wie Hunden und Katzen, unterschieden werden soll. Die verschiedenen Fellfarben können zu unterschiedlichen Verteilungen der Bilddaten führen, die sich durch die Batch Normalization glattziehen lassen.
- Geringere Abhängigkeit von der Gewichtsinitialisierung: Ohne die Batch Normalization kann es passieren, dass die Wahl der Anfangsgewichte, das Trainingsergebnis und den -verlauf stark beeinflussen. Dies wird durch die durchgehende Normalisierung verhindert, sodass das Training robuster wird, selbst wenn die Initialisierung nicht optimal verläuft.
- Verhindern von Overfitting: Ohne eine Normalisierung können Ausreißer in Trainingsdaten zu einer starken Anpassung des Modells führen, sodass es gute Ergebnisse für die Trainingsdaten liefert aber nur schlecht generalisiert. Außerdem wird die Notwendigkeit für andere Regularisierungsmethoden, wie zum Beispiel eine Dropout-Schicht geringer.
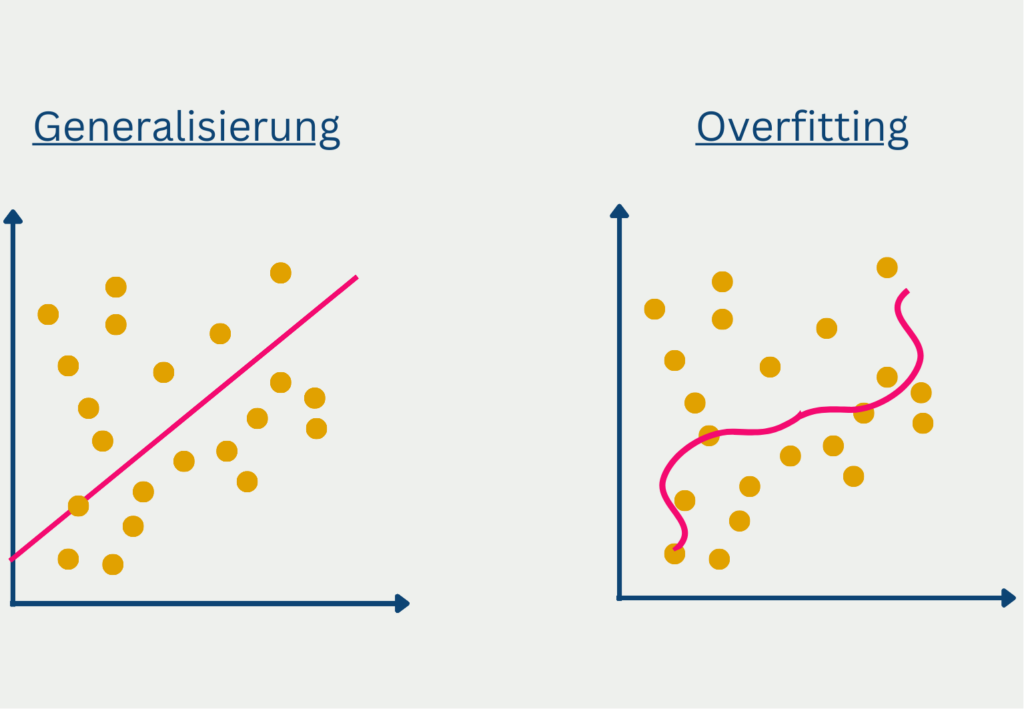
- Verschiedene Netzwerkarten möglich: Die Batch Normalization lässt sich mit den verschiedensten Arten von neuronalen Netzen nutzen und führt auch oft zu guten Ergebnissen. Beispielsweise kann man eine Normalisierungsschicht in Convolutional oder Feedforward Neural Networks einbauen.
Nachteile:
- Abhängigkeit von der Batch-Größe: Damit die Schätzungen für die Varianz und den Mittelwert ausreichend genau sind, benötigt man eine große Datenmenge im Batch. Jedoch kann es in verschiedenen Anwendungen passieren, dass die Batch-Größe sehr klein ist, beispielsweise wenn die Daten sehr speicherintensiv sind oder bei kleinen Geräten, und deshalb die statistischen Schätzungen zu instabil sind.
- Schwierigkeiten bei Vorhersagen: Während der Trainingsphase können die statistischen Schätzungen einfach aus den Mini-Batches errechnet werden. Bei der Vorhersage von neuen Daten hingegen, fehlen diese Batches, sodass auf feste Werte zurückgegriffen werden muss, die während dem Training errechnet wurden. Dadurch kann es in manchen Fällen zu Diskrepanzen zwischen den Modellleistungen im Training und während der Interferenz kommen.
- Eingeschränkte Anwendbarkeit Recurrent Netzen: Recurrent Neural Networks zeichnen sich dadurch aus, dass sie Eingabesequenzen mit variierenden Längen verarbeiten. Dies erschwert die Errechnung der Batch-Statistiken über Sequenzen hinweg. Deshalb werden in für solche Modelle häufig Varianten der Batch Normalization genutzt, die speziell darauf angepasst wurden.
- Erhöhter Rechenaufwand: Durch die Einführung der Batch Normalization müssen im Trainingsverlauf mehr Berechnungen durchgeführt werden, die zusätzliche Rechenkomplexität bedeuten. In den meisten Fällen wird dies durch die schnellere Konvergenz und die dort eingesparte Rechenleistung aufgehoben, jedoch kann es abhängig von der Modellarchitektur und den Trainingsdaten auch zu einem erhöhten Rechenaufwand kommen im Vergleich zu einem Modell ohne Batch Normalization.
Wie sollte das Modell aufgebaut sein?
Bei dem Aufbau eines Modells mit einer Batch Normalization Schicht gibt es einige Dinge zu beachten. Unter anderem sollte man mit dem Einbau der Normalisierungsschicht die Lernrate erhöhen. Durch die Normalisierung wird das Modell stabiler, weshalb es auch schneller die Gewichtungen abändern kann und trotzdem noch konvergiert.
Gleichzeitig sollte man auf die Nutzung einer Dropout Layer verzichten. Zum einen bietet die Normalisierung bereits ein zusätzliches Maß an Generalisierung, weshalb die Dropout Schicht möglicherweise gar nicht von Nöten ist. Zum anderen kann es sogar das Ergebnis verschlechtern, da durch die Normalisierung und das gleichzeitige Auslassen von Neuronen Noise erzeugt wird.
Schließlich kann es sinnvoll sein, die Position der Batch Normalization zu variieren und sowohl die Normalisierung vor als auch nach der Aktivierungsfunktion zu testen. Je nach Aufbau des Modells kann dies zu besseren Ergebnissen führen.
Welche Varianten und Erweiterungen der Batch Normalization gibt es?
Bei den meisten neuronalen Netzwerkarchitekturen hat sich die Batch Normalization als sinnvolles Werkzeug erwiesen, um den Internal Covariance Shift zu umgehen und eine schnellere Konvergenz zu erzielen. Jedoch kann es gerade bei Recurrent Neural Networks oder bei kleinen Batch-Größen auch zu Problemen kommen. Deshalb haben sich über die Jahre verschiedene Varianten des Modells entwickelt, die diese Nachteile beheben sollen.
1. Layer Normalization
Diese Methode normalisiert die Aktivierungen innerhalb einer Schicht und nicht innerhalb eines Batchs. Für jedes Eingabebeispiel werden dadurch die Neuronen in einer Schicht separat normalisiert und müssen in jedem Schritt neu berechnet werden. Durch diese Eigenschaft eignet sich die Layer Normalization vor allem für Recurrent Neural Networks, da sie nicht nur gut für sequenzielle Daten geeignet ist, sondern auch unabhängig von der Batch-Größe agiert. Aufgrund von diesen Eigenschaften kommt sie häufig im Bereich des Natural Language Processings oder bei sequenziellen Aufgaben zum Einsatz.
2. Group Normalization
Bei dieser Methode werden die Aktivierungen in verschiedene Gruppen unterteilt und anschließend innerhalb der Gruppen normalisiert. Daher eignet sie sich besonders gut für die Bildverarbeitung, da dort oft nur kleine Batch-Größen möglich sind, da die Bilddateien oftmals viel Speicherplatz benötigen. Die Group Normalization eröffnet eine Balance zwischen der Abhängigkeit von der Batch-Größe und der Flexibilität bei der Handhabung von verschiedenen Datenmengen.
3. Batch Renormalization
Diese Vorgehensweise ist eine Erweiterung der Batch Normalization, welche entwickelt wurde, um besser mit kleinen Batch-Größen umgehen zu können. Dabei werden zusätzliche Parameter eingeführt, die die Schätzung des Mittelwerts und der Varianz festigen, selbst wenn die Batch-Statistiken instabil sind. Dadurch kann auch bei kleinen Batch-Größen ein stabiles Training mit einer schnellen Konvergenz ermöglicht werden.
Diese Varianten ermöglichen einen Einsatz der Batch Normalization in unterschiedlichen Anwendungsszenarien, sodass auch bei anspruchsvollen Modellen die Nachteile überwunden werden können und ein stabiles Training durchlaufen werden kann.
Das solltest Du mitnehmen
- Die Batch Normalization wird in tiefen, neuronalen Netzwerken genutzt, um den sogenannten Internal Covariance Shift zu umgehen. Dieser bezeichnet das Phänomen, dass das Training langsamer stattfindet, da sich die Verteilung der Daten nach jeder Aktivierung verändert.
- Die Batch Normalization umgeht dies indem es den Datensatz in Batches aufteilt und diese nach jeder Aktivierung wieder normalisiert, sodass ein Mittelwert von 0 und eine Standardabweichung von 1 erreicht wird.
- In Python kann die Bibliothek TensorFlow verwendet werden, um diese Methode in ein bestehendes Netzwerk mit einzubauen. Dabei sollte getestet werden, ob man es vor oder nach einer Schicht hinzufügt.
- Für die Nutzung in Recurrent Neural Networks oder bei kleineren Batches haben sich über die Jahre verschiedene Varianten der Batch Normalization gebildet, die die Nachteile der herkömmlichen Methode ausgleichen.

Was ist eine Boltzmann Maschine?
Die Leistungsfähigkeit von Boltzmann Maschinen freisetzen: Von der Theorie zu Anwendungen im Deep Learning und deren Rolle in der KI.

Was ist die Gini-Unreinheit?
Erforschen Sie die Gini-Unreinheit: Eine wichtige Metrik für die Gestaltung von Entscheidungsbäumen beim maschinellen Lernen.

Was ist die Hesse Matrix?
Erforschen Sie die Hesse Matrix: Ihre Mathematik, Anwendungen in der Optimierung und maschinellen Lernen.

Was ist Early Stopping?
Beherrschen Sie die Kunst des Early Stoppings: Verhindern Sie Overfitting, sparen Sie Ressourcen und optimieren Sie Ihre ML-Modelle.

Was sind Gepulste Neuronale Netze?
Tauchen Sie ein in die Zukunft der KI mit Gepulste Neuronale Netze, die Präzision, Energieeffizienz und bioinspiriertes Lernen neu denken.

Was ist RMSprop?
Meistern Sie die RMSprop-Optimierung für neuronale Netze. Erforschen Sie RMSprop, Mathematik, Anwendungen und Hyperparameter.
Andere Beiträge zum Thema Batch Normalization
- Die Keras Dokumentation zur Batch Normalization Layer findest Du hier.
- Der Artikel von Machine Learning Mystery zum Thema Batch Normalization ist auch sehr lesenswert und wurde als Quelle für diesen Beitrag genutzt.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.