Model Selection ist ein entscheidender Schritt beim Aufbau eines erfolgreichen Machine Learning-Modells. Angesichts der Vielzahl von Algorithmen und Techniken, die zur Verfügung stehen, kann die Auswahl des besten Modells entmutigend sein. Dieser Artikel gibt einen Überblick über die Modelauswahl, einschließlich der Bedeutung des Prozesses, der Standardverfahren und der Faktoren, die bei der Auswahl eines Modells zu berücksichtigen sind.
Welche verschiedenen Modelle stehen zur Auswahl?
Bei der Modelauswahl gibt es verschiedene Arten von Modellen, die in Betracht gezogen werden können. Hier sind einige der am häufigsten verwendeten Modelle:
- Lineare Modelle: Diese Modelle verwenden lineare Beziehungen zwischen den Eingangsvariablen und den Ausgangsvariablen. Beispiele hierfür sind die lineare Regression und logistische Regression.
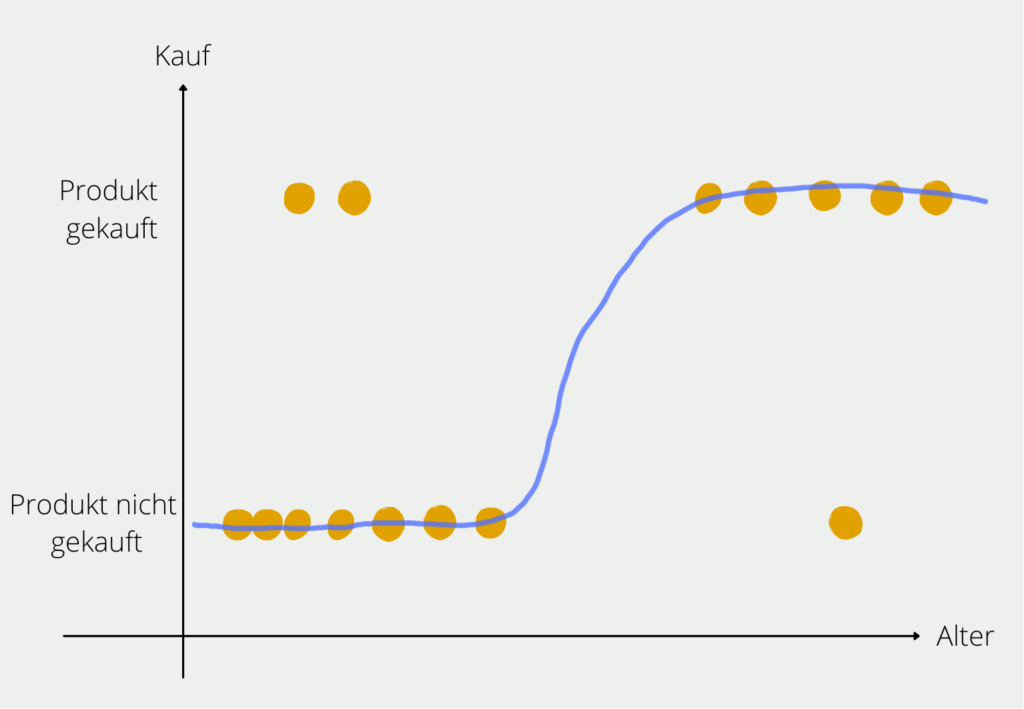
- Baummodelle: Diese Modelle partitionieren die Daten rekursiv in Untergruppen, um Vorhersagen mithilfe von Entscheidungsbäumen zu treffen. Beispiele hierfür sind Entscheidungsbäume, Random Forests und Gradient Boosting Machines.
- Support-Vektor-Maschinen (SVM): Diese Modelle verwenden eine Hyperebene, um die Daten in verschiedene Klassen zu trennen. SVMs funktionieren gut in hochdimensionalen Räumen und werden häufig bei Klassifikationsaufgaben verwendet.
- Neuronale Netzwerke: Diese Modelle sind darauf ausgelegt, die Struktur und Funktion des menschlichen Gehirns nachzuahmen. Sie verwenden Schichten von miteinander verbundenen Knoten, um Merkmale aus den Daten zu extrahieren. Beispiele hierfür sind Feedforward-Neuronale Netzwerke, Convolutional Neural Networks (CNNs) und Rekurrente Neuronale Netzwerke (RNNs).
- Bayes’sche Modelle: Diese Modelle verwenden das Bayes’sche Theorem, um Wahrscheinlichkeiten zu aktualisieren, während mehr Daten gesammelt werden. Sie eignen sich gut zur Vorhersage von Ergebnissen und zur Abschätzung von Unsicherheit.
- k-nearest neighbor (KNN): Dieses Modell verwendet den Abstand zwischen Datenpunkten, um neue Datenpunkte zu klassifizieren.
Jedes Modell hat seine eigenen Stärken und Schwächen, und die Wahl des Modells hängt vom konkreten Problem und der Art der Daten ab.
Welche Methoden gibt es zur Model Selection?
Die Model Selection ist ein entscheidender Schritt in der Machine-Learning-Pipeline, um das beste Modell für ein bestimmtes Problem auszuwählen. Es gibt verschiedene Methoden zur Modelauswahl, von denen jede ihre Vor- und Nachteile hat.
- Grid Search: Diese Methode umfasst das Testen aller möglichen Kombinationen von Hyperparametern in einem vordefinierten Bereich und die Bewertung jedes Modells mithilfe der Kreuzvalidierung. Grid Search ist einfach umzusetzen, kann jedoch rechenintensiv sein, insbesondere bei großen Datensätzen oder Modellen mit vielen Hyperparametern.
- Random Search: Bei der Random Search werden die Hyperparameterräume zufällig abgetastet, und jedes Modell wird mithilfe der Cross Validation bewertet. Sie ist rechnerisch weniger aufwendig als die Grid Search und kann bessere Ergebnisse liefern, wenn einige Hyperparameter wichtiger sind als andere.
- Bayesian Optimization: Die Bayesianische Optimierung verwendet ein probabilistisches Modell, um die Leistung verschiedener Hyperparameter vorherzusagen und die Suche in den vielversprechendsten Bereichen des Hyperparameterraums zu lenken. Sie ist rechnerisch effizient und kann viele Hyperparameter handhaben, erfordert jedoch mehr Einrichtung als eine Grid- oder Random Search.
- Ensemble-Methoden: Ensemble-Methoden kombinieren die Vorhersagen mehrerer Modelle, um die Gesamtleistung zu verbessern. Beispiele hierfür sind Bagging, Boosting und Stacking. Ensemble-Methoden können rechenintensiv sein und erfordern mehr Daten als ein einzelnes Modell, führen aber oft zu besseren Ergebnissen.
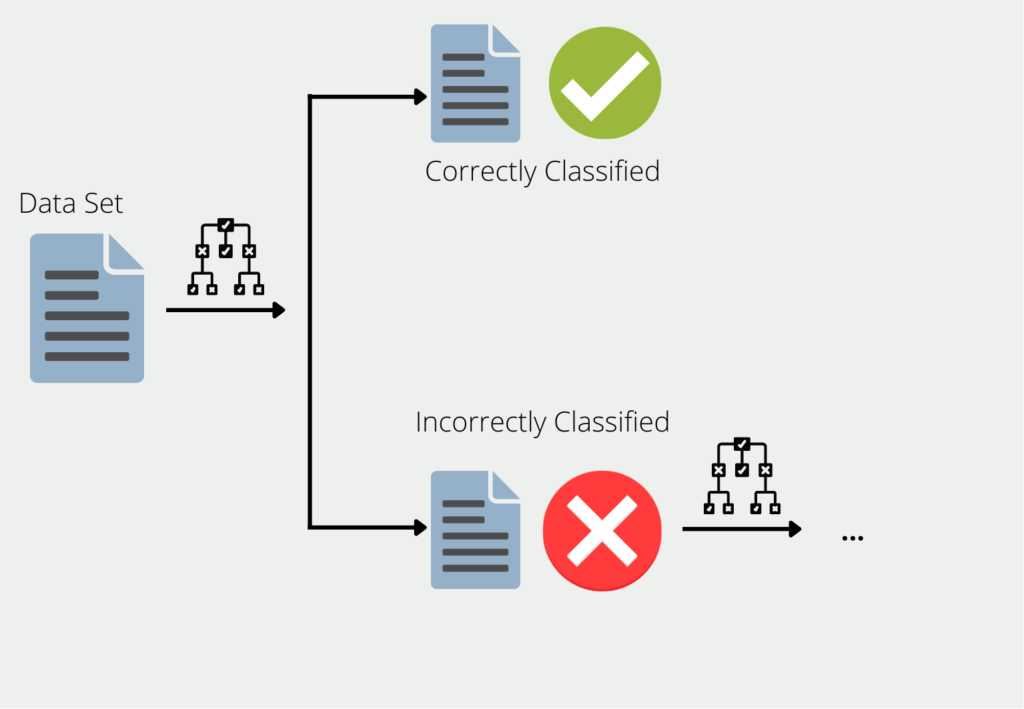
- Automated Machine Learning (AutoML): AutoML ist ein automatisierter Ansatz zur Model Selection, der maschinelle Lernalgorithmen verwendet, um das beste Modell und die besten Hyperparameter zu suchen. Es ist ein zunehmend beliebter Ansatz, da er Zeit und Ressourcen sparen kann. Allerdings kann er durch die verfügbare Rechenleistung begrenzt sein und führt möglicherweise nicht immer zu den besten Ergebnissen.
Insgesamt hängt die Wahl der Methode zur Modelauswahl vom konkreten Problem, den verfügbaren Ressourcen und den spezifischen Anforderungen des Modells ab.
Was sind die Vor- und Nachteile der Model Selection?
Die Modelauswahl ist ein entscheidender Schritt in der Machine-Learning-Pipeline, bei dem das beste Modell aus einer Gruppe von Kandidatenmodellen für die Lösung eines bestimmten Problems ausgewählt wird. Die Modelauswahl bietet mehrere Vor- und Nachteile.
Einer der Hauptvorteile der Model Selection besteht darin, dass sie bei der Suche nach dem optimalen Modell für ein bestimmtes Problem hilft, indem sie mehrere Modelle berücksichtigt. Der Prozess der Auswahl des besten Modells für ein bestimmtes Problem verbessert die Leistung des Modells und erhöht die Genauigkeit der Vorhersagen. Die Modelauswahl stellt auch sicher, dass das Modell robust ist und auf neuen und unbekannten Daten gut abschneiden kann. Durch die Auswahl des besten Modells können auch Probleme mit Überanpassung (Overfitting) und Unteranpassung (Underfitting) vermieden werden, die auftreten können, wenn das Modell zu komplex oder zu einfach ist.
Die Model Selection hat jedoch auch einige Nachteile. Einer der Hauptnachteile besteht darin, dass sie ein zeitaufwändiger Prozess ist, der eine beträchtliche Menge an Ressourcen und Fachwissen erfordert. Die Auswahl des besten Modells aus einer großen Anzahl von Kandidaten kann eine Herausforderung sein und kann mehrere Iterationen und Experimente erfordern, um die optimale Lösung zu finden. Die Modelauswahl kann auch fehleranfällig sein, da verschiedene Modelle sich möglicherweise unterschiedlich auf verschiedenen Datensätzen oder unter verschiedenen Bedingungen verhalten.
Eine weitere Herausforderung bei der Modelauswahl besteht im Kompromiss zwischen Modellkomplexität und Modellleistung. Ein komplexeres Modell kann eine bessere Leistung auf den Trainingsdaten erzielen, generalisiert jedoch möglicherweise nicht gut auf neue Daten, was zu Überanpassung führt. Auf der anderen Seite kann ein einfacheres Modell möglicherweise nicht alle Feinheiten der Daten erfassen und unterangepasst sein, was zu schlechter Leistung führt. Daher besteht die Aufgabe bei der Auswahl des optimalen Modells darin, das richtige Gleichgewicht zwischen Modellkomplexität und Modellleistung zu finden.
Zusammenfassend ist die Model Selection ein wichtiger Schritt im Machine-Learning-Prozess, bei dem das beste Modell aus einer Gruppe von Kandidatenmodellen für ein bestimmtes Problem ausgewählt wird. Obwohl sie mehrere Vorteile wie Verbesserung der Modellleistung und Vermeidung von Über- und Unteranpassung bietet, hat sie auch einige Nachteile wie Zeit- und Ressourcenaufwand und die Möglichkeit, das falsche Modell auszuwählen.
Welche Strategien gibt es für den Vergleich von Modellen?
Strategien zum Vergleich von Modellen sind entscheidend, um das am besten geeignete Modell für ein bestimmtes Problem auszuwählen. Hier sind einige gängige Strategien zum Vergleich von Modellen:
- Residuenanalyse: Bei dieser Strategie untersuchen wir den Unterschied zwischen den vorhergesagten und tatsächlichen Werten der Zielvariablen. Modelle mit geringeren Residuen werden bevorzugt, da sie besser passen.
- Cross Validation: Kreuzvalidierung ist eine weit verbreitete Technik zur Modellauswahl. Bei dieser Methode wird der Datensatz in Trainings- und Testsets aufgeteilt, und das Modell wird auf dem Trainingsset trainiert. Die Leistung des Modells wird dann auf dem Testset bewertet. Das Modell mit der besten Leistung auf dem Testset wird ausgewählt.
- Informationskriterien: Informationskriterien wie das Akaike-Informationskriterium (AIC) und das Bayes-Informationskriterium (BIC) bieten eine quantitative Messung der Qualität des Modells. Geringere Werte von AIC und BIC deuten auf ein besseres Modell hin.
- Hypothesentests: Hypothesentests können ebenfalls zur Modellauswahl verwendet werden. Wir können den F-Score oder den p-Wert von zwei oder mehr Modellen vergleichen, um das beste Modell auszuwählen.
- Fachkenntnisse: Manchmal kann Fachkenntnis bei der Auswahl des am besten geeigneten Modells helfen. Wenn wir beispielsweise wissen, dass die Beziehung zwischen den Variablen linear ist, können wir ein lineares Modell wählen.
Insgesamt ist es wichtig, eine Kombination dieser Strategien zu verwenden, um das am besten geeignete Modell für ein bestimmtes Problem auszuwählen.
Was ist der Kompromiss zwischen Modellkomplexität und Modellleistung?
Der Kompromiss zwischen Modellkomplexität und Modellleistung ist ein wichtiger Aspekt der Model Selection. Im Allgemeinen können komplexere Modelle die Daten besser anpassen, aber sie können auch unter Überanpassung leiden, bei der sie zu stark auf die spezifischen Merkmale des Trainingsdatensatzes eingehen und nicht gut auf neuen Daten generalisieren. Einfachere Modelle hingegen können unter Unteranpassung leiden, bei dem sie die Feinheiten der Daten nicht gut erfassen und eine niedrigere Leistung aufweisen.
Ein komplexes Modell hat eine größere Kapazität, um eine Vielzahl von Mustern und Zusammenhängen in den Daten zu erfassen. Es kann eine präzisere Anpassung an den Trainingsdatensatz ermöglichen und eine geringere Fehlerrate aufweisen. Jedoch kann dies zu einer schlechteren Leistung auf neuen Daten führen, da das Modell möglicherweise zu stark auf spezifische Rauschanteile oder Ausreißer im Trainingsdatensatz reagiert.
Ein einfacheres Modell hat eine geringere Kapazität und eine einfachere Struktur. Es kann robuster gegenüber Rauschen und Ausreißern sein und möglicherweise besser auf neuen Daten generalisieren. Es kann jedoch auch bestimmte Muster und Zusammenhänge in den Daten nicht gut erfassen, was zu einer höheren Fehlerrate führen kann.
Der Kompromiss zwischen Modellkomplexität und Modellleistung besteht darin, das richtige Gleichgewicht zu finden, bei dem das Modell ausreichend komplex ist, um die relevanten Merkmale der Daten zu erfassen, aber nicht zu komplex, um übermäßig auf spezifische Eigenschaften des Trainingsdatensatzes zu reagieren. Eine Möglichkeit, den Kompromiss zu finden, besteht darin, regulierende Techniken wie Regularisierung oder Kreuzvalidierung zu verwenden, um die Modellkomplexität zu kontrollieren und die Leistung auf neuen Daten zu verbessern.
Insgesamt ist der Kompromiss zwischen Modellkomplexität und Modellleistung ein wichtiges Konzept bei der Modellauswahl und erfordert die Berücksichtigung von Faktoren wie Datenverfügbarkeit, Modellkapazität und Generalisierungsfähigkeit.
Das solltest Du mitnehmen
- Die Model Selection ist ein wichtiger Schritt in der Pipeline des maschinellen Lernens, der bei der Auswahl des besten Modells für die jeweilige Aufgabe hilft.
- Es gibt verschiedene Modelle für maschinelles Lernen, darunter Entscheidungsbäume, Random Forests, SVMs und neuronale Netze.
- Für die Model Selection werden verschiedene Methoden verwendet, z. B. Holdout, Kreuzvalidierung und Bootstrap.
- Zu den Strategien für den Vergleich von Modellen gehören der Vergleich ihrer Leistung in der Validierungsmenge, die Komplexität der Modelle und die Interpretierbarkeit der Modelle.
- Die Abstimmung von Hyperparametern ist ein wesentlicher Schritt bei der Model Selection, der zur Optimierung der Modellleistung beiträgt.
- Die Model Selection beinhaltet einen Kompromiss zwischen Modellkomplexität und Modellleistung.
- Zu den Vorteilen der Model Selection gehören eine verbesserte Modellleistung, eine geringere Überanpassung und eine bessere Interpretierbarkeit der Modelle.
- Zu den Nachteilen der Model Selection gehören ein erhöhter Rechenaufwand, die Möglichkeit, das falsche Modell auszuwählen, und das Potenzial für eine Überanpassung.

Was ist die Random Search?
Optimieren Sie Modelle für maschinelles Lernen: Lernen Sie, wie die Random Search Hyperparameter effektiv abstimmt.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.
Andere Beiträge zum Thema Model Selection
Einen ausführlichen Artikel zur Modellauswahl in Scikit-Learn findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.