Autoencoder sind eine spezielle Form von tiefen, neuronalen Netzwerken, die vor allem zur Feature-Extraktion oder zur Dimensionsreduktion verwendet werden. Da sie mit ungelabelten Daten arbeiten können, zählen sie zum Bereich des Unsupervised Learnings. Die Architektur besteht aus zwei Hauptkomponenten: dem Encoder, welcher die Eingabedaten in eine niedrigdimensionale Darstellung komprimiert, und dem Decoder, der darauf trainiert wird, die Ursprungsdaten wieder aus dieser Repräsentation zu konstruieren.
Dieser Artikel bietet eine detaillierte Übersicht über den Aufbau von Autoencoder und erklärt die einzelnen Komponenten der Architektur. Außerdem beschäftigen wir uns mit den Herausforderungen, die beim Training entstehen können, und den Anwendungen, die auf dieses Modell bauen. Abschließend sehen wir uns die Vor- und Nachteile der Methode genauer an und vergleichen sie mit anderen Algorithmen zur Dimensionsreduktion.
Was ist ein Autoencoder?
Ein Autoencoder ist eine spezielle Form eines künstlichen neuronalen Netzwerks, welches darauf trainiert wird, die Eingabedaten in einer komprimierten Form darzustellen und anschließend die Originaldaten aus dieser komprimierten Form wieder zu rekonstruieren. Was anfangs nach einer unnötigen Transformation klingt, ist ein fester Bestandteil in der Dimensionsreduktion, da dadurch irrelevante Details oder Rauschen aus dem Datensatz entfernt werden können. Die Reduzierung des Datensatzes passiert im sogenannten Encoder, während die zweite Komponente, der Decoder, wieder die Ursprungsdaten rekonstruiert.
Da Autoencoder selbstständig die Muster und Strukturen in den Eingabedaten erlernen, zählen sie zum Bereich des Unsupervised Learnings, da keine Labels im Datensatz benötigt werden. Dadurch können sie in einer Vielzahl von Anwendungen genutzt werden, auch wenn keine gelabelten Daten vorhanden sind. Diese Eigenschaft macht sie zu einem vielseitigen Tool im Deep Learning.
Wie ist ein Autoencoder aufgebaut?
Ein Autoencoder ist ein spezielles neuronales Netzwerk, welches zum Ziel hat, die Eingabedaten möglichst weit zu komprimieren und anschließend aus dieser Kompression die Ursprungsdaten möglichst genau wiederherzustellen. Diese Aufgaben werden von den zwei Hauptkomponenten, dem Encoder und dem Decoder, bewältigt, welche in diesem Kapitel genauer beschrieben werden.
Encoder: Datenkompression und Merkmalsextraktion:
Der Encoder ist der erste Teil der Autoencoder Architektur in dem die Daten von Schicht zu Schicht weiter komprimiert werden bis sie schließlich im sogenannten Bottleneck oder Latent Space landen. Dazu durchlaufen die Daten verschiedene neuronale Schichten, wobei jede dieser Schichten schrittweise weniger Output-Parameter besitzt, wodurch das Modell die wichtigsten Merkmale aus den Daten extrahieren muss.
Folgende Merkmale zeichnen den Encoder aus:
- Datenreduktion: Der Encoder ist darauf ausgelegt, irrelevante Informationen aus dem Datensatz zu entfernen und ausschließlich die wichtigsten Merkmale beizubehalten. Dazu werden die hochdimensionalen Daten schrittweise in einen niedrigdimensionalen Raum überführt und während des Trainings wird der Encoder immer besser darin, die wichtigsten Informationen zu behalten.
- Nichtlineare Transformationen: Um auch komplexe Strukturen in den Daten erkennen zu können, werden verschiedene nichtlineare Aktivierungsfunktionen, wie zum Beispiel ReLu (Rectified Linear Unit) oder sigmoid, eingesetzt. Diese ermöglichen es, dass auch komplexere Zusammenhänge erkannt und abgebildet werden können.
- Bottleneck-Struktur: Am Ende des Encoders steht das sogenannte Bottleneck, welches den Punkt im Modell repräsentiert, an dem die Daten am weitesten komprimiert wurden und damit in der niedrigsten Dimension vorliegen. In dieser Schicht steht nur ein kleiner Speicherplatz zur Verfügung, wodurch das Modell gezwungen ist, die Daten möglichst stark zu komprimieren.
Der Encoder ist also der erste Teil eines Autoencoders, in dem die Informationen aus dem Datensatz immer stärker komprimiert werden und die Anzahl der Dimension verringert wird.
Latent Space / Bottleneck
Nach den Encoder Strukturen folgt der sogenannte Latent Space oder auch als Bottleneck bezeichnet, welcher eine zentrale Komponente des Autoencoders ist. In diesem Zustand haben die Daten eine möglichst niedrigdimensionale Darstellung und besitzen trotzdem noch möglichst viel Informationsgehalt, welcher es dem anschließenden Decoder ermöglichen soll, die Eingabedaten wiederherzustellen.
Decoder: Wiederherstellung der Daten aus dem Latent Space
Der Decoder ist das Gegenstück zum Encoder und erzeugt aus der komprimierten Repräsentation im Latent Space wieder Daten in der ursprünglichen Form. Der Decoder besteht ebenfalls aus mehreren Schichten und erhöht dabei schrittweise die Dimensionen wieder, bis der hochdimensionale Raum der Anfangsdaten wieder erreicht ist. Dabei sind folgende Merkmale entscheidend:
- Entfaltung der Daten: Der Decoder funktioniert genau umgekehrt wie der Encoder und anstatt Daten zu komprimieren, entfaltet er die Daten. Jede neuronale Schicht im Decoder fügt dabei wieder Dimensionen dem Datensatz hinzu, solange bis die ursprüngliche Datenform wieder erreicht ist.
- Rekonstruktion der Daten: Das Ziel des Decoders ist es die Ausgangsform des Datensatzes wiederherzustellen und dabei den ursprünglichen Daten so nahe wie möglich zu kommen und die wichtigen Merkmale abzubilden.
- Ausgabeschicht: In der Ausgabeschicht geht es darum, die Vorhersagen wieder in der ursprünglichen Form auszugeben. Abhängig von der Anwendung gibt es dafür gewisse Vorgaben, die eingehalten werden müssen. Bei der Verarbeitung von Bildern beispielsweise müssen die Pixelwerte, aus denen sich das Bild zusammensetzt in einem gewissen Bereich liegen. Dafür können spezielle Aktivierungsfunktionen genutzt werden, welche diese Anforderungen sicherstellen.
Ein guter Decoder zeichnet sich dadurch aus, dass er aus den wesentlichen Informationen der komprimierten Darstellung wieder Daten in der ursprünglichen Form erzeugen kann, welche den Elementen aus dem Datensatz möglichst nahekommen.
Das Ziel des Autoencoders besteht darin, die Parameter dieser Komponenten so anzupassen, dass der sogenannte Rekonstruktionsfehler minimal ist. Das bedeutet, dass der Unterschied zwischen den Eingabe- und den Ausgabedaten so gering wie möglich ist. Im Fall der Bildverarbeitung sollte das originale Bild, welches dem Autoencoder zugeführt wird, möglichst detailgetreu wieder am Ende des Autoencoders erzeugt werden. Damit sich das Modell weiter verbessern kann, durchläuft es ein iteratives Training, welches wir uns im nächsten Abschnitt genauer anschauen.
Wie lernt der Autoencoder?
Im Training wird der Autoencoder dahingehend optimiert, die Eingabedaten, wie zum Beispiel ein Bild, möglichst genau wieder zu rekonstruieren. Das schwierige ist dabei, dass dem Decoder dafür nicht das ursprüngliche Bild zur Verfügung steht, sondern lediglich die stark komprimierte Version der Daten im Latent Space, welche vom Encoder erzeugt wurden. Deshalb hat das Training zwei Ziele:
- Der Encoder muss eine möglichst gute Repräsentation der Daten erlernen, welche zwar aus nur wenigen Dimensionen besteht, aber trotzdem die wichtigsten Merkmale der Daten enthält.
- Der Decoder muss besser darin werden, aus dieser niedrigdimensionalen Datendarstellung eine hochdimensionale Form zu bauen, die sich wenig oder am besten gar nicht von den Eingabedaten unterscheidet.
Das Training umfasst mehrere Schritte, welche für ein optimales Ergebnis essenziell sind.
Datenvorbereitung
Der Autoencoder benötigt zwar keine Labels im Datensatz, jedoch bietet es sich trotzdem an, den Datensatz vor dem Training aufzubereiten, um es dem Modell einfacher zu machen und eine schnellere Konvergenz zu erreichen. Dazu werden die Daten normalisiert oder skaliert, was zur Folge hat, dass die Ausprägungen der Daten alle auf einer Skala liegen.
Forward Pass
Während dem Vorwärtsdurchlauf werden die Daten von vorne durch das Modell geleitet, also zuerst durch den Encoder. Dieser errechnet daraus eine niedrigdimensionale Repräsentation, den Latent Space, welche dann im Decoder wieder in höhere Dimensionen geführt wird und dabei die ursprünglichen Daten so genau wie möglich nachbildet.
Dabei findet der Autoencoder also Wege, wie er die Eingabedaten möglichst gut komprimieren kann und aus diesen komprimierten Daten wieder die Datenpunkte mit der ursprünglichen Dimensionalität herzustellen. Um dabei jedoch auch den Eingabedaten möglichst nahe zu kommen, bedarf es einer Metrik, die misst, wie gut der Autoencoder dies tut.
Berechnung der Verlustfunktion
Damit der Autoencoder beurteilen kann, ob er sich in die richtige Richtung entwickelt, nutzt er die sogenannte Verlustfunktion, um einen Rekonstruktionsfehler zu berechnen. Dieser trifft eine Aussage darüber, wie stark sich die vom Autoencoder erstellten Daten von den ursprünglichen Daten unterscheiden. Im besten Fall ist dieser Unterschied möglichst gering und die vorhergesagten Daten unterscheiden sich nur minimal von den Daten im Datensatz.
Als Verlustfunktion oder Rekonstruktionsfehler kann beispielsweise der Mean Squared Error genutzt werden, welcher die durchschnittliche, quadrierte Abweichung aller Trainingsbeispiele berechnet:
\(\)\[MSE=\frac{1}{n}\sum_{i=1}^{n}\left(x_i-\hat{x_i}\right)^2 \]
Hierbei ist \(x_{i}\) der tatsächliche Wert im Datensatz und \(\hat{x_i}\) der vom Modell vorhergesagte Werte. Das Ziel des Trainingsprozesses ist es, diese Funktion in jeder Iteration weiter zu minimieren.
Backward Pass & Optimierung
Nachdem der Fehler für eine Iteration berechnet wurde, kann er genutzt werden, um mithilfe der Backpropagation rückwärts durch das Modell zu wandern. Dabei werden die Gewichte der einzelnen Neuronen so angepasst, dass der Fehler beim nächsten Durchlauf geringer ausfällt. Dafür werden in jeder neuronalen Schicht Berechnungen durchgeführt, die die Änderungsrate des Gewichts als Ergebnis haben. Jedoch wird nicht die volle Änderung verwendet, sondern es kommt die sogenannte Lernrate als Hyperparameter zum Einsatz, die darüber bestimmt, wie stark die ausgerechnete Änderung wirklich ist. Eine zu hohe Lernrate kann zu einem instabilen und sehr sprunghaften Modell führen, während eine niedrige Lernrate dazu führt, dass sich das Modell nur langsam verbessert.
Autoencoder nutzen meist den Gradientenabstieg als Optimierungsalgorithmus, bei welchem die entgegengesetzte Richtung der Ableitung über die Veränderung der Gewichte bestimmt. Darüber hinaus kann auch der sogenannte Adam Optimizer verwendet werden, welche eine Sonderform des Gradientenabstiegs darstellt.
Iteratives Lernen
Diese beschriebenen Abläufe mit Forward Pass und Backward Pass werden nun ständig wiederholt und es werden mehrere sogenannte Epochen durchlaufen. Eine Epoche umfasst so viele Iterationen, dass jeder Datenpunkt im Trainingsdatensatz einmal im Training genutzt wurde. In einem Training werden mehrere dieser Epochen durchlaufen, wobei sich der Rekonstruktionsfehler kontinuierlich verkleinern sollte. Dieser Prozess wird dann so lange wiederholt bis entweder der Fehler des Autoencoders minimal ist, eine Maximalzahl an Iterationen erreicht ist oder keine signifikanten Verbesserungen mehr beobachtet werden können.
Hyperparameter Tuning
Nach einem vollständigen Trainingsdurchlauf ist der Lernprozess des Autoencoders noch nicht final abgeschlossen. Wenn man mit den Ergebnissen noch nicht zufrieden ist oder man testen möchte, ob sich diese noch weiter verbessern lassen, nutzt man das sogenannte Hyperparameter Tuning.
Hyperparameter sind gewisse Eigenschaften in der Modellarchitektur, welche während des Trainings nicht eigenständig verändern können, sondern von außen gesetzt werden. Dazu zählen beispielsweise die Lernrate, die Anzahl der Schichten im Decoder und Encoder oder die Anzahl der Dimensionen im Latent Space. Während des Hyperparameter Tunings versucht man die optimalen Einstellungen für diese Hyperparameter zu finden, indem man gewisse Tests durchführt und unterschiedliche Trainingsdurchläufe mit verschiedenen Hyperparameterwerten ausprobiert.
Das Training eines Autoencoders ist ein umfassender Prozess, welcher es zum Ziel hat, den Rekonstruktionsfehler so weit wie möglich zu minimieren. Indem die genannten Schritte durchlaufen werden, kann ein aussagekräftiges und robustes Modell trainiert werden.
Welche Arten von Autoencodern gibt es?
Über die Zeit haben sich verschiedene Arten von Autoencodern entwickelt, welche für bestimmte Datentypen oder Anwendungsfälle spezialisiert wurden. Jede dieser Modellvarianten hat ihre eigenen Eigenschaften und Vorteile, welche wir in diesem Abschnitt genauer beschreiben wollen.
Basis-Autoencoder
Der Basis-Autoencoder ist die einfachste Form eines Autoencoders und zeichnet sich durch die symmetrische Form aus. Dabei reduziert der Encoder die Daten auf eine niedrigdimensionale Repräsentation und der Decoder versucht aus dieser Repräsentation wieder die ursprünglichen Daten zu konstruieren.
- Aufbau: Sowohl Encoder als auch Decoder bestehen aus neuronalen Netzwerkschichten, die komplett miteinander verbunden sind, sodass jedes Neuron in einer Schicht mit allen Neuronen der nachfolgenden Schicht verbunden ist. Der Aufbau ähnelt einem Flaschenhals, wobei der schmalste Punkt den sogenannten Latent Space darstellt.
- Anwendung: Der Basis-Autoencoder wird vor allem für einfache Aufgaben bei der Dimensionsreduktion oder der Feature Extraction eingesetzt.
- Vorteil: Durch die einfache Struktur können diese Modelle schnell trainiert werden und sie sind leicht verständlich.
Denoising Autoencoder
Die Denoising Autoencoder wurden dazu entwickelt, das Rauschen in Daten, also Fehler und Verunreinigungen, auszubessern. Dadurch können die Eingabedaten gereinigt oder gefiltert werden. Während dem Training wird dazu absichtlich Rauschen in die Eingabedaten gemischt und das Modell muss trotzdem versuchen die ursprünglichen Eingabedaten ohne Rauschen zu erzeugen.
- Funktionsweise: Der Aufbau des Denoising Autoencoders ist ähnlich zu einem Basis-Autoencoder mit dem Unterschied, dass er verunreinigte Daten erhält. Der Encoder versucht nun im Training trotz des Rauschens eine komprimierte Darstellung zu erzeugen mit deren Hilfe der Decoder die Eingabedaten ohne Rauschen erzeugen kann.
- Anwendung: Diese Modelle werden vor allem in der Bildbearbeitung eingesetzt, um unscharfe oder verrauschte Bilder zu bereinigen und deren Qualität dadurch zu verbessern. Außerdem können Denoising Autoencoder verwendet werden, um in der Signalverarbeitung Nebengeräusche zu unterdrücken.
Variational Autoencoder (VAE)
Die Variational Autoencoder sind eine Weiterentwicklung des Basis-Autoencoders, in welchen der Latent Space keine feste Repräsentation der Daten erlernt, sondern vielmehr eine Wahrscheinlichkeitsverteilung erzeugt.
- Latent Space: Der Latent Space bei einem Variational Autoencoder wird als eine Wahrscheinlichkeitsverteilung, in den meisten Fällen eine Normalverteilung, modelliert. Dadurch ist das Modell in der Lage, glattere und weichere Übergänge zu erzeugen.
- Anwendung: VAEs werden vor allem im Bereich der generativen KI eingesetzt, um beispielsweise Bilder oder Audio-Dateien zu erzeugen, welche möglichst realistisch erscheinen sollen.
- Vorteil: Durch die probabilistische Natur von VAEs eignen sich diese Modelle vor allem für Anwendungen, in denen es auf eine statistische Repräsentation der Daten ankommt, wie beispielsweise bei der Anomalieerkennung.
Convolutional Autoencoder
Die Convolutional Autoencoder umfassen speziell angepasste Modelle für die Bildverarbeitung. Dabei werden die Schichten aus Convolutional Neural Networks verwendet, um die Eingabedaten effizienter als mit einem Dense Neural Network zu verarbeiten und dabei die relevanten Bildmerkmale extrahieren zu können.
- Aufbau: Im Encoder werden klassische Convolutional Layer verwendet, welche die wichtigen Bildeigenschaften und deren Lage erlernen können. Der Decoder hingegen verwendet entsprechend Up-Sampling-Schichten, die auch als Transposed Convolutions bezeichnet werden, um das Bild wiederherzustellen.
- Anwendung: CAEs werden in vielen Anwendungen rund um die Bildverarbeitung genutzt, wie zum Beispiel bei der Bildkompression, dem Bilddenoising oder für komplexe Bildgenerierungen.
- Vorteil: Im Vergleich zu klassischen Autoencodern, kann mithilfe der Faltungsschichten besser auf die Besonderheiten in der Bildverarbeitung eingegangen werden.
Diese Varianten sind nur einige von vielen spezialisierten Autoencodern, welche für unterschiedlichste Anwendungen angepasst wurden. Es ist wichtig die Unterschiede und deren Vorteile zu kennen, um die richtige Wahl zu treffen und dadurch noch bessere Ergebnisse für den jeweiligen Datensatz zu erzielen.
Welche Herausforderungen gibt es im Training von Autoencodern?
Autoencoder sind ein mächtiges Tool in der Dimensionsreduktion und der Feature Extraction, welche auch komplexe Zusammenhänge in den Datenstruktur erkennen und abbilden können. Jedoch hat diese Komplexität auch ihre Tücken, da es schnell zu Overfitting kommen kann und die Rekonstruktionsqualität bei neuen Daten nicht gut genug ist. Um die maximale Leistung aus Autoencodern rausholen zu können, sollte man die Punkte beachten, welche in diesem Abschnitt genauer erläutert werden.
Flache vs. Tiefe Autoencoder
Abhängig von der Anzahl der Schichten im Encoder und Decoder unterscheidet man flachere und tiefere Architekturen. Die Komplexität hängt dabei stark von den Daten und der Zielsetzung ab.
- Flache Autoencoder: In diese Architektur werden weniger Schichten in Encoder und Decoder genutzt, wodurch das Modell zwar nur weniger komplexe Zusammenhänge erfassen kann, dafür aber auch weniger Rechenleistung benötigt und das Training möglicherweise schneller beendet. Bei weniger komplexen Aufgaben und Datensätzen sind flache Autoencoder besonders nützlich, da sie die relevanten Merkmale extrahieren können und aufgrund der geringeren Zahl von Parametern auch eine kleinere Wahrscheinlichkeit des Overfittings besitzt.
- Tiefe Autoencoder: Bei einer tiefen Autoencoderarchitektur besitzen Encoder und Decoder mehr Schichten und können dadurch komplexere Zusammenhänge erlernen, die zum Beispiel bei hochkomplexen Daten, wie Bildern, oder bei schwierigeren Aufgaben, wie der Feature Extraction, auftauchen. Jedoch muss hierbei beachtet werden, dass das Risiko für Overfitting steigt und deshalb Regularisierungstechniken nötig werden können.
Die Entscheidung für die richtige Architektur des Autoencoders hat einen entscheidenden Einfluss auf die Qualität der Vorhersagen und die Dauer des Trainings. Abhängig von den Daten und den gewünschten Vorhersagen sollten genug Schichten genutzt werden, um die Komplexität abzubilden und trotzdem nur so wenige, dass es nicht zu Overfitting kommt.
Rekonstruktionsqualität
Das Hauptziel des Autoencoders ist es, möglichst detailgetreue Nachbildungen der Eingabedaten bilden zu können und damit den Rekonstruktionsfehler so gering wie möglich zu halten. Diese Fähigkeit hängt von verschiedenen Faktoren ab, die beachtet werden sollten:
- Größe des Latent Space: Im Latent Space wird die komprimierte Darstellung der Eingabedaten abgelegt. Die Dimensionalität sollte möglichst so gewählt werden, dass der Decoder noch genügend Informationen enthält, um die Eingabedaten rekonstruieren zu können und der Latent Space trotzdem klein genug ist, dass es auch wirklich zu einer Dimensionsreduktion gekommen ist. Somit muss eine Wahl getroffen werden, welche die Extreme zwischen Kompression und Informationsgehalt ausgleicht.
- Architektur des Decoders: In der Praxis neigt man häufig dazu, die Wichtigkeit des Decoders zu unterschätzen und sich primär auf den Encoder und den Latent Space zu konzentrieren. Es sollte jedoch darauf geachtet werden, dass der Decoder gut aufgebaut wird, um eine detailgetreue Rekonstruktion aus den komprimierten Daten erstellen zu können.
- Aktivierungs- und Verlustfunktion: Die Rekonstruktion hängt zu einem großen Teil von der richtigen Wahl dieser beiden Funktionen ab. Sie entscheiden darüber, ob das Modell nur lineare oder auch nicht-lineare Zusammenhänge erlernen können und wie gut der Trainingsprozess ablaufen kann.
Der Autoencoder ist ein komplexes Machine Learning Modell, welches sehr komplexe Zusammenhänge erfassen kann, wenn es richtig eingestellt ist. Deshalb muss man besonderen Wert auf die Wahl der richtigen Architektur legen, um das Maximale aus den Modellen herauszuholen.
Wie kann ein Autoencoder in Python mit TensorFlow erstellt werden?
In Python lassen sich Autoencoder Modelle ganz einfach mit Keras, was ein Teil von TensorFlow, ist. In diesem Beispiel nutzen wir den MNIST-Datensatz, welcher Bilder von handgeschriebenen Ziffern enthält. Dazu werden wir einen Encoder und Decoder mit verschiedenen Schichten definieren und anschließend das Modell trainieren. Abschließend testen wir die Leistung des Modells, indem wir einige Trainingsbilder und deren Vorhersage vergleichen.
Um den Autoencoder bauen zu können, benötigen wir einige Bibliotheken und Funktionalitäten. Mithilfe von NumPy können wir den Datensatz so vorbereiten, dass ihn das Modell später verwenden kann. Matplotlib werden wir am Ende des Beispiels verwenden, um die Originalbilder und die rekonstruierten Bilder auszugeben.
Mithilfe von TensorFlow wird das schlussendliche Modell gebaut, wobei darin das Modul Keras verwendet wird. Zuallererst importieren wir dafür den Datensatz mnist, welchen wir verwenden wollen. Außerdem importieren wir die Funktionalität Model, um den Autoencoder bauen zu können, und mithilfe der Schichten Input und Dense, können wir später das Modell Stück für Stück aufbauen.

Den MNIST-Datensatz können wir mithilfe der Funktion load_data() laden und direkt in Trainings-und Testdatensatz aufteilen. Damit das Modell sich auf die Eigenheiten der Daten konzentrieren kann, normalisieren wir die Daten auf den Bereich von 0 bis 1. Jeder Pixel im Bild kann einen Zahlenwert von 0 bis 255 annehmen. Mithilfe der Division durch 255 normalisieren wir die Werte. Das bietet sich auch deshalb an, weil wir das Modell so bauen werden, dass für jeden Pixel ein Wert zwischen 0 und 1 vorhergesagt wird, sodass die Eingabe- und Ausgabedaten direkt vergleichbar sind.
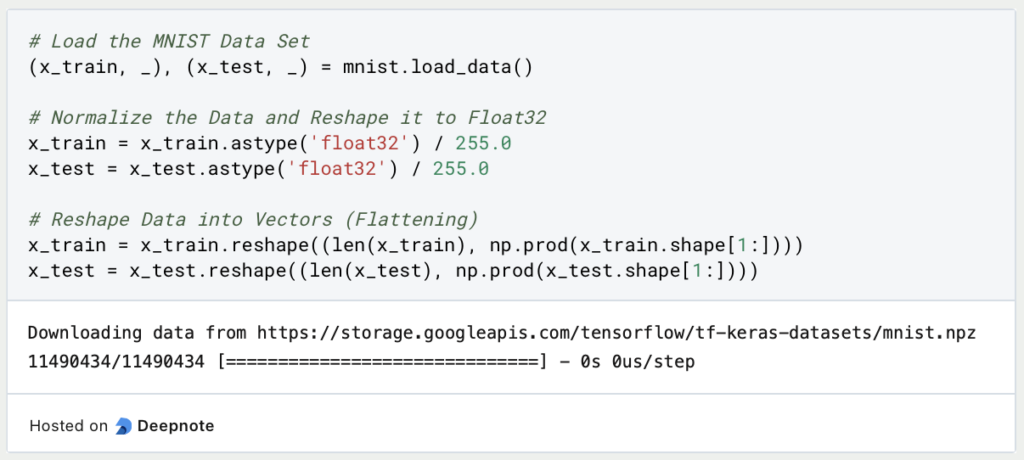
Anschließend werden die Datensätze in einem zentralen Vektor gespeichert, welcher die Länge des Datensatzes als erste Dimension hat und die Anzahl der Pixel in einem Bild als zweite Dimension. Für den MNIST-Datensatz ergibt sich für den Trainingsdatensatz, dass er aus 6.000 Bildern besteht, wobei jedes Bild 784 Pixel besitzt.
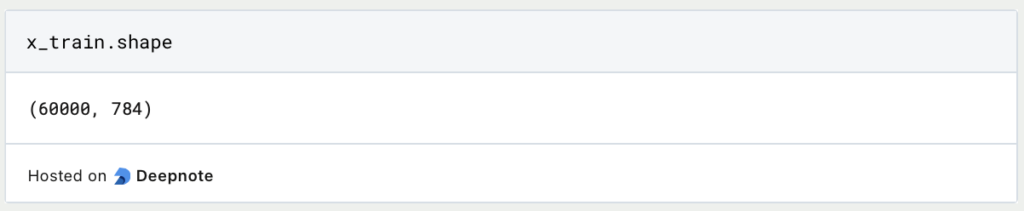
Nun folgt der spannende Teil, in dem wir das Modell aufbauen und die einzelnen Schichten definieren. Dazu legen wir fest, dass der Latent Space insgesamt nur noch 32 Dimensionen besitzen soll, anstatt 784. Dies ist ein Hyperparameter, den wir festlegen und der sich im Laufe des Trainings nicht verändert. Wenn wir nach dem ersten Trainingsdurchlauf feststellen sollten, dass er falsch gewählt ist, können wir in einem weiteren Training eine höhere oder niedrigere Dimensionalität testen.
Der Encoder besteht aus der Eingabeschicht mit 784 Eingabeneuronen, also einen für jedes Pixel im Bild. Als nächstes schließt eine Dense-Schicht an, die nur aus lediglich 128 Neuronen besteht und somit die Dimensionalität in einem ersten Schritt reduziert. Als Aktivierungsfunktion nutzen wir ReLu, da sie ein guter Startpunkt für viele Deep Learning Modelle ist. Anschließend wird wieder eine Dense-Schicht verwendet, welche dann nur noch 32 Neuronen für den Latent Space besitzt.
Der Decoder schließt an den Latent Space und erhöht die Dimensionalität wieder von 32 auf 128 Neuronen. Als letzte Schicht wird die Dimensionalität wieder auf 784 erhöht, also genau so hoch, wie die der Eingabedaten. In der letzten Schicht verwenden wir die Sigmoid-Aktivierungsfunktion, da diese die Ausgabewerte auf den Bereich zwischen 0 und 1 skaliert, sodass die Vorhersage des Modells auch mit den Eingabedaten vergleichbar ist.
Das Modell kann dann einfach definiert werden, indem die erste und die letzte Schicht des Modells als Parameter übergeben werden. Anschließend definieren wir noch die Modelle encoder und decoder, welche wir später nutzen können, um die Vorhersagen auf dem Testset berechnen und ausgeben zu können.
Mithilfe von summary() können wir die Architektur des Autoencoders veranschaulichen und sehen die einzelnen Schichten, sowie deren Dimensionalität.
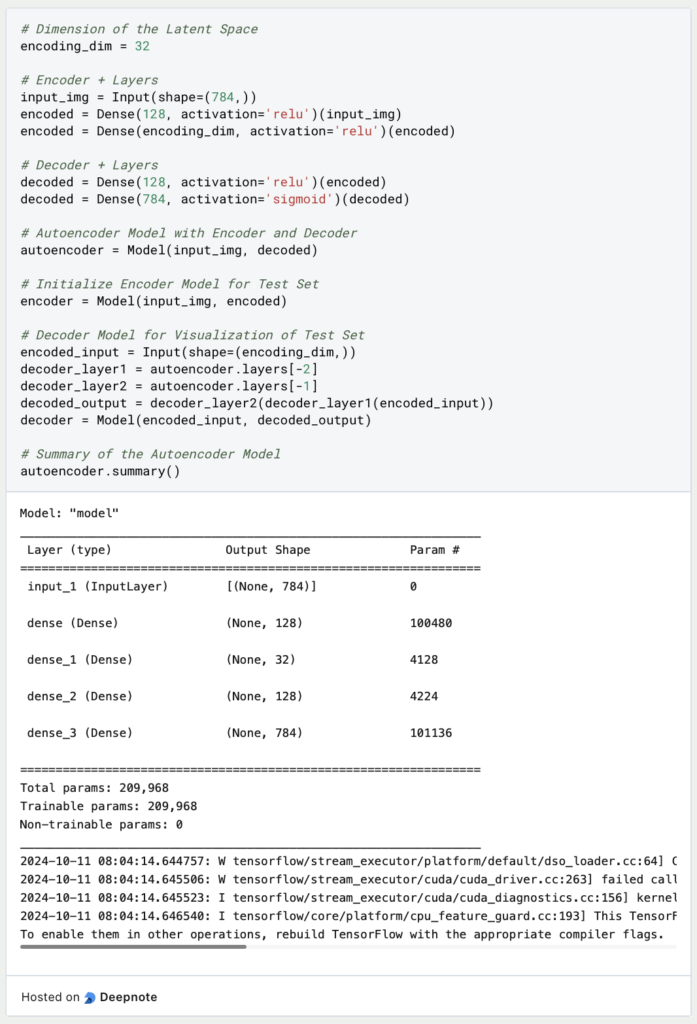
Jetzt wo das Modell und die einzelnen Schichten soweit definiert sind, fehlt nur noch die Definition der Verlustfunktion und des Optimierungsalgorithmus, damit das Modell weiß, wie es nach jeder Trainingsepoche die Gewichte der Neuronen anpassen soll. In unserem Fall nutzen wir die Binary Crossentropy, weil der Autoencoder in der letzten Schicht Werte zurückgibt, welche zwischen 0 und 1 liegen.
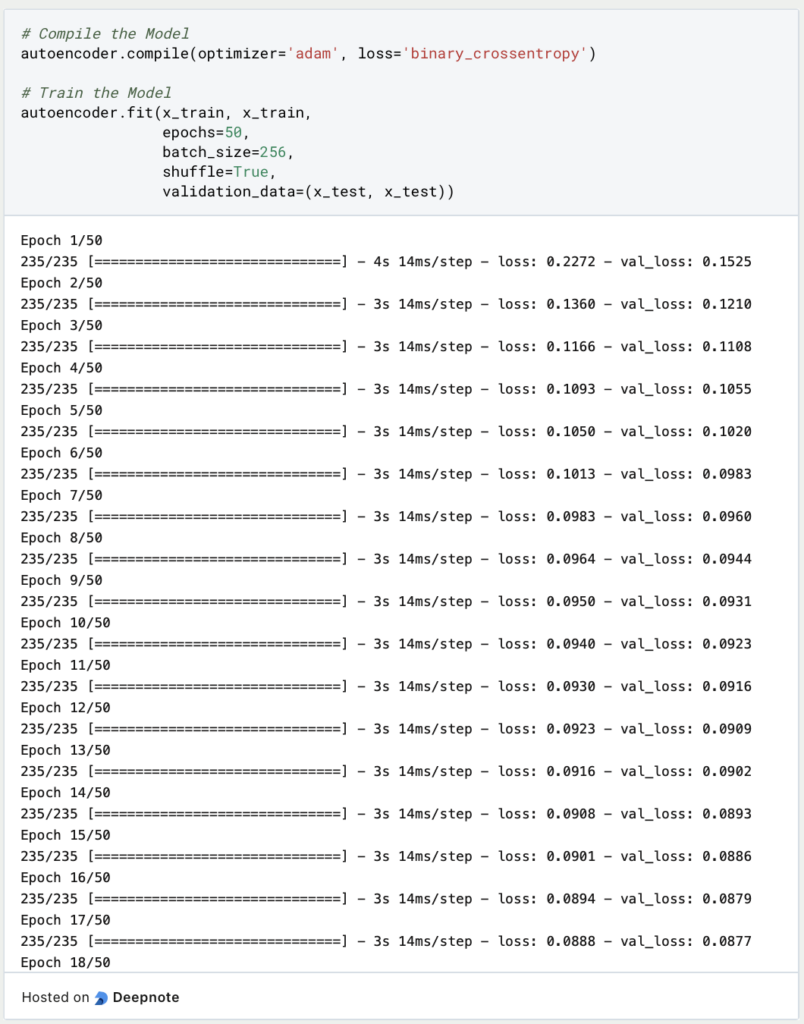
Das Modell wird dann für insgesamt 50 Epochen trainiert, es wird also der Trainingsdatensatz 50mal durchlaufen, wobei in jedem Batch 256 Bilder übergeben werden. Als Validierungsdatensatz wird nach jeder Epoche x_test verwendet, um zu prüfen, wie das Modell auf neue Daten reagiert.
Nach dem Training prüfen wir das Modell, indem wir insgsamt zehn Bilder aus dem Datensatz ausgeben und uns die rekonstruierten Bilder des Autoencoders dazu anschauen. Dazu nutzen wir die vorher definierten Modelle encoder und decoder, um die Bilder zuerst zum Latent Space hin zu komprimieren und anschließend zu rekonstruieren. Mithilfe von Matplotlib geben wir sie dann aus und sehen, dass die Rekonstruktionen bis auf kleine Details sehr nahe an den Originalbildern liegen.

Dieser einfache Autoencoder konnte bereits gute Ergebnisse auf den schwarz-weißen Bildern erzielen. Er kann nun beispielsweise dafür genutzt werden, die Bilder zu komprimieren und sie dadurch in einer speicherärmeren Version zu hinterlegen.
Wie schneiden Autoencoder im Vergleich mit anderen Dimensionsreduktionen ab?
Die Einführung von Autoencoder hat eine Methode hervorgebracht, um effektiv Daten zu komprimieren und überflüssige Merkmale aus den Daten zu entfernen. Jedoch gibt es auch andere, etablierte Methoden zur Dimensionsreduktion, die abhängig vom Anwendungsfall trotzdem besser geeignet sein können. In diesem Abschnitt wollen wir einen Überblick darüber geben, in welchen Fällen, welche Methode am besten geeignet sein kann.
PCA vs. Autoencoder
Die Principal Compoenent Analysis (deutsch: Hauptkomponentenanalyse) geht davon aus, dass mehrere Variablen in einem Datensatz möglicherweise dasselbe messen, also korreliert sind. Diese verschiedenen Dimensionen können mathematisch zu sogenannten Hauptkomponenten zusammengefügt werden ohne, dass die Aussagekraft des Datensatzes darunter leidet. Dazu werden die Eigenvektoren mit den höchsten Eigenwerten als lineare Kombination von bestehenden Dimensionen verwendet und dadurch die Dimensionalität verringert.
Im Gegensatz zu Autoencoder, ist PCA eine lineare Methode und sollte deshalb nur verwendet werden, wenn die Daten einer linearen Struktur folgen. Autoencoder hingegen können durch die neuronale Netzwerkarchitektur auch nichtlineare Zusammenhänge erlernen und abbilden.
Jedoch ermöglicht die lineare Kombinatorik bei PCA, dass die neuen Dimensionen einfacher zu interpretieren sind und sich meist auch in gewisse Bereiche gliedern lassen. Beim Autoencoder hingegen sind die Dimensionen im Latent Space deutlich schwerer zu interpretieren, da sie sich aus den neuronalen Schichten errechnen, was schnell sehr unübersichtlich werden kann.
Abschließend benötigt die Hauptkomponentenanalyse durch die einfache Methodik deutlich weniger Rechenaufwand, sodass sie bei kleineren Datensätzen schnell und unkompliziert berechnet werden kann. Der Autoencoder ist hierbei schon deutlicher komplexer und das Training kann schnell auch mehrere Minuten oder Stunden in Anspruch nehmen.
t-SNE vs. Autoencoder
Das t-Distributed Stochastic Neighbor Embedding (kurz: t-SNE) basiert auf der Idee, dass man die Dimensionen in einem Datensatz reduzieren kann, indem man eine Wahrscheinlichkeitsverteilung findet, welche die Abstände von Datenpunkte in einem hochdimensionalen Raum möglichst genau im niedrigdimensionalen Raum abbildet. Dadurch soll einfach gesagt gewährleistet werden, dass die Punkte, welche im hochdimensionalen Raum nahe beieinander lagen, also Nachbarn waren, auch im niedrigdimensionalen Raum nahe beieinander liegen.
t-SNE wird dabei vor allem zur Visualisierung von Daten im zwei- oder dreidimensionalen Raum eingesetzt, damit man einen ersten Überblick über die Daten und deren Lage erhält. Die Autoencoder hingegen sind deutlich vielseitiger und können beispielsweise auch zur Feature Extraction oder zur Dimensionsreduktion mit einer frei wählbaren Zahl von Dimensionen genutzt werden.
Sowohl t-SNE als auch Autoencoder können nicht-lineare Zusammenhänge in den Daten erkennen und auch entsprechend im niedrigdimensionalen Raum abbilden. Jedoch ist t-SNE dabei häufig deutlich rechenaufwändiger als Autoencoder und skaliert sehr schlecht bei großen Datensätzen. Die Berechnung ist dabei also häufig langsamer als bei vergleichbaren Autoencodern.
Welche weiterführenden Entwicklungen gibt es in diesem Bereich?
Die Autoencoder sind ein zentraler Bestandteil der Weiterentwicklung von Machine Learning in den letzten Jahren gewesen. Sie haben in vielen Bereichen umfassende Fortschritte gebracht, wobei in diesem Abschnitt vor allem auf die darauf aufbauenden Arbeiten im Bereich der Generativen Modelle und des Transfer Learning eingegangen wird.
Generative Modelle
Durch die Abwandlung von herkömmlichen Autoencodern hin zu Variational Autoencoder (VAE), konnten die Modelle nicht nur eine deterministische Repräsentation der Daten erlernen, sondern vielmehr eine zugrundeliegende Datenverteilung. Durch diese kleine Änderung war es möglich, dass die Autoencoder auch neue Datenpunkte erzeugen, indem sie eine Stichprobe der Datenverteilung erzeugen. Daraus entstanden dann generative Modelle, welche zum Beispiel im Bereich der Bild- und Spracherzeugung genutzt werden, um realistische und variantenreiche Daten zu erstellen, die jedoch komplett künstlich sind.
Außerdem haben sich aus den Autoencoder auch indirekt die sogenannten Generative Adversarial Networks (kurz: GANs) gebildet, welche sich an der Architektur aus zwei gegenüberstehenden Modellen bedient haben. Im Unterschied zum Autoencoder heißen diese Generator und Discriminator und arbeiten nicht zusammen, sondern gegeneinander. Der Generator versucht möglichst realitätsnähe Bilder oder ähnliches zu erzeugen und übergibt diese an den Discriminator. Dieser wiederum versucht herauszufinden, ob es sich bei den Daten um künstliche oder reale Daten handelt. Im Laufe des Trainings ergibt sich aus diesem Gegenspiel, dass der Generator immer besser darin wird, künstliche Daten zu erzeugen, welche sich kaum von der Realität unterscheiden und der Discriminator im Gegenzug immer besser darin wird, diese Fakes zu erkennen.
Transfer Learning
Eine weitere wichtige Entwicklung, welche sich auch getrieben durch Autoencoder ergeben hat, ist das Transfer Learning. Autoencoder werden darauf trainiert, wichtige Merkmale in Datensätzen, wie zum Beispiel Bildern, zu erkennen und diese aus den Eingabedaten zu extrahieren. Daraus ergab sich der Ansatz den Encoderteil des Modells als Feature Extractor für andere Modelle zu verwenden und dabei als Grundlage für weitere Trainingsschritte zu nutzen.
Daraus ergab sich die Methode nicht mehr komplette Modelle von Grund auf zu trainieren, sondern gewisse, vortrainierte Teile zu nutzen und anschließend auf den spezifischen Datensatz anzupassen. Mit dieser Vorgehensweise kann viel Zeit und vor allem Rechenaufwand gespart werden, insbesondere wenn es sich um große und komplexe Datensätze handelt.
Das solltest Du mitnehmen
- Autoencoder sind Machine Learning Modelle, welche aus einem Encoder und einem Decoder bestehen, und zur Dimensionsreduktion oder zur Feature Extraction eingesetzt werden.
- Neben dem Basis-Autoencoder haben sich viele Arten von Autoencodern entwickelt, welche für bestimmte Anwendungsfälle optimiert wurden.
- Beim Training eines Autoencoders sollte darauf geachtet werden, dass man die richtige Architektur der Schichten verwendet, um die Komplexität im Datensatz abbilden zu können und trotzdem das Risiko für Overfitting zu minimieren.
- In Python können Autoencoder mithilfe von TensorFlow und Keras gebaut werden. Dabei können die Schichten individuell definiert werden, um die Schritte zur Datenkompression zu variieren.
- Bei der Dimensionsreduktion zeichnen sich Autoencoder dadurch aus, dass sie im Vergleich zu PCA auch nichtlineare Abhängigkeiten abbilden können und meist recheneffizienter sind als beispielsweise t-SNE.
- Autoencoder haben einen entscheidenden Grundstein in der Entwicklung von Machine Learning Modellen gelegt, da sich daraus indirekt Generative Modelle und das Transfer Learning gebildet haben.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.

Was ist die Singular Value Decomposition?
Erkenntnisse und Muster freilegen: Lernen Sie die Leistungsfähigkeit der Singular Value Decomposition (SVD) in der Datenanalyse kennen.

Was ist die Poisson Regression?
Lernen Sie die Poisson-Regression kennen, ein statistisches Modell für die Analyse von Zähldaten, inkl. einem Beispiel in Python.

Was ist blockchain-based AI?
Entdecken Sie das Potenzial der blockchain-based AI in diesem aufschlussreichen Artikel über Künstliche Intelligenz und Blockchain.
Andere Beiträge zum Thema Autoencoder
TensorFlow hat einen interessanten und detaillierten Artikel zu diesem Thema, den Du hier finden kannst.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.