Integrated Gradients make it possible to examine the inputs of a deep learning model on their importance for the output. A major criticism of deep neural networks is their lack of interpretability, as we know it from linear regression, for example. There, we can use the weights to tell relatively accurately how much an independent variable affects the value of the prediction.
However, the hidden layers of the neural network greatly blur this relationship between input and output, since there is no direct link between the first and last layer. In a model with a hundred neurons, it is already impractical to follow the path of a data set through the network to be able to interpret how the model works and which features are of interest.
How does Integrated Gradient work?
Integrated Gradients were first introduced and tested in 2017 in the paper Axiomatic Attribution for Deep Networks. In this paper, an attempt is made to assign an attribution value to each input feature. This tells how much the input contributed to the final prediction. This approach can be used for classification models, for example in Natural Language Processing (NLP) or image labeling. We will restrict ourselves in this article to sentiment analysis in the field of NLP since our following code example is based on it. For the classification of images, the algorithm works in a slightly modified form. Our example is mostly taken from here.
For example, we want to use a sentence or sequence to decide whether it is positive or negative. The Integrated Gradients method starts with the so-called baseline, i.e. a starting point that does not contain any information for the model prediction. In our case, this is the set exclusively with the start and end tokens. These only mark the beginning and the end of a sentence or section and do not give any information about whether the evaluation is positive or negative.
We define a certain number of steps that determines how many steps we get from the baseline to the actual input of the model. According to the original paper, the number of steps should be between 20 and 300. Figuratively and highly simplified, you can think of it as if we were assembling the sentencing piece by piece and adding the next token of the baseline in each step.
In each of these steps, we would then have the model calculate a prediction. This gives us an attribution value for each input feature, which tells us how much the feature influenced the overall result. For example, if we add the token for the word “good” to the baseline, we will likely see an increase in the prediction because the model’s output value of 1 represents a positive sentiment. We can explicitly calculate the attribution value for the token “good” by calculating the gradient of the model with respect to the input feature “good”.
Why does the Integrated Gradients Method work?
When we try to identify such influencing factors, we face the problem that we cannot judge in retrospect whether an incorrect attribution value is due to an error in the model or in the attribution method. Therefore, two basic principles are mentioned in the literature that an attribution method has to fulfill in order to reliably deliver good results. In the paper Axiomatic Attribution for Deep Networks, the authors are able to show that Integrated Gradients satisfy both of the following principles and thus represent a good attribution method:
- Sensitivity: If an input feature changes the classification score in any way, this input should have an attribution value not equal to 0.
- Implementation invariance: The result of the attribution should not depend on the design and structure of the neural network. Thus, if two different neural networks provide the same prediction for the same inputs, their attribution values should also be identical.
What can Integrated Gradients be used for?
As the name suggests, the concept can only be used for more sophisticated models, i.e. those that optimize a loss function using the gradient method. This includes all types of neural networks, as well as some other models. Only basic models in the field of Machine Learning, such as Random Forest or Linear Regression, cannot be used.
Thus, the Integrated Gradient method can be used in a wide variety of areas, such as Natural Language Processing, image processing, or other predictive models. Additionally, different goals can be pursued:
- It can be found out how important individual input parameters are for the final result. This allows, for example, to remove unimportant inputs from the data set and saving memory and computing power in preprocessing.
- Once the important features have been identified, it is also possible to ensure that their quality in the data set is sufficiently good, thus increasing the quality of the overall model. This includes, for example, that the important features do not have too many empty cells and that their distribution is also balanced.
- Finally, the performance of the model can be improved or debugging can take place. In the case of wrong predictions, it can be found out how it came to this wrong connection, and/or which input feature was responsible for the wrong conclusion.
What is the Alibi Library?
Before we can start with the example of the Integrated Gradients method, we should take a closer look at the Python library used. For our code, we are using the Alibi library, which has an Integrated Gradients function.
This is an open-source library that was created specifically for the interpretation of machine learning models and therefore also contains the desired functionality. It can be easily installed via pip and has dependencies on all major Machine Learning libraries, such as TensorFlow or Scikit-Learn.
Integrated Gradients using the Example of a Sentiment Analysis
Since this article is mainly about the explanation of integrated gradients, we use a pre-trained BERT model for our sentiment analysis and do not train it additionally. We will save that for a separate article.
For our example, we load the Distilbert model in English. The model has been trained on the Stanford Sentiment Treebank (SST) dataset for sentiment analysis. When we use this kind of model, we cannot use plain text as input but have to split it into so-called tokens and represent them again as numbers. Therefore we need the functions “process_reviews” and “process_sentences”.
In order to be able to use the loaded model ourselves, we define a wrapper with the help of which we can make sentiment predictions.
Now we can finally turn our attention to the Integrated Gradients and their calculation. For this purpose, we define the example sentence “I love you, but I also kind of dislike you”, which may sound a bit strange, but will later show well which words rather indicate positive sentiment and which ones a negative sentiment. Of course, we have to tokenize this sentence before we can make a prediction with the model.
For the Integrated Gradients, we only need the Embedding Layer, i.e. the Transformer Block.

Now we can define the algorithm and its hyperparameters. Besides the number of steps, we can also define the method and assign a batch size.
Now comes the actually exciting part of this article. We first let our original classification model classify the complete sentence. Then, we apply the Integrated Gradients method to this result. We do not define an explicit baseline but use the default value instead.
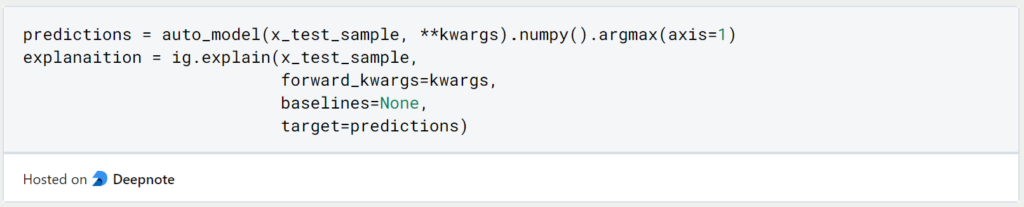
From this model, we can easily extract the attribution values. We add the values in each step together so that we then have one value left for each of the 20 steps.

We now define two functions to show us the result of the Integrated Gradient method also graphically and to be able to see for each word with green and red colors how contributed to the sentiment.
To get a result as plain text we have to translate the tokens back into words. We can additionally use the function “colorize” to assign the corresponding color tones to the attribution values.

The sentiment of our sentence classifies the pre-trained model as positive.

The words highlighted in green now show us which words led the model to positive sentiment and the red words, on the other hand, contributed to negative sentiment.


We see that the word “love” had by far the greatest impact on the positive sentiment of the whole sentence. “Dislike,” on the other hand, spoke to a negative sentiment of the sentence, but was not strong enough to balance out “love.” Surely you can’t end this technical paper with a more philosophical sentence.
This is what you should take with you
- The Integrated Gradients method is a way to make a classification model interpretable.
- It can be used for all models that are differentiable, i.e. derivable. This includes, for example, neural networks, but not the basic machine learning models, such as Random Forest or Linear Regression.
- Applications of the Integrated Gradient method include, for example, finding out the feature importance, debugging models, as well as improving the data set with respect to the important features.
- A baseline is defined that has no effect on the classification result. Then, in a few steps, interpolations are given to the model, and the gradient is used to determine what influence the individual inputs have on the result.
Thanks to Deepnote for sponsoring this article! Deepnote offers me the possibility to embed Python code easily and quickly on this website and also to host the related notebooks in the cloud.

What is Grid Search?
Optimize your machine learning models with Grid Search. Explore hyperparameter tuning using Python with the Iris dataset.

What is the Learning Rate?
Unlock the Power of Learning Rates in Machine Learning: Dive into Strategies, Optimization, and Fine-Tuning for Better Models.

What is Random Search?
Optimize Machine Learning Models: Learn how Random Search fine-tunes hyperparameters effectively.

What is the Lasso Regression?
Explore Lasso regression: a powerful tool for predictive modeling and feature selection in data science. Learn its applications and benefits.

What is the Omitted Variable Bias?
Understanding Omitted Variable Bias: Causes, Consequences, and Prevention in Research." Learn how to avoid this common pitfall.

What is the Adam Optimizer?
Unlock the Potential of Adam Optimizer: Get to know the basucs, the algorithm and how to implement it in Python.
Other Articles on the Topic of Integrated Gradients
- Here you can find the paper “Axiomatic Attribution for Deep Networks”.
- Please find the example in a slightly modified way here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.